Hướng dẫn AVX-512 là một trong những yếu tố độc đáo của Intelcủa x86 CPU kiến trúc. Nhưng những hướng dẫn này là gì vì nó được triển khai trên CPU Intel? Hãy tiếp tục đọc để hiểu lý do tồn tại của các hướng dẫn này, các biến thể của nó và tại sao nó không được sử dụng bởi AMD trong các CPU của nó.
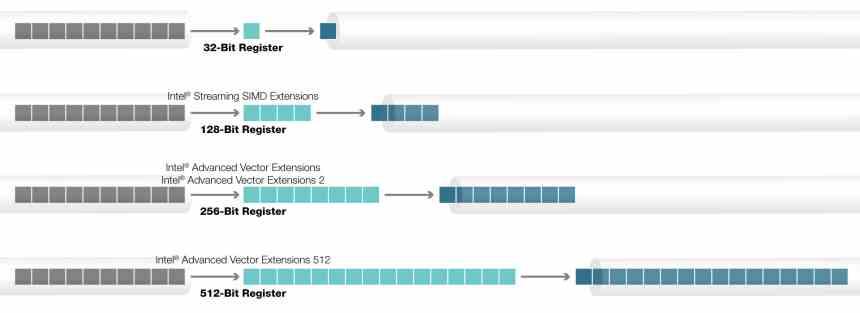
Các lệnh AVX lần đầu tiên được triển khai trong CPU Intel, thay thế các lệnh SSE cũ. Kể từ đó, chúng đã trở thành hướng dẫn SIMD tiêu chuẩn cho các CPU x86 trong hai biến thể của chúng, 128-bit và 256-bit, cũng đang được AMD áp dụng. Mặt khác, nếu chúng ta nói về các lệnh AVX-512, tình hình lại khác và chúng chỉ được sử dụng trong các CPU Intel.

Đơn vị SIMD là gì?
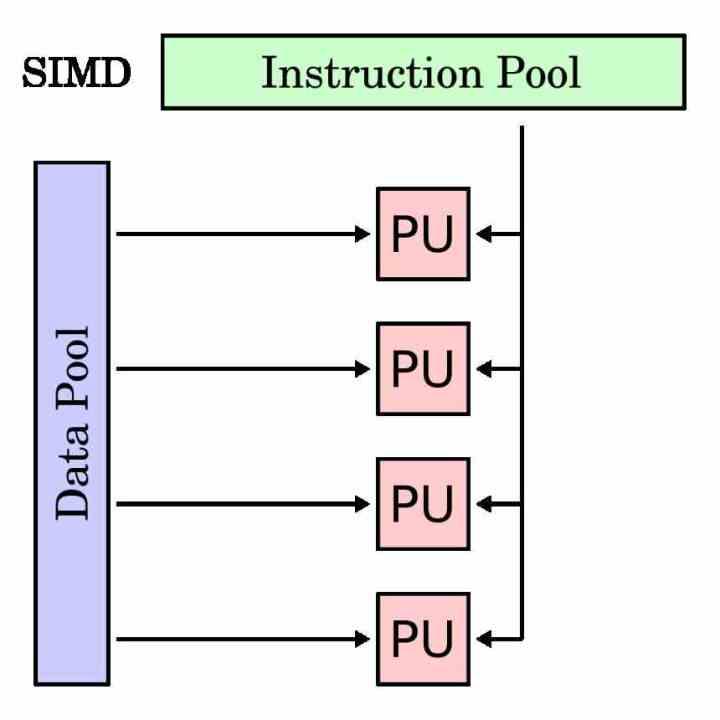
Đơn vị SIMD là một loại đơn vị thực thi nhằm thực hiện cùng một lệnh cho nhiều dữ liệu cùng một lúc. Do đó, thanh ghi bộ tích lũy của nó dài hơn một lệnh truyền thống, vì nó phải nhóm các dữ liệu khác nhau mà nó phải hoạt động với cùng một lệnh đó.
Các đơn vị SIMD thường được sử dụng để tăng tốc cái gọi là các quy trình đa phương tiện, trong đó cần phải xử lý các dữ liệu khác nhau theo cùng một hướng dẫn. Các đơn vị SIMD cho phép thực hiện song song chương trình trong các phần này và để đẩy nhanh thời gian thực hiện.
Trong mọi bộ xử lý, để tách các đơn vị thực thi SIMD khỏi các đơn vị truyền thống, chúng có một tập hợp con các lệnh riêng thường là bản sao của các lệnh vô hướng hoặc với một toán hạng duy nhất. Mặc dù có những trường hợp không thể thực hiện với đơn vị vô hướng và chỉ dành riêng cho đơn vị SIMD.
Lịch sử của AVX-512

