Rất nhiều điều đã thay đổi về kiến trúc of NVIDIA GPU trong hai thập kỷ qua, nhưng một bước ngoặt quan trọng là khi những người có màu xanh lá cây ra mắt kiến trúc Tesla, trở lại vào năm 2006. Trong bài viết này, chúng ta sẽ xem lại để xem kiến trúc NVIDIA đã phát triển như thế nào từ Tesla đến Turing , kiến trúc hiện tại (trong trường hợp không có sự xuất hiện của Ampere), và cụ thể hơn là nó như thế nào SM (Bộ đa xử lý dòng) đã làm điều đó.
Trong bài viết này, chúng tôi sẽ xem xét kiến trúc NVIDIA đã phát triển từ Tesla sang Turing như thế nào, vì vậy đây là thời điểm tốt để tìm hiểu về nền tảng và xem những gì cụ thể về từng kiến trúc này, bạn có thể tìm thấy tóm tắt trong bảng sau .

| Năm | Kiến trúc | Loạt | Die | Quy trình in | Biểu đồ đại diện nhất |
|---|---|---|---|---|---|
| 2006 | Tesla | GeForce 8 | G80 | 90nm | 8800 GTX |
| 2010 | Fermi | GeForce 400 | GF100 | 40nm | GTX 480 |
| 2012 | Kepler | GeForce 600 | GK104 | 28 nm | GTX 680 |
| 2014 | Tên của một hiệu cà phê | GeForce 900 | GM204 | 28 nm | 980 GTX Ti |
| 2016 | Pascal | GeForce 10 | GP102 | 16nm | 1080 GTX Ti |
| 2018 | Turing | GeForce 20 | TU102 | 12nm | RTX 2080 Ti |
Bế tắc: kỷ nguyên tiền NVIDIA Tesla
Cho đến khi Tesla đến vào năm 2006, NVIDIA của GPU thiết kế tương quan với các trạng thái logic của API kết xuất của nó. Các GeForce GTX 7900 , được cung cấp bởi die G71, được sản xuất thành ba phần (một phần dành riêng cho xử lý đỉnh (8 đơn vị), phần khác để tạo ra các đoạn (24 đơn vị) và phần khác để tham gia (16 đơn vị)).
Mối tương quan này buộc các nhà thiết kế và kỹ sư phải tưởng tượng vị trí của các nút thắt cổ chai để cân bằng từng lớp một cách hợp lý. Thêm vào đó là sự xuất hiện của DirectX 10 với bóng hình học, vì vậy các kỹ sư của NVIDIA đã tìm thấy chính mình giữa một tảng đá và một nơi khó để cân bằng giữa khuôn mà không biết khi nào và trong giai đoạn tiếp theo của API đồ họa.
Đã đến lúc thay đổi cách bạn thiết kế kiến trúc của bạn .
Kiến trúc NVIDIA Tesla
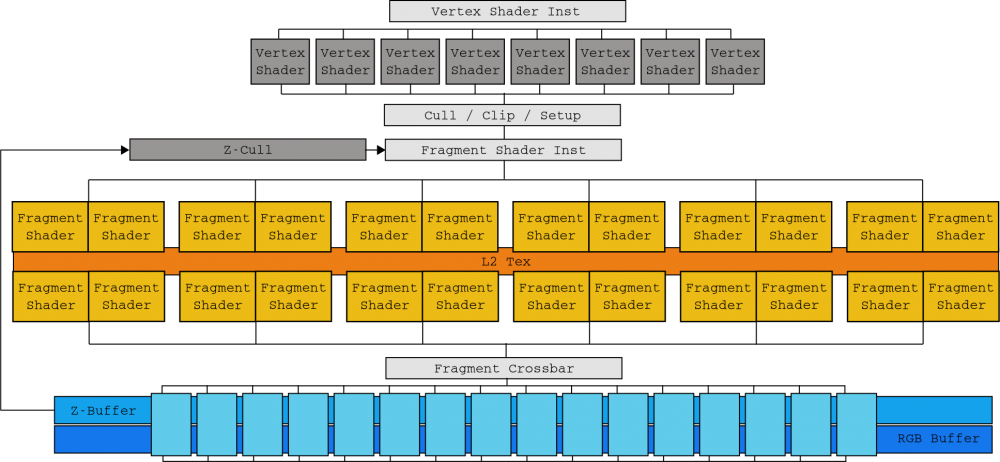
NVIDIA đã giải quyết vấn đề tăng độ phức tạp với kiến trúc Tesla của mình, chiếc máy tính thống nhất đầu tiên của Vương quốc Anh, vào năm 2006. Với chết G80 đã có không còn sự phân biệt giữa các lớp Bộ đa xử lý dòng (SM) đã thay thế tất cả các ổ đĩa trước đó nhờ khả năng thực hiện xử lý đỉnh, tạo shard và shard tham gia mà không phân biệt trong một kernel. Do đó, ngoài ra, tải được tự động cân bằng bằng cách trao đổi các lõi của Google được thực thi bởi mỗi SM tùy thuộc vào nhu cầu của từng thời điểm.
