Introducerea recentă și lansarea iminentă a AMD Seria de procesoare Ryzen 5000, bazată pe arhitectura Zen 3, a fost însoțită de coroana pentru AMD, cel puțin pentru moment, când vine vorba de putere. Dar ce face ca arhitectura Zen 3 să fie atât de rapidă? Ce elemente ați adăugat în a treia generație de arhitectură Zen pentru performanțe mai bune?
Înainte de a începe, trebuie remarcat faptul că Ryzen 5000 nu sunt succesorii direcți ai AMD Ryzen 4000 , care sunt SoC monolitice, ci mai degrabă Ryzen 3000, din moment ce Ryzen 5000 sunt, de asemenea, sisteme MCM pe baza de cipituri.

În acest sistem, avem pe de o parte IOD unde Northbridge a sistemului este localizat , botezat ca Scalable Data Fabric sau SDF de AMD și Southbridge numit IO Hub de către compania Ryzens și Radeons. Acest IOD nu sa schimbat în ceea ce privește Ryzen 3000, cu excepția faptului că suportă amintiri mai rapide, deoarece prin IOD nucleele au acces la RAM a sistemului.

Cu toate acestea, nu putem spune că au luat IO Die al Ryzen 3000 așa cum este și l-au transplantat așa cum este, ci că l-au îmbunătățit prin experiența lor atunci când au creat Ryzen 4000 pentru computere cu un consum mai mic decât un desktop PC.
Deci, acolo unde au fost schimbări cu adevărat importante sunt în CCD sau Core Complex Die , micul cip care stochează diferitele nuclee și ierarhia cache-lor, care a avut loc cele mai importante schimbări.
Noua arhitectură Core Complex Die of Zen 3
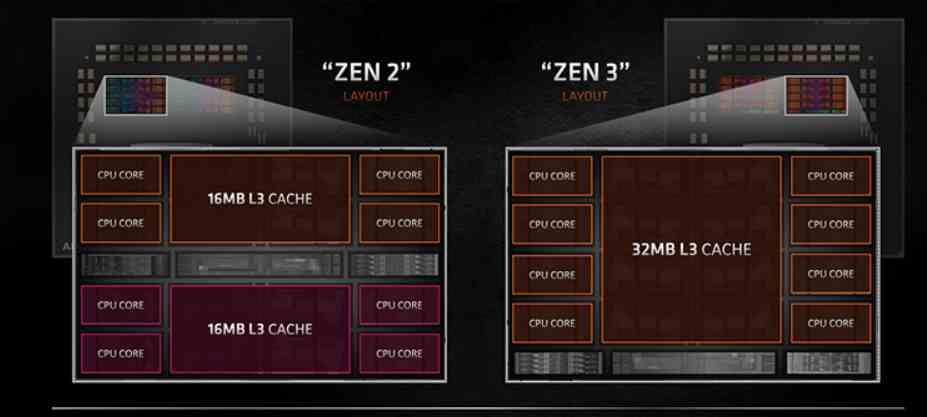
CCD în Zen 2 a fost inventat din două CCX-uri cu 4 nuclee fiecare, cu a lor Memoria cache L3 partajată în fiecare dintre CCX-uri . ceea ce cauzează o serie de probleme de latență atunci când mai multe nuclee din același CCD, dar în CCX diferite au trebuit să comunice, deoarece dacă un nucleu trebuia să comunice cu altul care se afla în celălalt CCX, atunci ar trebui să treacă prin IOD, în ciuda faptului că se află pe același CCD.
Schimbarea pe care AMD a făcut-o în arhitectura Zen 3 este foarte simplă, au făcut ca 8 nuclee să împartă memoria cache L3 în loc de 4 nuclee în același timp . Deci, am trecut de la a avea 2 CCX-uri cu 4 nuclee per CCD la 1 CCX cu 8 nuclee per CCD . Aceasta în aplicațiile destinate să ruleze cu 8 sau mai puține nuclee are ca rezultat un avantaj de performanță.
Dar unde A MD a făcut îmbunătățiri la nivelul fiecărui nucleu se află în Încărcați / stocați unitățile , precum și în front-end sau unitate de control , îmbunătățiri care au fost esențiale pentru obținerea unei performanțe medii cu 19% peste predecesorul său, Zen 2.
Cheia este unitatea de control
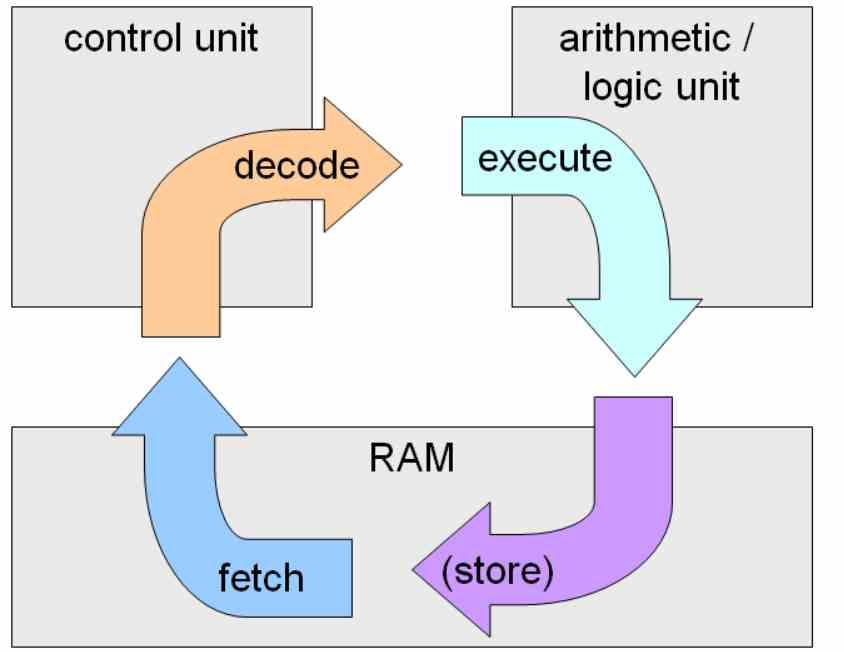
Când vorbim Front-End ne referim la unitatea de control a Procesor, în timp ce ALU-urile sunt back-end-ul. În cadrul ciclul de instruire , fetch-decode-execute, primele două etape sunt lucrările unității de comandă , în timp ce a doua parte este opera ALU-urilor sau a unităților de execuție.
TOATE x86 contemporan procesoarele nu executați instrucțiunile de la ISA menționat , dar în schimb decriptați instrucțiunile într-un ISA RISC intern acolo se execută de fapt instrucțiunile în unitățile de execuție. Acest ISA intern se poate schimba chiar și între membrii aceleiași arhitecturi și este esențial la creșterea IPC a procesoarelor.
Acesta este motivul pentru care AMD a refăcut unitatea de control și a implementat un ISA intern nou, mult mai eficient care permite efectuarea instrucțiunilor în mai puține cicluri de ceas pe instrucțiune (CPI), determinând creșterea numărului mediu de instrucțiuni pe ciclu odată cu aceasta. .
