基于芯片的GPU已经存在了很长一段时间,尤其是由于这两个问题之一 NVIDIA公司 和 AMD公司 近年来面临的挑战是将其GPU扩展到物理限制之外。 。 他们会是什么样子,这种设计GPU的新方式的动机是什么?
如果我们观察一下AMD,尤其是NVIDIA最近推出的GPU,我们会发现它们所占的面积正在增加,如果几年前 GPU 大于400平方毫米的空间被认为是很大的东西,现在我们将其超过2平方毫米。

这种趋势意味着存在在某一时刻达到网格极限的危险,该极限是芯片在给定的制造节点中可能以危险的方式拥有的极限区域,如果我们不加选择地将其变得复杂增加组成GPU的核心数量。
车站和火车的明喻

假设我们有一个铁路网络,其中有几个火车站,每个火车站都是一个处理器,火车就是发送的数据包。
显然,如果我们的铁路网络包括越来越多的车站,那么我们将需要越来越多的轨道和更复杂的基础设施。 好吧,在处理器的情况下,这是相同的,因为增加元素数量意味着增加不同元素之间的通信通道数量。
问题在于,这些额外的火车轨道也将增加能耗,因此,专门设计铁路网络的人不仅必须考虑可在基础设施中放置多少条轨道,而且还必须考虑其能耗。
摩尔定律的扩展范围不如您想象的大
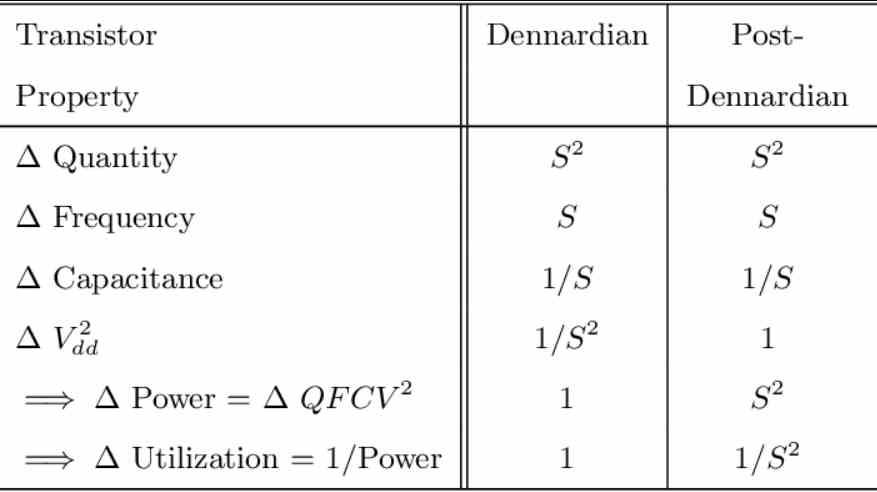
