购买时 中央处理器 或者 GPU 我们找到了技术规范,例如时钟速度,浮点运算的数量,内存带宽等。但是,衡量性能和设计处理器的方法之一与指令的延迟有关。 我们将说明它是什么以及为什么获得更快的CPU如此重要。
一个处理器相对于另一个处理器的性能是通过解决同一程序所花费的时间来衡量的。 这可以通过许多不同的方式来实现,并且有不同的方式可以提高性能,从而减少运行时间。 其中之一是减少执行指令的等待时间。 但是它到底由什么组成呢?

指令延迟是什么意思?
延迟是处理器执行一条指令所花费的时间,它是数据所在位置的变量,因为延迟时间越长,将这些数据放入相应的寄存器所花费的时间就越长。 正是由于这个原因,并且由于存储器的扩展速度与处理器不同,因此必须创建诸如高速缓存之类的机制,甚至将存储器控制器集成到处理器中以减少指令的等待时间。
但是,在出售CPU甚至GPU时通常不会考虑到这一点,通常使用其他性能指标来说明一种体系结构优于另一种体系结构。 但是,当提升处理器是理解性能的另一种方式时,通常不会在提升处理器时使用指令的等待时间。
每条指令的时钟周期和延迟

性能的第一个衡量标准是每条指令的周期,因为有些指令足够复杂,必须在几个不同的指令周期中执行。 在设计新处理器时,很多时候,无论我们谈论的是CPU,GPU还是任何其他类型的处理器,架构师通常都会在解决关于具有相同ISA的先前处理器的指令的方式上进行更改。
指令的形式永远不会改变,但是要做的是减少加扰它所需的时钟周期数。 例如,我们可以让一条指令负责计算两个数字之间的平均值,这两个数字在具有相同ISA的处理器中需要4个时钟周期,并且比相同指令的以前版本需要20个周期提高5%。
这个想法无非是为了减少一部分指令所花费的时间,以减少执行程序所花费的时间。 这样,在指令中以很小的加速度就可以实现整体性能的提高。
缓存和指令延迟

高速缓存存储器存储以下内容的副本: 内存 此时在其上执行指令的存储器,这允许处理器访问存储器而不必访问RAM,并且由于高速缓存更靠近CPU的单元,因此该存储器最终能够执行该指令由于捕获指令所需的时间更少,因此可以在更短的时间内完成。
我们谈论的是不同的缓存级别这一事实并不意味着所有的第一级,第二级甚至第三级缓存都具有相同的距离,因此延迟也相同,而是它们在一个体系结构与另一体系结构之间有所不同。 例如,在当前 英特尔 以Intel为核心,缓存的延迟时间低于竞争对手的同类产品, AMD公司的AMD Zen。
为了将体系结构从一个版本改进到另一个版本,通常提出的更改之一是减少相对于缓存的延迟。 尤其是由于处理器尺寸的减小以及单元与缓存之间的距离的减少,将相同的架构从一个节点移植到另一个节点时。
小芯片和潜伏困境

小芯片的想法就是为了相同的功能使用多个芯片而不是一个芯片,因此,这增加了不同部分之间的通信距离,从而增加了等待时间。 与处理器的单片版本相比,这会导致性能损失。
对于AMD Ryzen(这是最著名的情况),减少基于小芯片的版本与单芯片处理器的版本之间差异的一种方法是在几秒钟内减少最后一级的缓存。 原因? 如果它们具有相同数量的高速缓存,那么仅由于与存储控制器的距离而导致的通过小芯片的版本将在指令中具有较低的延迟,并具有较高的性能。
指令延迟是3DIC的关键

在三个维度上集成的芯片是另一个关键点,尤其是那些将内存堆叠在处理器上的芯片。 这样做的原因是,它们将内存放置在离处理器非常近的地方,仅此一项就可以提高性能。 这种情况的折衷是内存和处理器之间的热阻塞,这会迫使时钟速度下降,并且在某些设计中,可能会出现分别放置处理器和内存比3DIC设计更高的时钟速度的情况。
如果内存距离处理器足够近,则可能会产生奇怪的效果,即访问嵌入式内存中的数据所花的时间要比逐一遍历体系结构的不同缓存级别所花费的时间更少。 这完全改变了处理器的设计方式,因为当要处理的数据相距太远时,缓存是一种减少延迟的方法。
距离和消耗有关
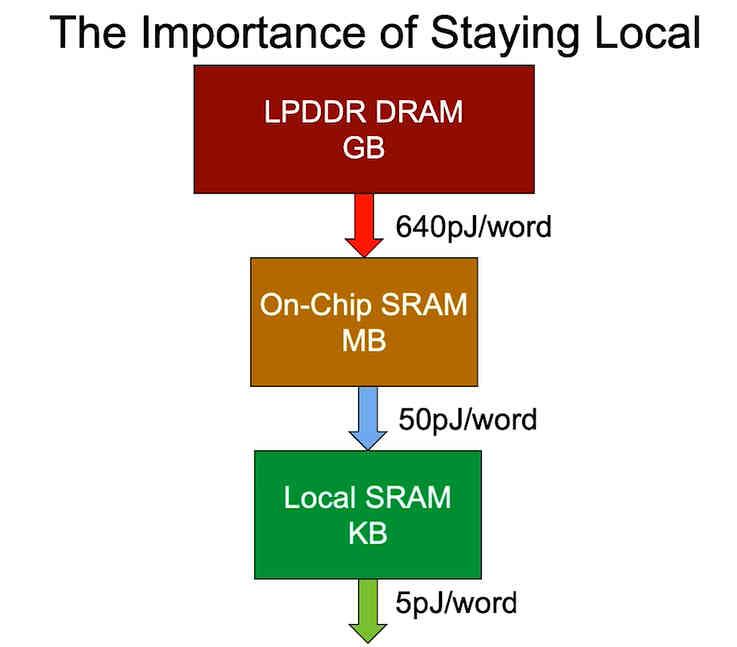
最后一点是能耗,这取决于数据所在的位置。 这就是为什么在处理器消耗方面设计更优化的版本时,要寻求的是缩短数据所在的距离,因为处理器的能耗会随着距离的增加而增加,而不是找到数据。只是等待时间,不幸的是,我们无法容纳在芯片空间内运行程序所需的大量数据。
在当今世界,由于气候变化而导致的能源消耗已成为最重要的问题之一,而便携性和低消耗是他们的卖点,因此在许多产品中都具有价值。减少指令的等待时间,这对于提高每瓦性能变得尤为重要。
