Chipletlerden oluşan çoklu GPU'lar hemen köşede ve bunları ilk olarak HPC kartları biçiminde ve dolayısıyla oyun pazarının dışında görsek de, evrimin Çoklu GPU'lara dayalı grafik kartlarının inşasına doğru olduğunu uzun zamandır biliyoruz. chiplet başına. Ama geleneksel bir monolitik ile karşılaştırıldığında ne getiriyorlar? GPU? Öğrenmek için okumaya devam edin.

Bu yazıda tartıştığımız mimari henüz piyasada mevcut değil, sunulmadı bile, ancak son yıllarda üretilen ilerlemelerin bir analizinin yanı sıra Multi-GPU üzerindeki farklı patentlerin bir ürünüdür. her ikisi de yongalar AMD, NVIDIA ve Intel son iki yıldır yayınlanmaktadır. Bu nedenle, bu tür GPU'ların nasıl çalıştığı ve hangi grafik sorunlarını çözmeye geldikleri hakkında bir fikriniz olması için bu bilgileri alıp sentezlemeye karar verdik.
Birden çok GPU ile geleneksel 3D işleme

3D video oyunlarında her kareyi oluşturmak için güçlerini birleştirmek için birden fazla grafik kartı kullanmak yeni değil, çünkü Voodoo 2 by 3dfx, oluşturma işini tamamen veya kısmen birkaç grafik kartı arasında bölmek mümkündür. Bunu yapmanın en yaygın yolu, Alternatif Çerçeve Oluşturma'dır. işlemci her karenin ekran listesini dönüşümlü olarak her GPU'ya gönderir. Örneğin, GPU 1 1, 3, 5, 7 çerçevelerini işlerken, GPU 2 2, 4, 6, 8 vb. çerçeveleri işler.
Bir sahneyi 3B olarak oluşturmanın başka bir yolu da vardır; tek bir sahneyi oluşturan ve işi bölen birkaç GPU'dan oluşan ancak aşağıdaki nüanslara sahip Bölünmüş Çerçeve Oluşturma: GPU, ekran listesini okuyan ana GPU'dur ve gerisini halleder. İşlem hattının rasterleştirmeden önceki ilk aşamaları, rasterleştirmede olduğu gibi yalnızca ilk GPU'da gerçekleştirilir ve sonraki aşamalar her GPU'da eşit olarak gerçekleştirilir.
Bölünmüş Çerçeve Oluşturma, işi dağıtmak için adil bir yol gibi görünüyor, ancak şimdi bu yöntemin içerdiği sorunların neler olduğunu ve hangi sınırlamalarla olduğunu göreceğiz.
Bölünmüş Çerçeve Oluşturmanın sınırlamaları ve olası çözüm

Her GPU, 2 DMA sürücüsü koleksiyonu içerir, ilk çift aynı anda sistemde veri okuyabilir veya yazabilir RAM PCI Express bağlantı noktası aracılığıyla, ancak Crossfire veya SLI destekli birçok grafik kartında, diğer grafiğin VRAM'ına erişime izin veren başka bir DMA sürücüsü koleksiyonu vardır. Tabii ki, gerçek bir darboğaz olan PCI Express bağlantı noktası hızında.
İdeal olarak, birlikte çalışan tüm GPU'ların ortak özelliği aynı VRAM belleğine sahip olmalarıdır, ancak durum böyle değildir. Böylece veriler, işlemeye dahil olan grafik kartlarının sayısı kadar çoğaltılır, bu da büyük ölçüde verimsizdir. Buna, birden fazla grafik kartıyla yapılandırmanın artık kullanılmamasına neden olan gerçek zamanlı olarak 3D grafikler oluştururken grafik kartlarının çalışma şeklini eklememiz gerekiyor.