根据摩尔定律,每x倍,每单位面积的晶体管数量密度每隔一倍就会增加一倍,这与Dennard标度相伴随,该标度告诉我们在每个新的制造节点上它们可以按何种时钟速度进行标度。 最初的Dennard比例从65 nm节点开始更改其度量。
当我们增加元素/火车和通信路线的数量时,问题就来了,我们可以放置两倍的元素,但是我们不能做的是确保我们有必要的带宽在相同的消耗下同时通信所有这些元素。 给定,这是不可能的,并且这限制了内核的数量,而对于GPU,则是计算单元的数量。

一直采取的解决方案? 除了增加元素之外,没有做的就是使这些元素变得越来越复杂,例如,对于GPU,这是NVIDIA从Turing那里走的路,而不是与Pascal相比增加了SM的数量。 他所做的是添加了诸如RT Cores,Tensor Cores之类的元素,并对单元进行了深刻的改变,因为增加Cores的数量意味着增加互连的数量。
因此,我们发现自己面临数据传输/火车的能源成本问题,每个新的制造节点都可以增加芯片上的元件数量,但是我们发现所需的传输速度越来越高,从而增加了能耗,我们提供给处理器的大部分能源越来越多地用于数据传输,而不是数据处理。
使用已知芯片中的小芯片构建GPU
通过小芯片构造GPU的想法是,能够构建不能由单片构造制造的GPU,因此,该芯片必须基于单个芯片,因此使用小芯片构造的GPU的面积必须大于将小芯片构造的GPU的面积。允许标线的限制,因为那样的话,这种类型的GPU将毫无意义。
