
O primeiro processador com execução fora de ordem foi o IBM POWER 1, que seria a base para os processadores RISC de mesmo nome e os PowerPCs. Intel adotou esta tecnologia para o x86 em seu Pentium Pro. Desde então, todas as CPUs do PC fazem uso da tecnologia out-of-order como uma das bases para obter o máximo desempenho possível.
A principal preocupação no projeto de processadores geralmente não é obter o máximo de potência, mas o melhor desempenho ao executar as instruções. Entendemos desempenho como o fato de se aproximar do ideal teórico de funcionamento de um processador. É inútil ter o mais poderoso CPU se, devido às limitações, a única coisa que ela tem é o potencial de ser e não é.
Duas maneiras de lidar com o paralelismo
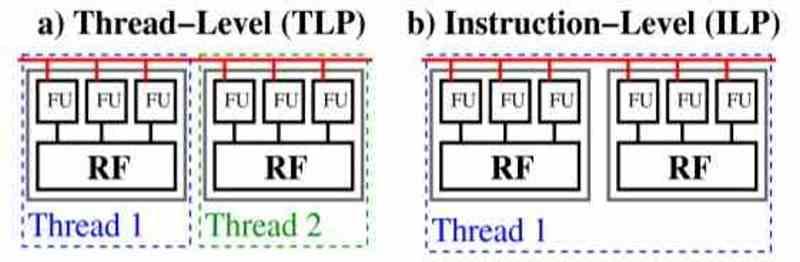
Existem duas maneiras de tratar o paralelismo no código de um programa: paralelismo em nível de thread ou ILP e paralelismo instrucional ou TLP.
No TLP, o código é dividido em vários subprogramas, que são independentes uns dos outros e funcionam de forma assíncrona, ou seja, cada um deles não depende do código dos demais. Quando estamos em um processador TLP, a chave é que, se uma parada de execução ocorrer por algum motivo, o processador TLP pega outro dos threads de execução e coloca o ocioso em espera.
Os processadores ILP são diferentes, seu paralelismo está no nível de instrução e, portanto, no mesmo thread de execução, portanto, eles não podem trapacear colocando o thread principal em espera. Hoje em dia, as CPUs combinam os dois tipos de execução, mas o ILP ainda é exclusivo das CPUs e é onde elas obtêm uma grande vantagem em termos de código serial sobre o código totalmente paralelizável.
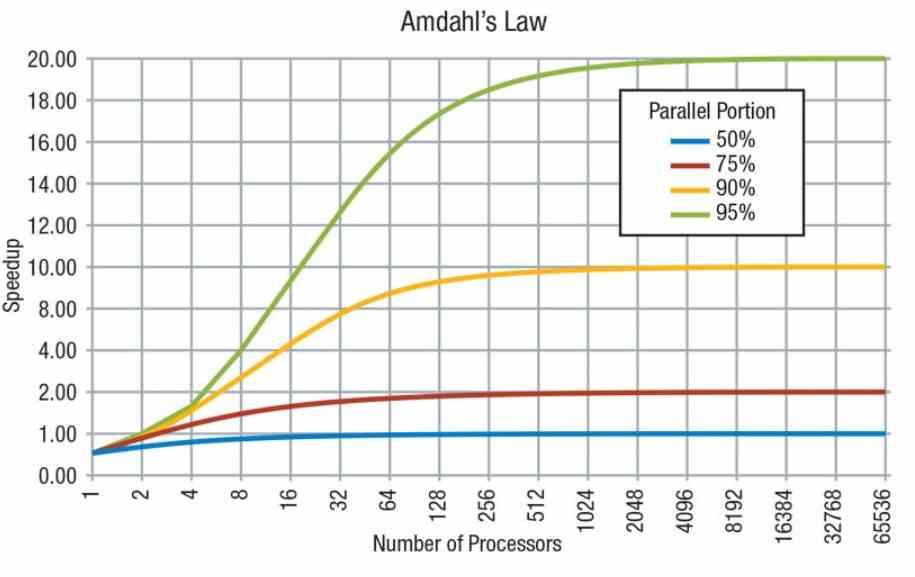
Não podemos esquecer que de acordo com a Lei de Amdahl, um código é composto por partes em série, que só podem ser executadas por um processador, e em paralelo, que podem ser executadas por vários processadores. No entanto, nem tudo pode ser paralelizado e há partes seriais do código que requerem operação serial.
Nos últimos 15 anos foi desenvolvido o conceito em que algoritmos paralelos são executados em GPUs, cujos núcleos são do tipo TLP, enquanto o código serial é executado em CPUs que são do tipo ILP.
Execução de instruções em ordem
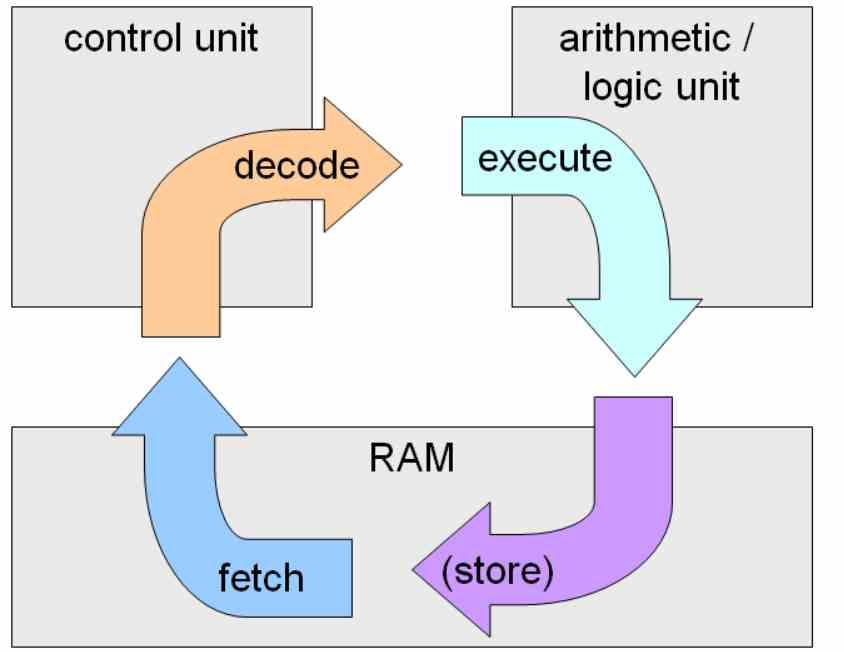
A execução em ordem é a execução de uma instrução clássica, seu nome se deve ao fato de que as instruções são executadas na ordem em que aparecem no código e a próxima instrução não pode continuar até que a anterior não seja resolvida.