Chipletler ile Çoklu GPU'da Döşeme Önbelleğe Alma
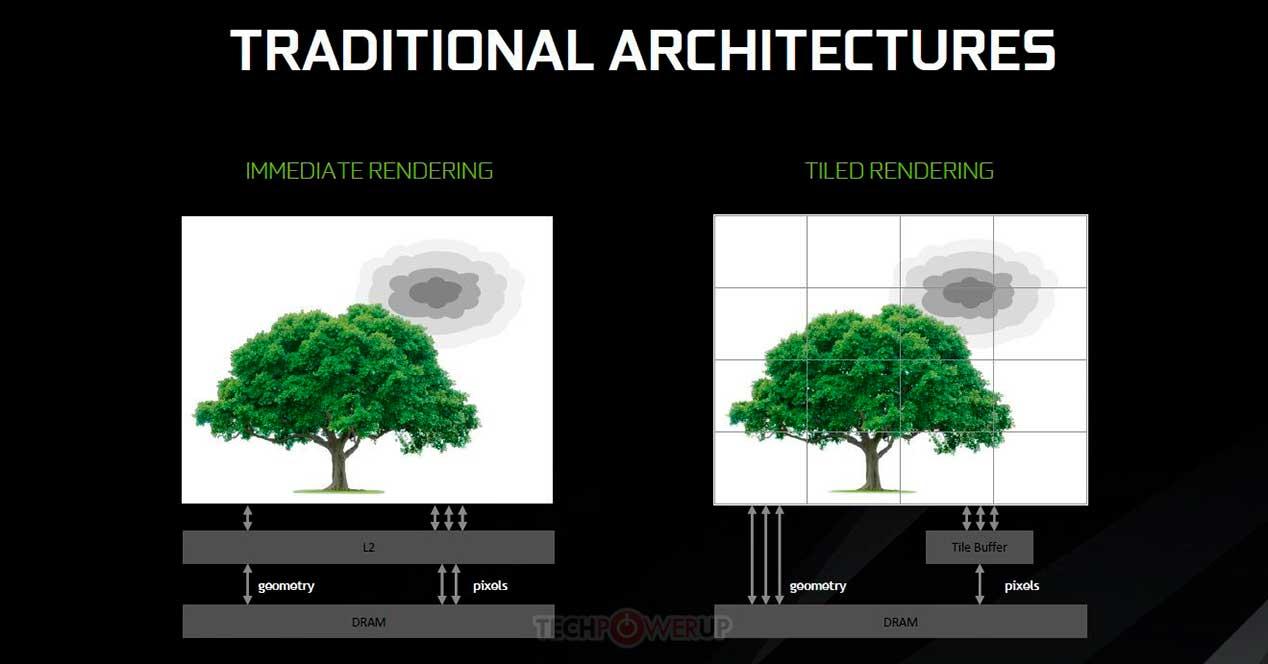
Döşeme Önbelleğe Alma konsepti, NVIDIA'nın Maxwell mimarisinden ve AMD'nin Vega mimarisinden kullanılmaya başlandı, bu, döşemelerle işlemeden bazı kavramları almakla ilgilidir, ancak şu farkla ki, her döşemeyi ayrı bir bellekte işlemek ve yalnızca VRAM'a yazmak yerine, tamamlandı, ikinci seviye önbellekte yapılır. Bunun avantajı, bazı grafik işlemlerinin enerji maliyetinden tasarruf sağlamasıdır, ancak dezavantajı, GPU'daki üst düzey önbellek miktarına bağlı olmasıdır.
Sorun, bir önbelleğin geleneksel bir bellek gibi çalışmamasıdır ve herhangi bir anda ve program kontrolü olmadan bir önbellek satırı, bellek hiyerarşisinin bir sonraki düzeyine gönderilebilir. Ya aynı işlevi chiplet tabanlı bir GPU'ya uygulamaya karar verirsek? Pekala, ek önbellek seviyesinin devreye girdiği yer burasıdır. Yeni paradigma altında, Döşeme Önbelleği için bellek olarak her bir GPU'nun son seviye önbelleği yok sayılır ve şu anda Çoklu-GPU'nun son seviye önbelleği kullanılır. ayrı bir çip.
Chiplet'ler tarafından Çoklu GPU'daki LCC
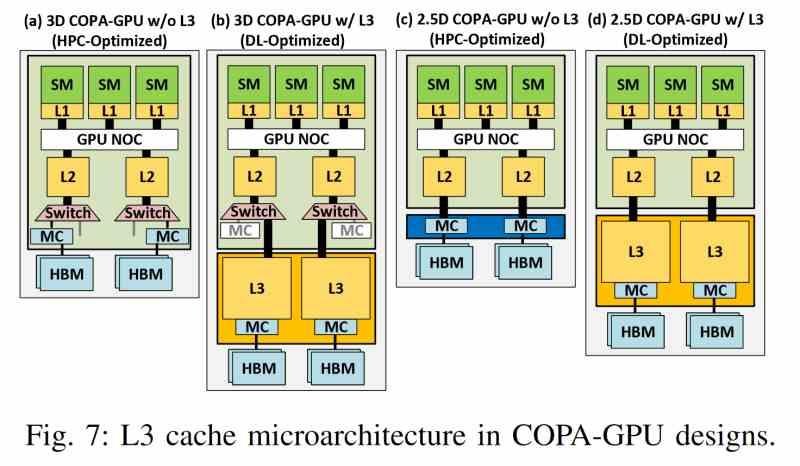
Chiplet tabanlı Çoklu GPU'lar için en son düzey önbellek, üreticinin kim olduğundan bağımsız bir dizi ortak özelliği bir araya getirir, bu nedenle aşağıdaki özellikler listesi, üreticiden bağımsız olarak bu tür herhangi bir GPU için geçerlidir.
- GPU'ların hiçbirinde bulunmaz, ancak onların dışındadır ve bu nedenle ayrı bir çip üzerindedir.
- Her GPU'nun L2 önbelleği ile iletişim kurmak için silikon köprüsü veya TSV ara bağlantıları gibi çok yüksek hızlı bir arabirime sahip bir aracı kullanır.
- Gereken yüksek bant genişliği, geleneksel ara bağlantılara izin vermez ve bu nedenle yalnızca 2.5DIC konfigürasyonunda mümkündür.