这意味着,由小芯片组成的GPU将专门为最大范围保留,并且有可能最初我们只会在高性能计算GPU(高性能计算)的GPU市场中看到它们,而在家庭中,我们还有几年的时间使用GPU的配置要简单得多,因此是单片的。
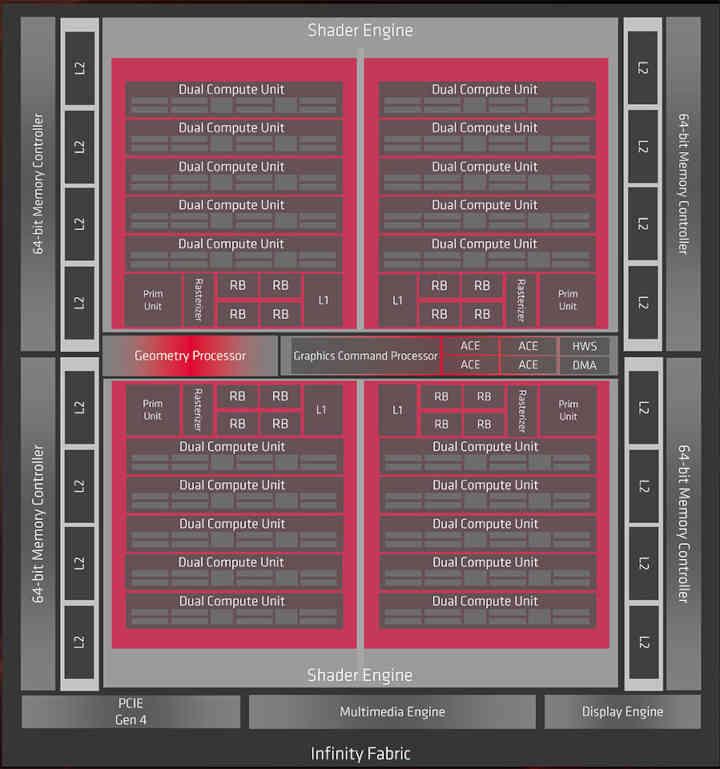
但是,我们决定采用Navi 10芯片(以第一代RDNA架构为例)对其进行解构并创建由小芯片组成的GPU,主要是因为它是我们拥有最多数据的最新一代GPU。表。 与该示例相比,AMD和/或NVIDIA构建的GPU的复杂性要高得多,这仅是示意性的,因此您可以对如何构建这种类型的GPU有所了解。
第一个想法是每个小芯片都是一个着色器阵列,它们是粉盒上与L1高速缓存相连的元素集,而我们将把L2高速缓存放在单独的中央芯片中。
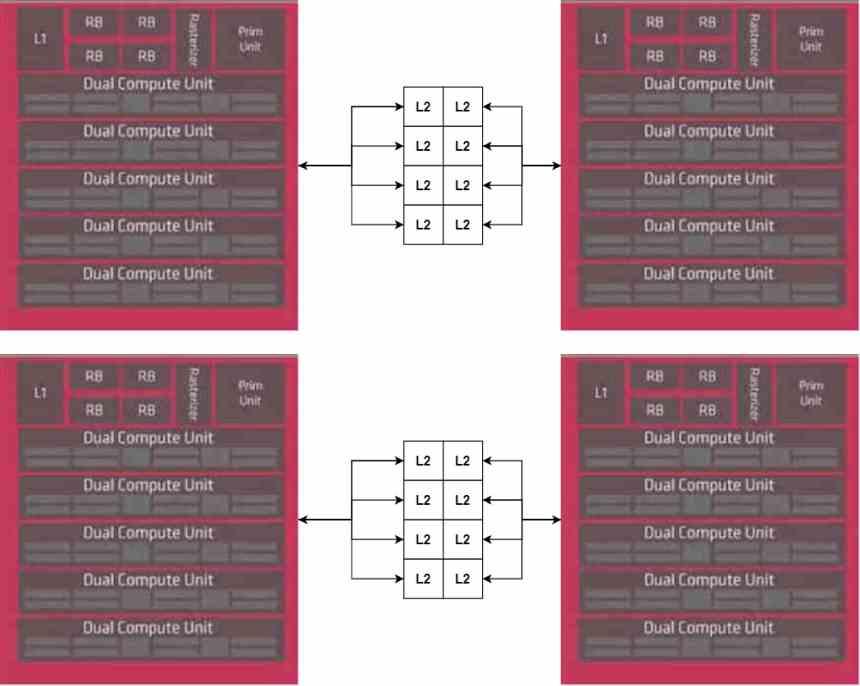
但是我们没有完整的GPU,因为我们缺少它的中央部分,即命令处理器,它是一个单独的部分,我们将不会复制,因此我们将其放置在MCM的中央部分。
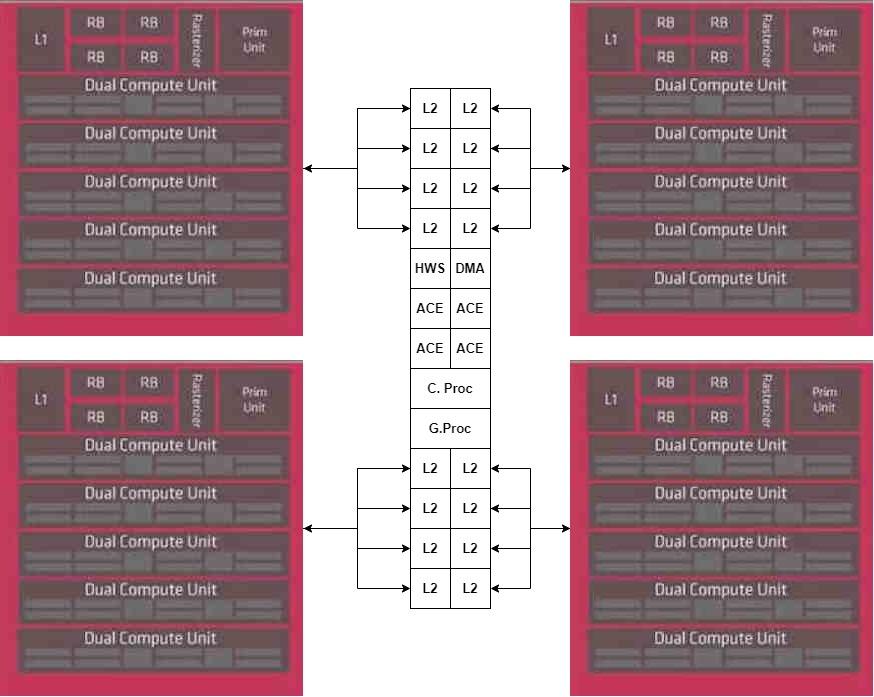
至于加速器,我们将它们放置在另一个小芯片中,直接连接到中央小芯片的DMA单元。
