
Den första processorn med körning utan order var IBM POWER 1, som skulle ligga till grund för RISC-processorer med samma namn och PowerPC. Intel antog denna teknik för x86 i sin Pentium Pro. Sedan dess använder alla datorprocessorer out-of-order-teknik som en av baserna för att få maximal möjlig prestanda.
Det största problemet vid utformningen av processorer är ofta inte att få ut mesta möjliga, utan den bästa prestandan när du utför instruktionerna. Vi förstår prestanda som det faktum att vi närmar oss det teoretiska idealet för en processors operation. Det är värdelöst att ha det mest kraftfulla CPU om det på grund av begränsningar är det enda det har potential att vara och inte är.
Två sätt att hantera parallellitet
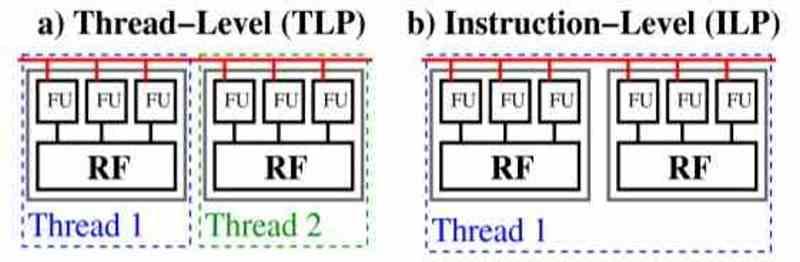
Det finns två sätt att behandla parallellism i koden för ett program, dessa är trådnivåparallellism eller ILP och instruktionsparallellism eller TLP.
I TLP är koden uppdelad i flera delprogram, som är oberoende av de andra och fungerar asynkront, vilket innebär att var och en av dem inte beror på resten av koden. När vi befinner oss i en TLP-processor är nyckeln att om ett körningsstopp inträffar av någon anledning så tar TLP-processorn en annan av körtrådarna och placerar den inaktiva i vänteläge.
ILP-processorer är olika, deras parallellitet är instruktionsnivå och därför i samma tråd för utförande, så de kan inte fuska genom att sätta huvudtråden i vänteläge. Numera kombinerar processorerna de två typerna av körning, men ILP är fortfarande exklusivt för processorer och det är där de får en stor fördel när det gäller seriekod jämfört med helt parallelliserbar kod.
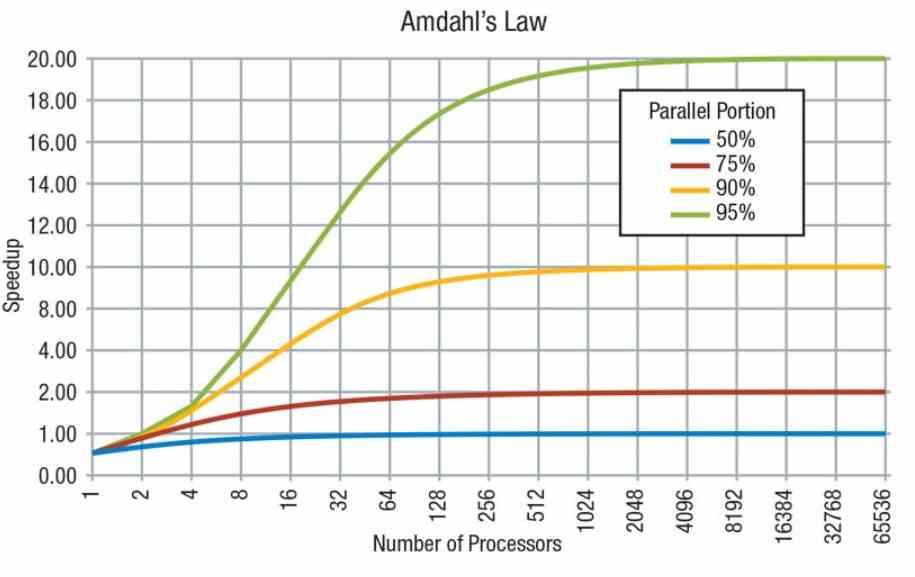
Vi kan inte glömma att enligt Amdahls lag består en kod av delar i serie, som bara kan köras av en processor, och parallellt, som kan köras av flera processorer. Men inte allt kan parallelliseras och det finns seriella delar av koden som kräver seriell drift.
Under de senaste 15 åren har konceptet utvecklats där parallella algoritmer körs på GPU: er, vars kärnor är av TLP-typ, medan seriell kod körs på processorer som är av ILP-typ.
Beställning av instruktioner
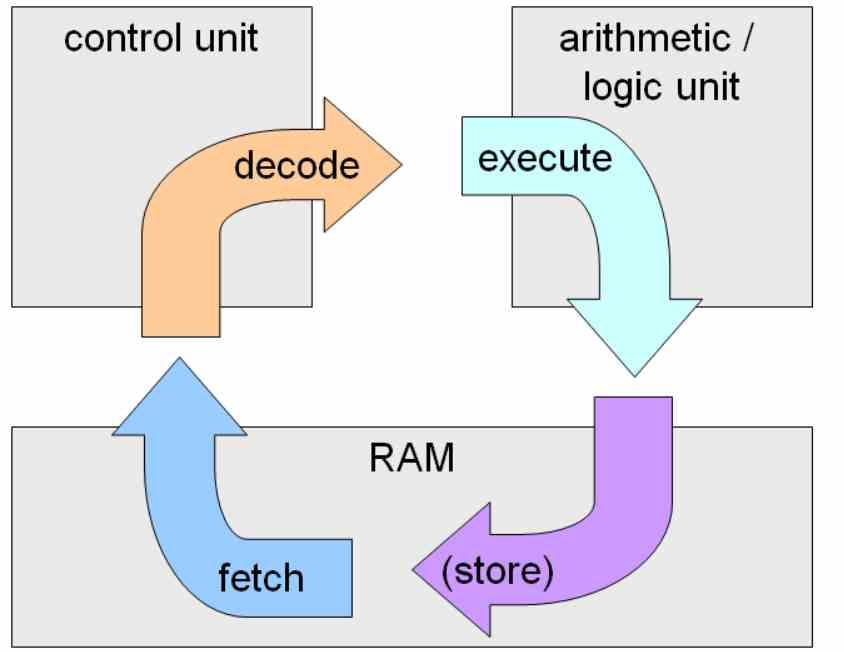
Exekvering i ordning är den klassiska instruktionskörningen, namnet beror på att instruktionerna exekveras i den ordning de visas i koden och nästa instruktion kan inte fortsätta förrän den tidigare inte har lösts.