Do đó, các Đơn vị Shader bây giờ là các lõi lõi (không còn tương thích với SIMD) có khả năng tự xử lý một lệnh số nguyên hoặc float32 (SM nhận các luồng trong nhóm 32 được gọi là warps). Lý tưởng nhất là tất cả các luồng trong một sợi dọc sẽ thực hiện cùng một câu lệnh cùng lúc chỉ với các dữ liệu khác nhau (do đó có tên SIMT). Đơn vị lệnh đa luồng (MT) chịu trách nhiệm cho phép và vô hiệu hóa các luồng trên mỗi sợi dọc trong trường hợp các con trỏ lệnh (IP) hội tụ hoặc khác nhau.
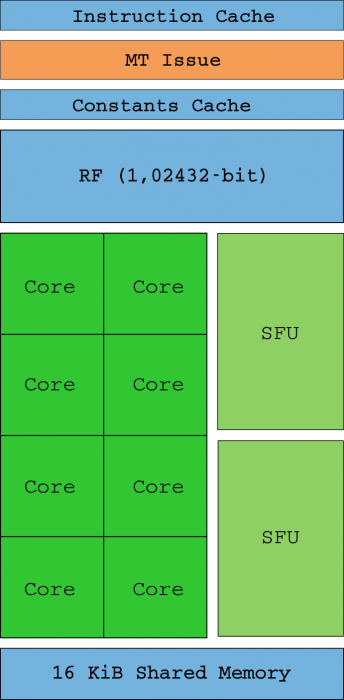
Hai SFU các đơn vị (bạn có thể thấy chúng trong sơ đồ trên) chịu trách nhiệm trợ giúp các phép tính toán học phức tạp như căn bậc hai nghịch đảo, sin, cosin, exp và RCp. Các đơn vị này cũng có khả năng thực hiện một lệnh cho mỗi chu kỳ đồng hồ, nhưng vì chỉ có hai, tốc độ thực hiện được chia cho bốn cho mỗi trong số chúng (nghĩa là, có một SFU cho mỗi bốn lõi). Không có hỗ trợ phần cứng cho các tính toán float64 và chúng được thực hiện bằng phần mềm, làm giảm đáng kể hiệu suất.
Một SM hoạt động với tiềm năng tối đa của nó khi độ trễ của bộ nhớ có thể được loại bỏ bằng cách luôn luôn có các sợi dọc có thể lập trình được trong hàng thực thi, nhưng cả khi luồng của sợi dọc không có phân kỳ (đó là dòng điều khiển dành cho chúng, luôn duy trì chúng ở cùng đường dẫn của hướng dẫn). Tệp nhật ký ( RF 4KB ) là nơi các trạng thái luồng được lưu trữ và các luồng tiêu thụ quá nhiều hàng đợi thực thi làm giảm số lượng chúng có thể được giữ trong nhật ký đó, cũng làm giảm hiệu suất.
Chiếc flagship hàng đầu của điểm chết của kiến trúc NVIDIA Tesla này là G90 dựa trên quy trình in thạch bản 90 nanomet, được trình bày với GeForce 8800 GTX nổi tiếng. Hai SM được nhóm thành một cụm bộ xử lý kết cấu (TPC) cùng với một đơn vị kết cấu và bộ đệm Tex L1. Với 8 TPC, G80 có 128 lõi tạo ra 345.6 GFLOPs tổng công suất. GeForce 8800 GTX đã vô cùng phổ biến trong những ngày đó.