A maior dificuldade da execução em ordem está nas instruções condicionais e de salto, pois elas serão executadas quando a condição ocorrer, diminuindo muito a velocidade de execução do código. Este é um grande problema quando o número de estágios em um processador é extremamente alto, que é o que acontece quando uma CPU funciona em altas velocidades de clock.
A armadilha para atingir altas velocidades de clock é segmentar a resolução das instruções ao máximo com um grande número de subestágios do ciclo de instrução. Quando ocorre um salto ou uma condição errada, um número considerável de ciclos de instrução é perdido.
Fora de ordem, acelerando o ILP

Fora de ordem ou execução fora de ordem é a forma como as CPUs mais avançadas executam o código e se pretende evitar que a execução pare. Como o próprio nome indica, consiste em executar as instruções de um processador em uma ordem diferente das indicadas no código.
Isso é feito porque cada tipo de instrução possui um tipo de unidade de execução atribuída a ela. Dependendo do tipo de instrução, a CPU usa um ou outro tipo de unidade de execução, mas são limitados. Isso pode causar uma parada na execução, então o que se faz é avançar a próxima instrução em sua execução, apontando em uma memória ou registro interno que é a ordem real das instruções, uma vez que tenham sido executadas são reenviadas em a ordem original em que estavam no código.
Usar fora de ordem permite expandir o número médio de instruções resolvidas por ciclo e aproximá-lo do desempenho ideal. Por exemplo, o primeiro Intel Pentium tinha execução em ordem e era um CPU capaz de trabalhar com duas instruções contra o 486 que só funcionava com uma, mas apesar disso seu desempenho devido a paradas era apenas 40% adicional.
Estágios adicionais para fora de ordem
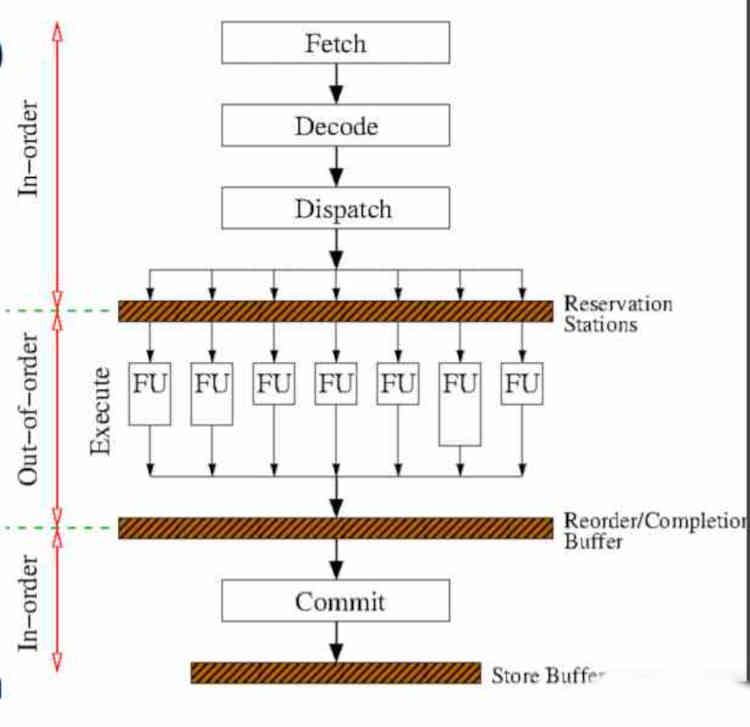
A implementação da execução fora de ordem adiciona estágios adicionais ao ciclo de instrução, sobre o qual já falamos no artigo intitulado É assim que sua CPU executa as instruções fornecidas pelo software, que você pode encontrar no HardZone.
Na verdade, apenas a parte central da execução da instrução varia em relação à execução na ordem, essas mudanças ocorrem antes do estágio de execução, então os dois primeiros que são buscar e decodificar não são afetados, mas dois novos estágios são adicionados, que ocorrem antes e depois da execução das instruções.
O primeiro estágio são as estações de standby, onde o hardware espera que as unidades de execução fiquem livres. Sua implementação é complexa, pois se baseia em um mecanismo que não só observa quando uma unidade de execução está livre, mas também conta a duração média em ciclos de clock de cada instrução que está sendo executada para saber como deve reordenar as instruções.
O segundo estágio é o buffer de reordenamento, que se encarrega de ordenar as instruções na ordem de saída. Lembre-se de que, para acelerar a saída das instruções na execução fora de ordem, todos os ramos de instrução especulativos no código são executados. A instrução especulativa é aquela que é dada quando há um salto condicional, independentemente de a condição ser atendida ou não. Portanto, é neste estágio que os ramos de execução não confirmados são descartados.