Det största problemet med exekvering i beställning är i villkorliga instruktioner och hoppinstruktioner, eftersom detta kommer att utföras när villkoret inträffar, vilket kraftigt saktar ner körkörningshastigheten. Detta är ett stort problem när antalet steg i en processor är extremt högt, vilket är vad som händer när en CPU körs med höga klockhastigheter.
Fällan för att uppnå höga klockhastigheter är att segmentera instruktionernas upplösning maximalt med ett stort antal delsteg i instruktionscykeln. När ett hopp eller ett felaktigt tillstånd inträffar förloras ett stort antal instruktionscykler.
Out-of-order, påskyndar ILP

Out-of-order eller exekvering out of order är det sätt på vilket de mest avancerade processorerna kör koden och man tänker undvika att körningen stoppas. Som namnet antyder består den av att köra instruktionerna från en processor i en annan ordning än de som anges i koden.
Anledningen till att detta görs är att varje typ av instruktion har en typ av exekveringsenhet tilldelad. Beroende på instruktionstyp använder CPU en eller annan typ av exekveringsenhet, men dessa är begränsade. Detta kan orsaka ett stopp i exekveringen, så vad som görs är att avancera nästa instruktion i dess exekvering, peka i ett minne eller internt register som är den verkliga ordningen på instruktionerna, när de har utförts skickas de tillbaka den ursprungliga beställningen att de stod i koden.
Med out-of-order kan du utöka det genomsnittliga antalet instruktioner som lösts per cykel och föra det närmare prestandadealet. Till exempel hade den första Intel Pentium körning i ordning och var en CPU som kunde arbeta med två instruktioner mot 486 som bara kunde fungera med en, men trots detta var dess prestanda på grund av stopp bara 40% extra.
Ytterligare steg för out-of-order
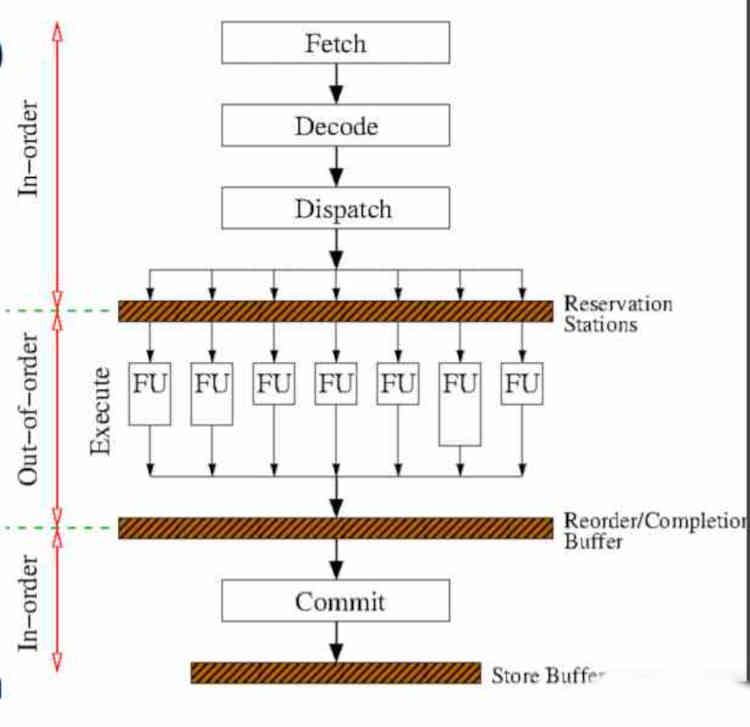
Implementeringen av körning utan ordning lägger till ytterligare steg i instruktionscykeln, som vi redan pratade om i artikeln med titeln Så här kör din CPU instruktionerna från programvaran, som du hittar i HardZone.
Faktum är att endast den centrala delen av utförandet av instruktionen varierar med avseende på exekveringen i ordning, dessa förändringar inträffar före exekveringssteget, så de två första som hämtar och avkodar påverkas inte, men två nya steg är läggs till, som inträffar före och efter genomförandet av instruktionerna.
Det första steget är standby-stationerna, där hårdvaran väntar på att exekveringsenheterna ska vara gratis. Dess implementering är komplex, eftersom den är baserad på en mekanism som inte bara tittar på när en exekveringsenhet är fri utan också räknar den genomsnittliga varaktigheten i klockcykler för varje instruktion som utförs för att veta hur den måste ordna instruktionerna.
Det andra steget är omordningsbufferten, som ansvarar för att sortera instruktionerna i utmatningsordning. Tänk på att alla spekulativa instruktionsgrenar i koden körs för att påskynda utmatningen av instruktionerna vid körning utanför ordning. Den spekulativa instruktionen är den som ges när det sker ett villkorligt hopp oavsett om villkoret är uppfyllt eller inte. Så det är i detta skede som obekräftade avrättningsgrenar kasseras.