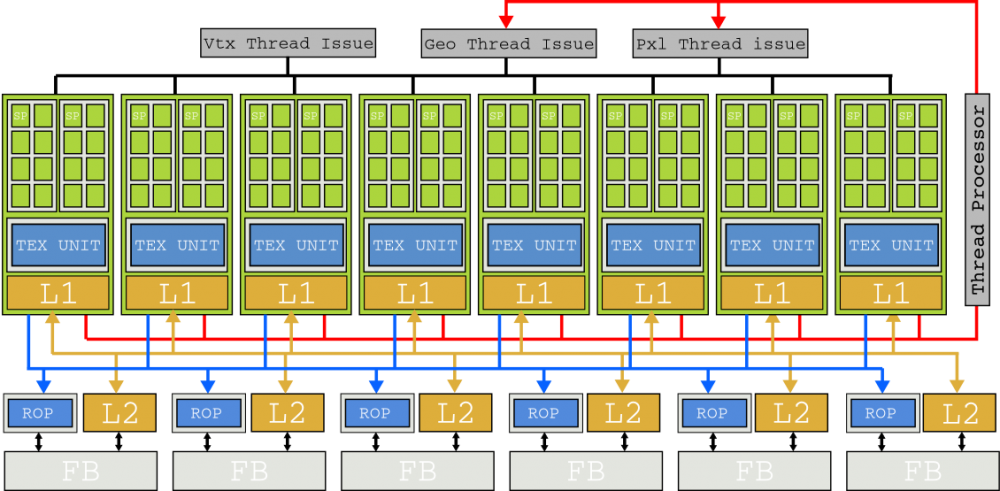
Với kiến trúc Tesla, NVIDIA cũng giới thiệu ngôn ngữ lập trình CUDA (Compute Unified Devide Architecture) trong C, một superset của C99, là một sự giải thoát đáng hoan nghênh cho những người đam mê GPGPU, người đã hoan nghênh một giải pháp thay thế để lừa đảo GPU bằng các bóng và họa tiết GLSL.
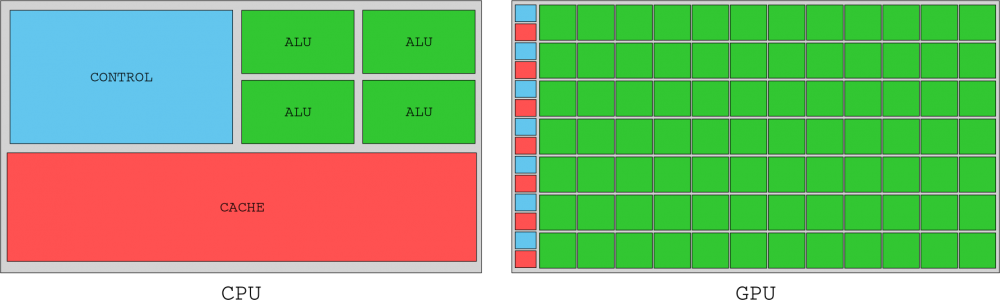
Mặc dù phần này tập trung rộng rãi vào SM, họ chỉ là một nửa hệ thống. SM cần được cung cấp các hướng dẫn và dữ liệu lưu trong bộ nhớ đồ họa của GPU, vì vậy để tránh tình trạng trì trệ, GPU không tránh bộ nhớ, các chuyến đi, bộ nhớ cache có nhiều bộ nhớ cache như bộ xử lý (CPU), thay vào đó, chúng làm lộn xộn bộ nhớ bus cho các yêu cầu I / O từ hàng ngàn luồng mà nó quản lý. Đối với điều này, hiệu năng bộ nhớ cao đã được triển khai trong chip G80 thông qua sáu kênh bộ nhớ DRAM hai chiều.
Kiến trúc Fermi
Tesla là một bước đi rất mạo hiểm nhưng hóa ra lại rất tốt và thành công đến nỗi nó trở thành nền tảng của kiến trúc NVIDIA trong hai thập kỷ tiếp theo. Năm 2010, NVIDIA ra mắt GF100 chết dựa trên cái mới Fermi kiến trúc, với nhiều tính năng mới bên trong.
Mô hình thực thi vẫn xoay quanh các sợi dọc 32 dây được lập trình thành SM và nó chỉ nhờ vào nó In thạch bản 40nm (so với 90nm của Tesla) mà NVIDIA tăng gấp bốn lần mọi thứ. Một SM bây giờ có thể lập trình đồng thời hai sợi truyền thông (16 luồng) nhờ hai bộ 16 lõi CUDA. Với mỗi lõi thực hiện một lệnh trong mỗi chu kỳ đồng hồ, một SM duy nhất có thể thực hiện một lệnh dọc trong mỗi chu kỳ (và đây là gấp 4 lần công suất của Tesla SMs).

