
Algumas semanas atrás, uma patente atribuída a AMD foi publicado, ele explica como funcionarão suas GPUs divididas em vários chips, o que será uma regra geral não só para eles, mas também para a concorrência. Onde sabemos disso NVIDIA Hopper e Intel O Xe-HP está dividido em vários chips. Mas a solução da AMD é um pouco diferente da proposta por seus concorrentes, explicamos a patente dos chips AMD.
O motivo pelo qual as GPUs duplas desapareceram do ambiente doméstico e é a resposta à pergunta de por que não vemos mais placas de vídeo compatíveis com NVIDIA SLI ou AMD Crossfire é o mesmo: os aplicativos que usamos em nossos PCs são programados para usar um único GPU.

Em videogames para PC, ao fazer uso de uma GPU dupla. Técnicas como a Renderização de Quadro Alternativo são usadas, em que cada GPU renderiza um quadro alternativo em relação ao outro, ou Renderização de Quadro Dividido, onde o par de GPUs divide o trabalho de um único quadro.
Na computação via GPU esse problema não ocorre, por isso, em sistemas nos quais as placas gráficas não são utilizadas para renderizar gráficos, encontramos várias delas operando em paralelo sem problemas. Além do mais, os aplicativos que usam GPUs como processadores de dados paralelos já foram projetados para aproveitar as vantagens das GPUs dessa forma.
O aumento no tamanho das GPUs nos últimos anos

Se olharmos para a evolução das GPUs nos últimos anos, veremos que houve um crescimento considerável na área de GPUs top de linha de uma geração para a outra.
O pior do cenário atual? Ainda não existe uma GPU com o desempenho ideal para jogos em 4K. Deve-se levar em consideração que uma imagem 4K nativa tem 4 vezes mais pixels do que uma em 1080p e, portanto, estamos falando de uma movimentação de dados quatro vezes maior que a necessária para Full HD.
Na situação atual em VRAM, temos o caso do GDDR6, dita memória usa uma interface de 32 bits por chip, dividida em dois canais de 16 bits, mas, com uma velocidade de clock que faz com que seu consumo de energia dispare, o que leva a procurar outras soluções para expandir a largura de banda.
Expandindo a largura de banda de VRAM

Se quisermos expandir a largura de banda, existem duas opções:
- A primeira é aumentar a velocidade do clock da memória, mas deve-se levar em consideração que a tensão é elevada ao quadrado quando o MHz desta aumenta, e com ela o consumo de energia.
- A segunda é aumentar o número de pinos, que passaria de 32 bits para 64 bits.
Não podemos esquecer coisas como o PAM-4 usado no GDDR6X também, mas isso foi um movimento da Micron para evitar atingir altas velocidades de clock. Portanto, um barramento de 64 bits por chip VRAM deve ser esperado para um possível GDDR7.
Não sabemos o que os fabricantes de VRAM farão, mas aumentar a velocidade do clock não é a opção que achamos que eles vão adotar dentro de um orçamento de energia limitado.

Não sabemos o que os fabricantes de VRAM farão, mas aumentar a velocidade do clock não é a opção que achamos que eles vão adotar.
No entanto, as interfaces entre a GPU e a VRAM estão localizadas fora do perímetro da própria GPU. Portanto, aumentar o número de bits dele é expandir a periferia da referida GPU e, portanto, torná-la maior.
O que é um sério de problemas agregados devido ao grande tamanho em termos de custo, isso obrigará os fabricantes de placas de vídeo a usar vários chips em vez de um, e é neste ponto que entramos nos chamados chips.
Tipos de GPU baseados em chips