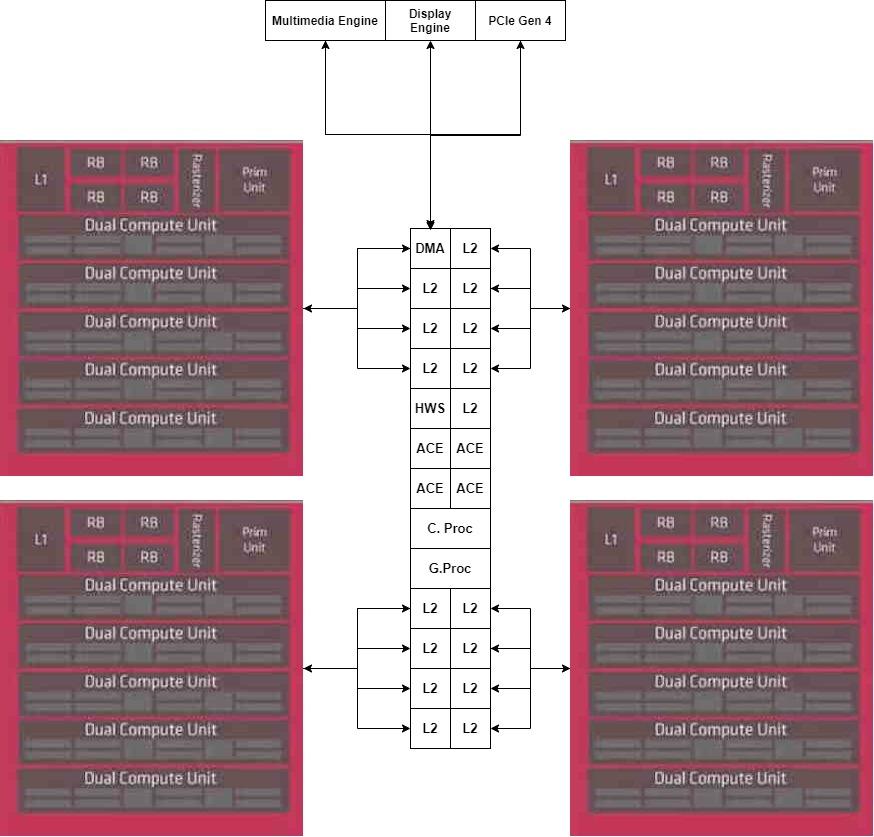
一旦我们将GPU分解为几个部分,我们现在感兴趣的是与外部内存的通信,这将由内插器完成,该内插器将内部集成了内存控制器。 由于Navi 10使用256位8芯片GDDR6接口,因此我们决定在示例中保留该配置。
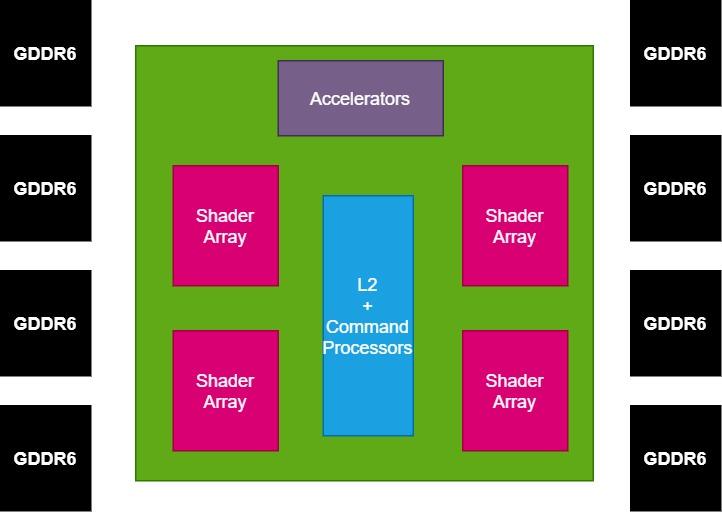
基于小芯片和功耗的GPU
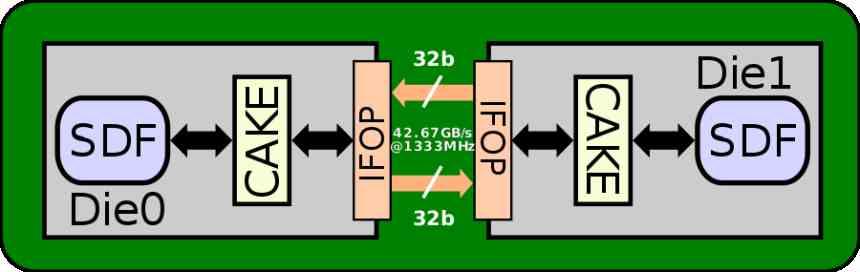
用于通信不同小芯片元素的接口是AMD MCM,即IFOP接口,其能耗为2 pJ /位,如果我们查看技术规格,我们将看到L2缓存的带宽为1.95 TB /它的速度为1905 MHz,约为1024字节,适用于16个接口,每个地址64字节/周期,32B /周期。
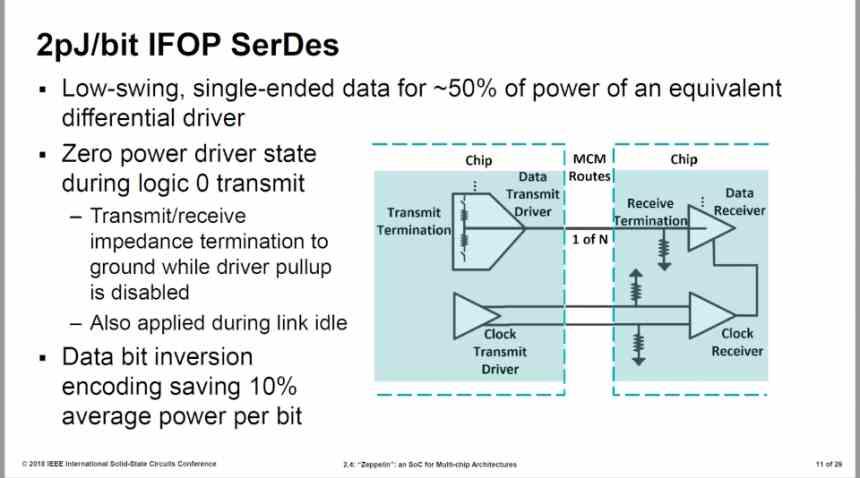
Infinity Fabric的第一个版本使用了32B /周期的接口,消耗了2 pJ /位,但是AMD提高了27%
IFOP接口的能量消耗为1.47 pJ /位,速度为1333 MHz。 如果接口的频率为1905 MHz,则能量消耗将更高,因为它不仅会提高时钟速度,而且会提高电压,而且假设Navi 10的小芯片版本以1333 MHz的速度运行。
