С самого начала использования персональных компьютеров его основной способ связи с нами - через экран, поэтому несколько раз в секунду ПК должен генерировать изображение, которое должно быть представлено пользователю в качестве информации. Но КАК do домен ЦП и GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР общаться так что последний генерирует следующее изображение, которое будет отображаться на экране?
Связь CPU и GPU: кольцевой буфер

ЦП формирует список графических команд, которые говорят ГП, как сгенерировать следующий кадр. Для каждого нового кадра создается новый список команд, который мы также называем Display List (список отображения на испанском языке).
Приложение, отвечающее за создание кадра, - это то, что мы называем графическим API, эти API - это абстракции того, что представляет собой графический процессор на уровне языка программирования, которые помогают приложениям взаимодействовать с графической картой. Его функция состоит в том, чтобы преобразовать список действий, которые приложение отправляет, во что-то, что понимает сам графический процессор, и для этого необходим другой участник, который является контроллером самого графического процессора или драйвером, программой, которая используется для переноса из этого процесса преобразования в код, который может понять наш конкретный графический процессор.
После того, как этот список был сгенерирован, чтобы графический процессор мог его понять, он сохраняется в части системного Оперативная память. Графический процессор через специальный блок, называемый DMA, который позволяет ему читать не только VRAM, но и системную RAM, откуда он будет читать список отображения, сгенерированный процессором.
Графический процессор обрабатывает область памяти, в которой расположен список отображения, как кольцо, то есть, когда он достигает последнего адреса памяти, назначенного кольцу, когда он читает следующую инструкцию, счетчик программ автоматически сбрасывается на 0 и так далее. Другими словами, он всегда проходит через одни и те же адреса памяти, и каждое полное кольцо является фреймом, поэтому, когда командный процессор графического процессора достигает конца кольца данных или буферного кольца, он начинает с нуля, и с этого начинается новый фрейм. .
Командный процессор GPU
Командный процессор (CP) является проводником графического процессора, он всегда находится в центральной части каждого графического процессора, независимо от его архитектуры, и отвечает за управление графическим процессором и выполнение задач в правильном порядке, правильно и с правильными ресурсами.
Первоначально он копирует список команд из кольцевого буфера в память рядом с командным процессором, чтобы вы могли работать с ним как можно быстрее. Как только это будет сделано, он начинает генерировать фрейм, упорядочивающий различные элементы графического процессора, пока выполняется список инструкций.
Способ, которым CP обрабатывает список команд, сгенерированный ЦП, относится к типу FIFO: английский «первым пришел - первым ушел» («Первым пришел - первым пришел - первым ушел»), это означает, что элемент, который первым входит в очередь, будет уходящий первым и входящий последним будет уходить последним.
Графика против вычислений
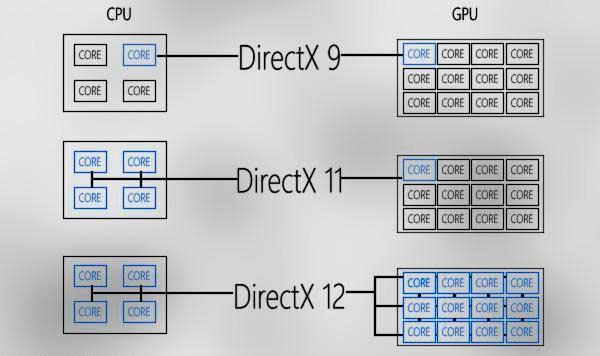
С появлением DirectX 11 графические процессоры стали иметь возможность выполнять небольшие программы, не связанные с рендерингом графики, которые называются вычислительными шейдерами. Проблема в DX11 заключается в том, что, хотя у нас есть несколько разных контекстов, генерируемых ЦП, но на уровне графического процессора было только гигантское кольцо, поэтому вычислительные задачи, которые должны были выполняться, зависели от способности графического процессора завершить рендеринг вовремя, это было от DX12, что можно было использовать несколько контекстов и, следовательно, несколько звонков одновременно.
Обычно используются два разных типа колец, одно для вычислений, а другое для графики, обычно одно кольцо используется для графики, но если мы хотим визуализировать в стерео, например, для виртуальной реальности. тогда нас интересуют два кольца команд для графики.
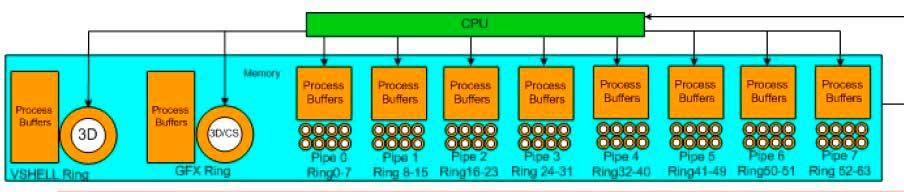
В случае колец для вычислений все по-другому, и они обычно состоят из нескольких подколец, и их выполнение полностью асинхронно с рендерингом изображения, поэтому начало и конец списков вычислений не зависят от начала и конец кадра.
Когда у нас есть вычислительные кольца, работающие параллельно с графическими кольцами, тогда у нас есть не один, а несколько командных процессоров, но тот, который всегда имеет предпочтение, - это графическое кольцо, если мы не обнаружим себя с ослепленным графическим процессором, и поэтому он используется для задач, отличных от создание графики, например, для использования в научных вычислениях.