Số lượng SFU cũng được tăng cường, mặc dù ít hơn bởi vì nó chỉ là số nhân với hai, với tổng số bốn đơn vị. Hỗ trợ phần cứng cũng được thêm vào cho các tính toán float64, mà Tesla thiếu, được thực hiện bởi hai lõi CUDA kết hợp. GF100 có thể thực hiện phép nhân số nguyên trong một chu kỳ xung nhịp đơn nhờ ALU 32 bit (so với 24 bit trong Tesla) và có độ chính xác float32 cao hơn.
Từ góc độ lập trình, hệ thống bộ nhớ hợp nhất của Fermi cho phép CUDA C được tăng cường với các tính năng C ++ như các đối tượng và phương thức ảo.
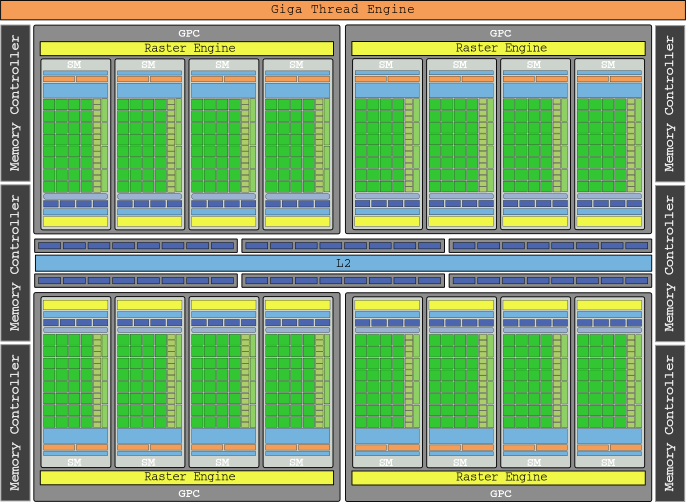
Với các đơn vị kết cấu hiện là một phần của SM, khái niệm TPC biến mất, thay vào đó là các cụm bộ xử lý đồ họa (GPC) có bốn SM. Cuối cùng nhưng không kém phần quan trọng, một công cụ Polymorph 'được thêm vào để xử lý các đỉnh đối tượng, chuyển đổi khung nhìn và tessname. Flagship đồ họa của thế hệ này là GTX 480, với 512 lõi của nó có 1,345 GFLOPs tổng sức mạnh.
Kiến trúc NVIDIA Kepler
Vào năm 2012, kiến trúc NVIDIA Kepler, với hiệu suất năng lượng của cái chết được cải thiện đáng kể bằng cách giảm tốc độ xung nhịp và thống nhất đồng hồ trung tâm với thẻ (chúng từng có tần số gấp đôi), do đó giải quyết vấn đề GTX 480 thế hệ trước (chúng rất nóng và có mức tiêu thụ rất cao).
Những thay đổi này sẽ dẫn đến hiệu suất thấp hơn, nhưng nhờ thực hiện quy trình in thạch bản 28nm và loại bỏ lập trình viên phần cứng có lợi cho phần mềm, NVIDIA không chỉ có thể thêm SM, mà còn cải thiện thiết kế của nó. .

Bộ đa xử lý phát trực tuyến thế hệ tiếp theo, tên gọi là SMX, hóa ra là một con quái vật trong đó hầu hết mọi thứ đã tăng gấp đôi hoặc thậm chí gấp ba. Với bốn lập trình viên sợi dọc có khả năng xử lý toàn bộ sợi dọc trong một chu kỳ đồng hồ (so với thiết kế hai nửa của Fermi), SMX hiện có chứa 196 lõi. Mỗi lập trình viên có một công văn kép để thực hiện một lệnh thứ hai trong một sợi dọc nếu nó độc lập với lệnh hiện đang được thực thi, mặc dù lập trình kép này không phải lúc nào cũng khả thi.
Cách tiếp cận này làm cho logic lập trình trở nên phức tạp hơn, nhưng với tối đa sáu lệnh dọc trên mỗi đồng hồ, SMX Kepler cung cấp hiệu năng gấp đôi so với Fermi SM.