(1.33 * 10 ^ 12)*每字节8位*每位1.47 pJ = 1.56 * 10 ^ 13 pJ = 15.6 W
尽管15.6 W对我们来说似乎是个小数字,但请记住,这仅是消耗以中央小芯片传输速度为1333 MHz的外围小芯片的数据的消耗,并且能耗随时钟速度成倍增加。 电压也随之增加。
这意味着功耗的很大一部分直接与小芯片之间的通信功耗有关,这意味着AMD和NVIDIA必须在部署基于小芯片的GPU之前解决此问题。
AMD的EHP作为基于小芯片的GPU的示例
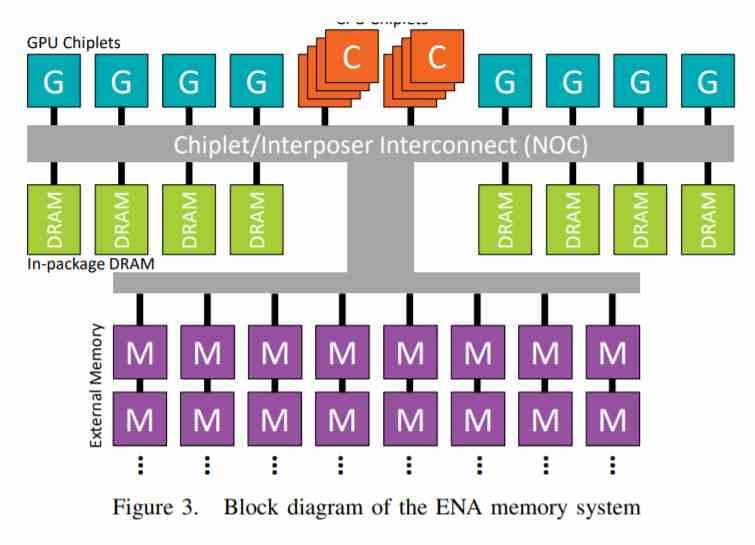
几年前,AMD发表了一篇论文,其中描述了一个具有极其复杂的GPU的基于小芯片的处理器,他们讨论了例如320个小芯片中8个计算单元的配置,即每个小芯片相当于40个计算单元,相当于到完整的Navi 10。
换句话说,我们正在谈论的配置要复杂8倍,因此,想象一下一个配置有8个小芯片的配置,每个小芯片都像Navi 10 / RDNA一样,并且以高于2 GHz的速度运行且具有巨大的能耗。

这就是AMD和NVIDIA开发诸如X3D和GRS之类的技术的原因,这些技术的通信接口的每传输位能耗比当前的Infinity Fabric或NVLink低10倍,因为它没有那种通信接口基于芯片的GPU的未来是不可能的。