Các lệnh AVX, Advanced Vector eXtensions, đã có trong bộ xử lý Intel trong nhiều năm, nhưng nguồn gốc của các lệnh AVX-512 khác với phần còn lại. Nguyên nhân? Nguồn gốc của nó là dự án Intel Larrabee, một nỗ lực của Intel vào cuối những năm 2000 nhằm tạo ra một GPU cuối cùng trở thành máy gia tốc Xeon Phi. Một loạt bộ vi xử lý dành cho máy tính hiệu năng cao mà Intel đã phát hành cách đây vài năm.
Kiến trúc Xeon Phi / Larrabee bao gồm một phiên bản đặc biệt của lệnh AVX với kích thước trong thanh ghi bộ tích lũy của chúng là 512 bit, có nghĩa là chúng có thể hoạt động với tối đa 16 dữ liệu 32 bit. Lý do cho số tiền này liên quan đến thực tế là tỷ lệ hoạt động điển hình trên mỗi texel cho GPU thường là 16: 1. Đừng quên rằng các hướng dẫn AVX-512 bắt nguồn từ dự án Larrabee thất bại và được đưa từ đó đến Xeon Phi.
Cho đến ngày nay, Xeon Phi không còn tồn tại nữa, lý do cho điều này là điều tương tự có thể được thực hiện thông qua một GPU truyền thống cho máy tính. Điều này khiến Intel chuyển các lệnh này sang dòng CPU chính của mình.
Các hướng dẫn vô nghĩa đó là AVX-512
Các lệnh AVX-512 không phải là một khối đồng nhất được thực hiện 100%, mà có nhiều phần mở rộng khác nhau, tùy thuộc vào loại bộ xử lý, có được thêm vào hay không. Tất cả các CPU được gọi là AVX512F, nhưng có các lệnh bổ sung không phải là một phần của bộ lệnh gốc và Intel đã thêm vào theo thời gian.
Các phần mở rộng AVX512 như sau:
- AVX-512-CD: Phát hiện xung đột, cho phép các vòng lặp được vectơ hóa và do đó được vectơ hóa. Chúng lần đầu tiên được thêm vào Skylake-X hoặc Skylake-SP.
- AVX-512-ER: Các hướng dẫn đối ứng và hàm mũ, được thiết kế để thực hiện các phép toán siêu việt. Chúng được thêm vào trong một phạm vi Xeon Phi được gọi là Knights Landing.
- AVX-512-PF: Một lần nữa được đưa vào Knights Landing, lần này để tăng khả năng phòng ngừa hoặc phản đối trước các chỉ dẫn.
- AVX-512-BW: Lệnh byte cấp độ (8-bit) và cấp độ từ (16-bit). Phần mở rộng này cho phép bạn làm việc với dữ liệu 8 bit và 16 bit.
- AVX-512-DQ: Thêm hướng dẫn mới với dữ liệu 32 bit và 64 bit.
- AVX-512-VL : Cho phép các lệnh AVX hoạt động trên thanh ghi bộ tích lũy XMM (128-bit) và YMM (256-bit)
- AVX-512-IFMA: Fused Multiply Add, thông thường là một lệnh A * (B + C), với độ chính xác số nguyên 52 bit.
- AVX-512-VBMI: Hướng dẫn thao tác vectơ cấp byte, là một phần mở rộng cho AVX-512-BW.
- AVX-512-VNNI: Hướng dẫn Mạng nơron Vector là một loạt các hướng dẫn được thêm vào để tăng tốc các thuật toán Học sâu, được sử dụng trong các ứng dụng liên quan đến trí tuệ nhân tạo.
Tại sao AMD vẫn chưa triển khai nó trên các CPU của họ?

Lý do cho điều này rất đơn giản, AMD cam kết sử dụng kết hợp CPU và GPU của mình khi tăng tốc một số loại ứng dụng nhất định. Chúng ta đừng quên nguồn gốc của AVX-512 trong một GPU bị lỗi của Intel và AMD nhờ GPU Radeon của họ mà họ không cần sử dụng hướng dẫn AVX-512.
Đó là lý do tại sao các hướng dẫn AVX-512 chỉ dành riêng cho bộ vi xử lý Intel, không phải hoàn toàn độc quyền, mà bởi vì AMD không quan tâm đến việc sử dụng loại hướng dẫn này trong CPU của mình, vì ý định bán GPU của mình, đặc biệt là AMD Instinct mới ra mắt tính toán hiệu suất cao với kiến trúc CDNA.
Các hướng dẫn AVX-512 có tương lai không?

Chúng tôi không biết, điều đó phụ thuộc vào sự thành công của Intel Xe, đặc biệt là Xe-HPC, thứ sẽ cung cấp cho Intel kiến trúc GPU ở cấp độ của AMD và NVIDIA. Điều này có nghĩa là xung đột giữa Intel Xe và hướng dẫn AVX-512 để giải quyết các vấn đề tương tự.
Vấn đề với AVX-512 là việc kích hoạt phần CPU sử dụng nó sẽ ảnh hưởng đến tốc độ xung nhịp của CPU, giảm khoảng 25% trong một chương trình sử dụng các hướng dẫn này cho những thời điểm cụ thể. Ngoài ra, các hướng dẫn của nó dành cho các ứng dụng tính toán hiệu suất cao và AI không quan trọng đối với CPU gia đình là gì và sự xuất hiện của các đơn vị chuyên dụng khiến nó trở nên lãng phí bóng bán dẫn và không gian.
Trên thực tế, các bộ tăng tốc hoặc bộ xử lý dành riêng cho miền đang dần thay thế các đơn vị SIMD trong CPU, vì chúng có thể làm được điều tương tự trong khi chiếm ít không gian hơn và tiêu thụ điện năng rất nhỏ so với.