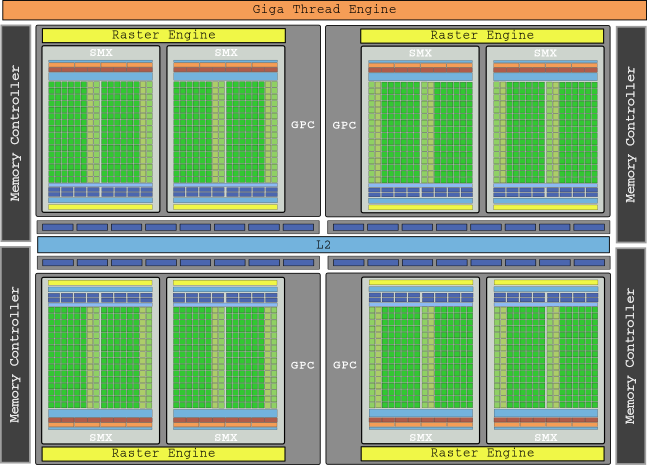
Đồ họa hàng đầu của thế hệ này là GeForce GTX 680 với GK104 và 8 SMX chết chóc, chứa số lượng đáng kinh ngạc là 1536 lõi và cung cấp tổng cộng tới 3,250 GFLOPs.
Kiến trúc NVIDIA Maxwell
Năm 2014 đã xuất hiện kiến trúc NVIDIA Maxwell, GPU thế hệ thứ 10 của nó. Như họ đã giải thích trong tài liệu kỹ thuật của mình, trung tâm của các GPU này là hiệu suất năng lượng cực cao và hiệu suất vượt trội trên mỗi watt tiêu thụ, và đó là điều mà NVIDIA hướng thế hệ này đến các hệ thống năng lượng hạn chế như máy tính mini và máy tính xách tay.
Quyết định chính là từ bỏ cách tiếp cận của Kepler với SMX và trở lại với triết lý làm việc với truyền thông của Warp. Do đó, lần đầu tiên trong lịch sử của nó, SMM có ít lõi hơn so với người tiền nhiệm của nó với chỉ có lõi 128. Việc số lượng lõi được điều chỉnh theo kích thước của sợi dọc đã cải thiện cấu trúc của khuôn, điều này giúp tiết kiệm rất nhiều không gian chiếm dụng và tiêu thụ năng lượng.
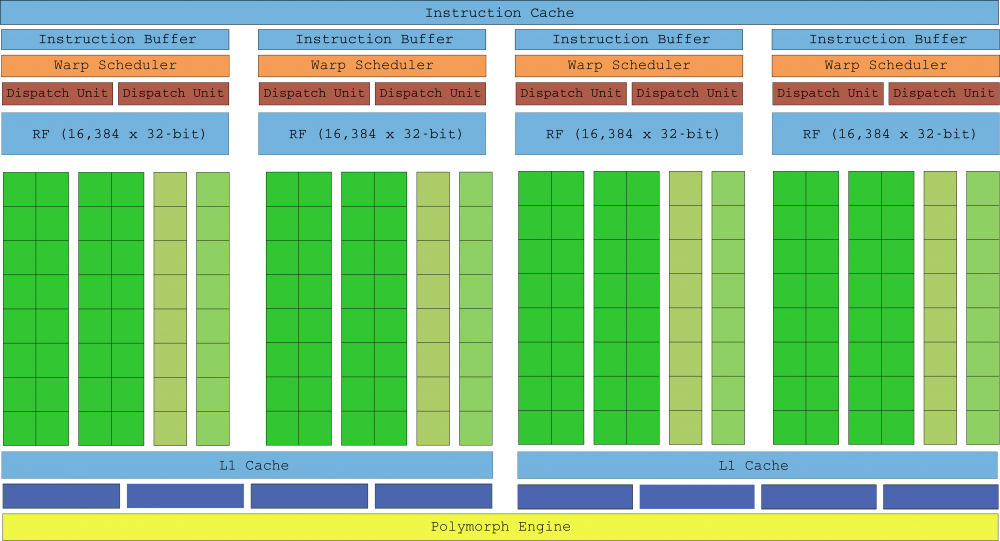
Thế hệ thứ hai của Maxwell cải thiện đáng kể hiệu suất trong khi vẫn duy trì hiệu quả năng lượng của thế hệ đầu tiên. Với quy trình in thạch bản vẫn bị trì trệ ở 28nm, các kỹ sư của NVIDIA không thể dựa vào việc thu nhỏ các bóng bán dẫn để cải thiện hiệu suất, nhưng số lõi trên mỗi SMM giảm kích thước của chúng, cho phép chúng phù hợp với nhiều SMM hơn. trong cùng một ngày Maxwell Gen 2 chứa gấp đôi SMM với tư cách là Kepler với diện tích chỉ hơn 25%.