- Son seviye önbelleğin bulunduğu yonga, yalnızca söz konusu belleği depolamakla kalmaz, aynı zamanda tüm VRAM erişim mekanizmasının bulunduğu yerdir, bu şekilde işleme motorundan ayrıştırılır.
- Bant genişliği, HBM belleğinden çok daha yüksektir, bu nedenle çok daha yüksek bant genişliklerine izin veren daha gelişmiş 3D ara bağlantı teknolojilerini kullanır.
- Ek olarak, herhangi bir son seviye önbellek gibi, istemcisi olan tüm öğelere tutarlılık verme yeteneğine sahiptir.
Bu önbellek sayesinde, her GPU'nun paylaşılan bir VRAM'e sahip olması için kendi VRAM'ına sahip olması engellenir, bu da veri çokluğunu büyük ölçüde azaltır ve geleneksel bir çoklu GPU'da iletişim ürünü olan darboğazları ortadan kaldırır.
Ana ve alt GPU'lar
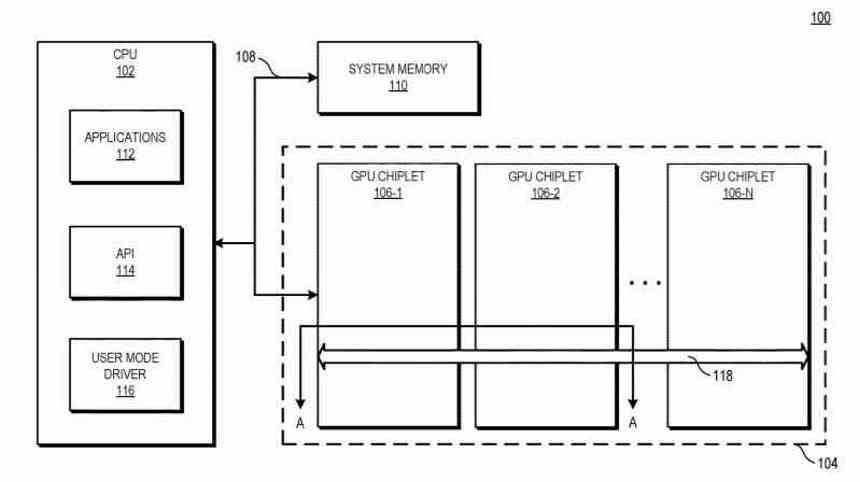
Chiplet'li Çoklu GPU'ya dayalı bir grafik kartında, görüntüleme listesi oluşturulurken geleneksel bir Çoklu GPU'dakiyle aynı konfigürasyon hala mevcuttur. GPU'ların geri kalanını yönetmekten sorumlu olan ilk GPU'yu alan tek bir liste oluşturulduğunda, ancak büyük fark, önceki bölümde tartıştığımız LLC yongasının ilk GPU'nun görevleri koordine etmesine ve göndermesine izin vermesidir. chiplet başına çoklu GPU işleme birimlerinin geri kalanı.
Alternatif bir çözüm, Multi-GPU'nun tüm yongalarının Komut İşlemcisinden tamamen yoksun olacağı ve bu, LCC yongasının orkestra iletkeni olarak bulunduğu devre ile aynı devrede olması ve farklı komutları göndermek için mevcut tüm iletişim altyapısından yararlanmasıdır. GPU'nun farklı bölümlerine iş parçacığı.
İkinci durumda, bir ana GPU'muz olmayacaktı ve geri kalanı astlar olarak olmayacaktı, ancak 2.5D tümleşik devrenin tamamı tek bir GPU olacaktı, ancak monolitik olmak yerine birkaç yongadan oluşacaktı.
Işın İzleme için önemi

Gelecek için en önemli noktalardan biri, ışığın taşınmasını temsil etmek için sistemin nesnelerin bilgileri üzerinde uzamsal bir veri yapısı oluşturmasını gerektiren Işın İzleme'dir. Söz konusu yapının işlemciye yakın olması durumunda Ray Tracing'in maruz kaldığı ivmenin önemli olduğu gösterilmiştir.
Tabii ki, bu yapı karmaşıktır ve çok fazla bellek kaplar. Bu nedenle gelecekte büyük bir LLC önbelleğine sahip olmak son derece önemli olacaktır. Ve bu, LLC önbelleğinin ayrı bir yongada olmasının nedenidir. Mümkün olan en yüksek kapasiteye sahip olmak ve bu veri yapısını mümkün olduğunca GPU'ya yakın hale getirmek.
Bugün Işın İzleme'deki yavaşlığın çoğu, verilerin çoğunun VRAM'de olması ve erişiminde büyük bir gecikme olması gerçeğinden kaynaklanmaktadır. Bir Çoklu GPU'daki LLC önbelleğinin yalnızca bant genişliğinde değil, aynı zamanda bir önbellek gecikmesinde de avantajlara sahip olacağını unutmayın. Ayrıca, büyük boyutu ve Intel, AMD ve NVIDIA laboratuvarlarında geliştirilen veri sıkıştırma teknikleri, hızlandırma için kullanılan BVH yapılarının GPU'nun “dahili” belleğinde saklanmasını sağlayacaktır.
