目前,显卡分为两种类型,一种是专为游戏设计的,另一种是用于其他更高价值应用的。 也就是说,用于科学和军事模拟等等。 然而,有一个单位从第一张成功的 3D 卡开始就一直伴随着我们, 栅格单位,可能会消失 以及未来 GPU 的组织或架构。 后果? 仅用于游戏的模型与用于其他领域的模型之间的分离结束。
今天的实时 3D 游戏占游戏的 99%,但由于当时流行的 Voodoo Graphics 以及拥有负责通用功能的芯片这一事实,它们才出现在计算机上。 我们谈论的是光栅单元,它现在存在于所有图形芯片中,但会随着时间的推移而消失。 这会对未来的硬件产生什么影响?

GPU 正在发生变化
GPU 是专门的图形处理器,具有一定的通用工作能力。 这是因为他们的核心早就不再是专门用来做一般任务的了。 因此,当今世界上许多伟大的超级计算机都将它们用于大规模科学和军事模拟,以及人工智能等其他蓬勃发展的应用。
然而,仍然有一系列执行特定任务的单元,但它们是生成图形所必需的。 他们的工作不仅是将主要原子核从它们中释放出来,而且是并行工作。 它的最大优势在于,通过执行固定或特定任务,它们需要更少的晶体管来构建,因此,与让主核处理任务相比,成本更低,消耗更少。
然而,一个专门的硬件可能会变得过时,要么是因为它跟不上其他项目的性能进步,要么是因为它的工作方式不太理想。 那么,我们发现在显卡的主芯片中出现了一种特定类型的单元,另一种类型正在消失。

告别光栅单位
如果您查看任何显卡的规格,您会发现越来越不重要的是谈论“每秒三角形数”的规格。 许多人认为屏幕上显示的是这些的数量,而其他人会认为它们是计算出来的数量。 两者都是错误的,因为这取决于我们正在运行的应用程序。 此外,它是一个固定速率,如果我们注意到它始终是光栅单元数量的时钟速度。 至少今天。
这些单元在性能上取得了进步,从需要几个时钟周期来光栅化一个三角形,到现在的速度,但它们已经十年没有发展了。 他的工作? 将以顶点计算的 3D 世界投影到由像素组成的 2D 表面,屏幕,稍后将计算颜色。 因此,它是一个必不可少的单位,因为当我们制作 3D 场景时,每个三角形最终都会变成像素; 然而,该单位可能很快就会说再见。
原因? 你的局限性
栅格单位的问题是它们不是为处理非常小的三角形而设计的,也就是说,那些以几个像素栅格化的三角形。 此外,当一个对象仅由几个像素组成时,光栅化器所做的是断定它距离太远并将其标记为删除。 当然,在使用深度缓冲区检查它到相机的距离之前将其从场景中消除,并且不必计算它。 这也适用于较大对象后面的对象,当最前面的对象在某种程度上透明时会导致问题。 这会导致问题,但这完全是另一回事。
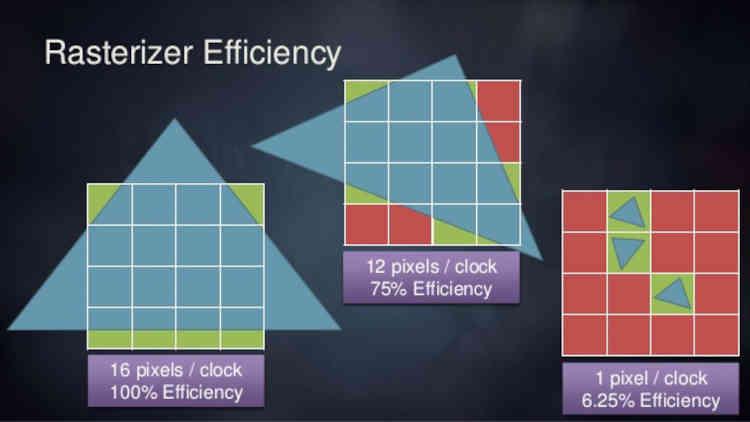
问题? 我们正在进入这样一个世界,在这个世界中,几何被极端地用于细化人物、物体和场景。 这意味着当前光栅单元无法支持的三角率。 这是一个瓶颈,但问题是它们不能很好地处理小三角形。 从某种意义上说,如果我们有 100 个 50 像素的三角形,这不会转化为 200 个 25 像素的三角形。 因此,它的效率会随着它所处理的多边形变小而降低。
解决办法是什么?
如此之多,以至于面对虚幻引擎 5 的创建,Epic Games 的人员不得不使用计算机着色器为其创建光栅单元。 那就是 GPU 核心更好地完成专业功能单元的工作。 这危及它的未来。 目前还没有排除,但是,它上面已经有了达摩克利斯之剑,还有镶嵌或表面细分单元。
 在 2020 年 XNUMX 月对 Brian Karis 的采访中 ,图形程序员表示,他们已经为虚幻引擎 5 开发了两种软件三角形光栅化器。这是假设 Epic 的新引擎,将被业界数十款游戏使用,已经具备免除光栅单元的能力。 也就是说,更换其中一个 GPU 核心以更换这些单元中的每一个并获得更高的性能。
在 2020 年 XNUMX 月对 Brian Karis 的采访中 ,图形程序员表示,他们已经为虚幻引擎 5 开发了两种软件三角形光栅化器。这是假设 Epic 的新引擎,将被业界数十款游戏使用,已经具备免除光栅单元的能力。 也就是说,更换其中一个 GPU 核心以更换这些单元中的每一个并获得更高的性能。
绝大多数三角形是由使用高度专业化的计算机着色器的软件光栅化的,这些着色器旨在利用我们可以从中受益的东西。 因此,我们已经能够在这项特定任务中将硬件光栅器抛在脑后。 软件光栅化是 Nanite 的一个主要元素,它允许我们做它所做的事情。 我们无法在所有情况下都击败硬件光栅化器,因此当我们确定它是最快的路径时,我们将使用它们。
白色,装在瓶子里,如您所见。 它们会消失,因为它们是晶体管 NVIDIA公司, 英特尔 和 AMD公司 可以利用其他将来会变得更重要的事情。
为什么显卡的组织会发生变化?
如果您查看任何 GPU 的图表,您会发现核心围绕光栅器排列成块。 这是因为它们将数据发送到这些单元并接收它们,具体取决于我们正在谈论的 3D 管道的哪个阶段。 所以删除它是一种重组。 目前,光栅单元 100% 效率的理想尺寸对于 NVIDIA 是 48 像素,对于 AMD 是 64 像素。 这也限制了专为游戏设计的模型中的内核数量。 就绿色品牌而言,可以通过比较其用于高性能计算和游戏的芯片来看出这一点。

可以看出,H100 GPC 没有Raster Engine,这使得它没有这样固定的组织,因此受到限制。 这一变化将使 NVIDIA 和 AMD 不必为 HPC 和游戏设计两种不同的设计,而是能够在设计方面从通用基础模型中提取。 您可以从中迭代。 今天,无论我们谈论的是中央处理器还是图形处理器,我们发现相互通信占整个芯片的 2/3 到 3/4,而且必须在两个不同的芯片上工作这一事实令人望而生畏。
我们不要忘记每个新节点都是更多的晶体管,这是更多的零件和更多的工程师要雇用。 它将达到为科学工作提供的相同图形卡将成为游戏的高端的地步,因为制造两种不同的模型将无利可图,并且消除光栅单元将是关键在这整个开发过程中。 统一。