Trong danh sách các cải tiến, chúng ta cũng nên đề cập đến logic lập lịch đơn giản hơn giúp giảm tính toán lại các quyết định lập lịch, giúp giảm độ trễ tính toán để cung cấp khả năng chiếm chỗ tốt hơn. Đồng hồ bộ nhớ cũng tăng trung bình 15%.
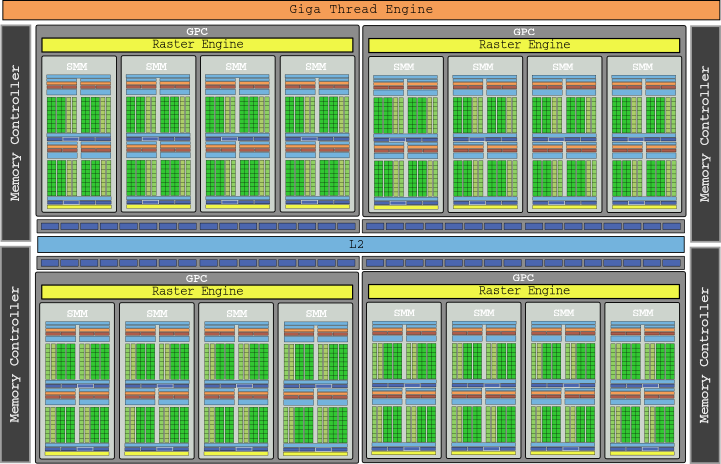
Sơ đồ của chip GM200 mà chúng ta thấy ở trên gần như bắt đầu làm tổn thương mắt, phải không? Đó là cái chết kết hợp GTX 980 Ti, với 3072 lõi trong 24 SMM và cung cấp sức mạnh tổng cộng 6,060 GLOP.
Kiến trúc NVIDIA Pascal
Vào năm 2016, thế hệ tiếp theo, NVIDIA Pascal, đã xuất hiện và tài liệu kỹ thuật trông gần giống như một bản sao của SMM của Maxwell. Nhưng chỉ vì không có thay đổi nào đối với SM không có nghĩa là không có cải tiến, và trên thực tế, quy trình 16nm được sử dụng trong các chip này đã cải thiện đáng kể hiệu năng bằng cách có thể đặt nhiều SM hơn trên cùng một chip.
Những cải tiến quan trọng khác cần làm nổi bật là hệ thống bộ nhớ GDDR5X, một tính năng mới cung cấp tốc độ truyền lên tới 10 Gbps nhờ tám bộ điều khiển bộ nhớ, với giao diện 256 bit cung cấp băng thông lớn hơn 43% so với thế hệ trước.
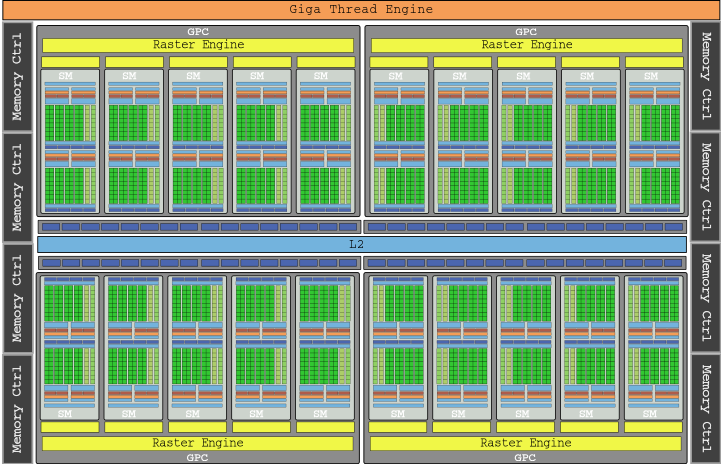
Flagship đồ họa của thế hệ Pascal là GTX 1080 Ti, với GP102 die mà bạn có thể thấy trong hình trên và 28 SM của nó, đóng gói tổng cộng 3584 lõi cho tổng sức mạnh 11,340 GLOP (chúng tôi đã ở mức 11.3 TFLOPs ).
Kiến trúc Turing NVIDIA
Ra mắt vào năm 2018, Turing Architecture là bước nhảy vọt về kiến trúc lớn nhất trong hơn một thập kỷ qua (theo cách nói của NVIDIA). Không chỉ SM Turing được thêm vào, mà phần cứng Ray Trace chuyên dụng đã được giới thiệu lần đầu tiên, với lõi Tensor Cores và RayTracing. Thiết kế này giả định rằng cái chết là một lần nữa bị phân mảnh, theo kiểu các lớp của thời kỳ tiền Tesla mà chúng tôi đã nói với bạn lúc đầu.
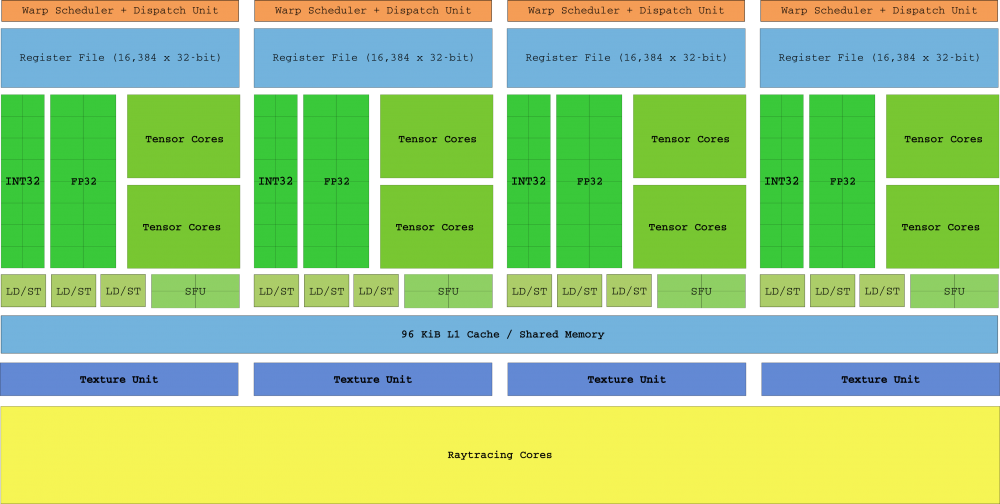
Ngoài các nhân mới, Turing đã bổ sung ba tính năng chính: Thứ nhất, nhân CUDA hiện có khả năng mở rộng và có khả năng thực hiện song song cả lệnh số nguyên và dấu phẩy động (điều này sẽ nhắc nhở nhiều người về “cuộc cách mạng” Intel Kiến trúc Pentium trở lại đó. năm 1996). Thứ hai, hệ thống bộ nhớ GDDR6 mới được hỗ trợ bởi 16 bộ điều khiển, hiện có thể đạt tốc độ 14 Gbps và cuối cùng là các luồng không còn chia sẻ con trỏ lệnh trong các sợi dây.
Nhờ lập trình luồng độc lập được giới thiệu trong Volta (mà chúng tôi không bao gồm ở đây vì đây là kiến trúc không tập trung vào người dùng), mỗi luồng có IP riêng và do đó, SM có thể tự do lập trình các luồng trong một sợi dọc mà không cần sự cần thiết phải chờ đợi họ hội tụ càng sớm càng tốt.

Đồ họa hàng đầu của thế hệ này là RTX 2080 Ti, với TU102 die và 68 TSM chứa 4352 lõi, với sức mạnh tổng cộng là 13.45 TFLOPs. Chúng tôi không đặt sơ đồ khối hoàn chỉnh của anh ấy như trong các phần trước bởi vì để nó phù hợp với màn hình, nó sẽ phải được thu nhỏ đến mức nó sẽ bị mờ.
Và điều gì đến tiếp theo?
Như bạn đã biết, kiến trúc NVIDIA tiếp theo được gọi là Ampere, và nó chắc chắn sẽ đến với nút sản xuất ở 7nm từ TSMC. Chúng tôi sẽ cập nhật bài viết này ngay khi tất cả dữ liệu có sẵn.