Existem duas maneiras de dividir uma GPU em chips:
- Dividindo uma única GPU de tamanho massivo em vários chips, a compensação disso é que a comunicação entre as diferentes partes requer largura de banda massiva que pode não ser viável sem o uso de intercomunicadores especiais.
- Use vários GPUS no mesmo espaço que funcionam juntos como um.
No artigo HardZone intitulado “É assim que serão as GPUs baseadas em chips que veremos no futuro” você pode ler sobre a configuração do primeiro tipo, enquanto a patente da AMD sobre sua GPU com chips se refere às do segundo tipo .
Explorando a patente para chips AMD:
O primeiro ponto que aparece em toda patente é a utilidade da invenção, que vem sempre em seu pano de fundo, o que nos preocupa é o seguinte:
Projetos monolíticos convencionais que estão se tornando cada vez mais caros de fabricar. Chiplets têm sido usados com sucesso em CPU arquiteturas para reduzir o custo de fabricação e melhorar os rendimentos. Já sua natureza computacional heterogênea se adapta mais naturalmente para separar núcleos de CPU em unidades diferentes que não requerem muita intercomunicação entre eles.
A menção de CPUs é claro que se refere a AMD Ryzen e é que uma boa parte da equipe de design de arquiteturas Zen foi deslocada para o Radeon Technology Group para trabalhar no aprimoramento da arquitetura RDNA. O conceito de chips não é o primeiro herdado do Zen, o outro é o Cache Infinity, que herda o conceito de “Victim Cache” do Zen.
Em segundo lugar, o problema de intercomunicação ao qual você se refere refere-se à enorme largura de banda de que as GPUs precisam para comunicar seus elementos entre si. Qual é o impedimento face à construção destes em chips, devido à energia consumida na transferência dos dados.
O trabalho de uma GPU é paralelo por natureza. No entanto, a geometria que é processada por uma GPU não inclui apenas seções de trabalho em paralelo, mas também trabalhos que precisam ser sincronizados em uma ordem específica entre as diferentes seções.
A consequência disso? Um modelo de programação para uma GPU que distribui o trabalho entre diferentes threads é muitas vezes ineficiente, pois o paralelismo é difícil de distribuir em vários grupos de trabalho e chips é difícil e caro sincronizar o conteúdo da memória de recursos compartilhados no sistema.

A parte que colocamos em negrito é a explicação do ponto de vista do desenvolvimento de software para o qual não vimos GPUs baseadas em chips. Não é apenas um problema de hardware, mas um problema de software, por isso é necessário simplificar.
Além disso, do ponto de vista lógico, os aplicativos são escritos com a visão de que o sistema possui apenas uma GPU. Ou seja, embora uma GPU convencional inclua muitos núcleos de GPU, os aplicativos são programados para atingir um único dispositivo. Portanto, historicamente tem sido um desafio trazer a metodologia de design de chips para arquiteturas de GPU.
Essa parte é a chave para entender a patente, a AMD não está falando em dividir uma única GPU em chips, que é o que faz em suas CPUs, mas sim em usar várias GPUs nas quais cada uma é um chip, é importante manter Lembre-se dessa diferença, já que a solução da AMD parece mais focada na criação de um Crossfire no qual não é necessário que os programadores adaptem seus programas para várias GPUs.
Definido o problema, o próximo ponto é falar sobre a solução oferecida pela patente.
Explorando a Patente do Chiplet AMD: A Solução
A solução para o problema exposto proposta pela AMD é a seguinte:
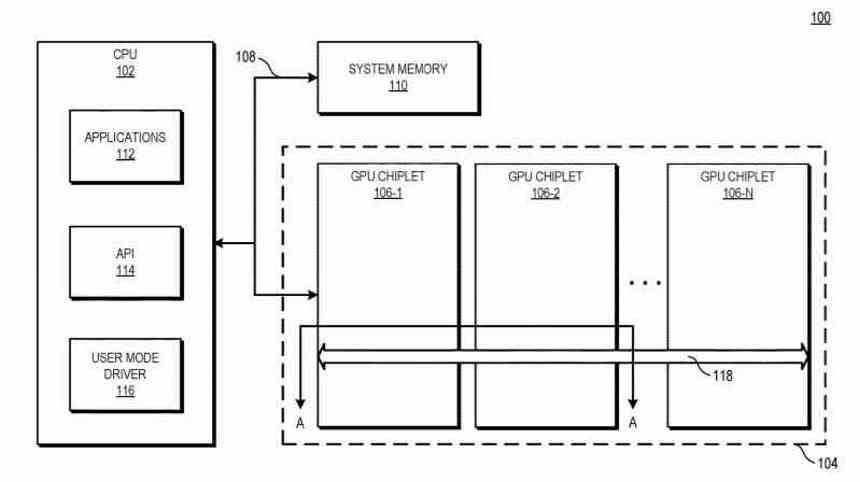
Para melhorar o desempenho do sistema usando chips de GPU enquanto mantém o modelo de programação atual, a patente ilustra sistemas e métodos que usam crosslinks passivos de alta largura de banda para conectar chips de GPU uns aos outros.
O importante da patente são esses Crosslinks, dos quais falaremos mais adiante neste artigo, são a interface de comunicação entre os diferentes chips, ou seja, como a informação é transmitida entre eles.
Em várias implementações, um sistema inclui a unidade de processamento central (CPU) que está conectada ao primeiro chiplet de GPU na cadeia, que está conectado a um segundo chiplet por meio da reticulação passiva. Em algumas implementações, o crosslink passivo é um mediador passivo que lida com a comunicação entre chips .
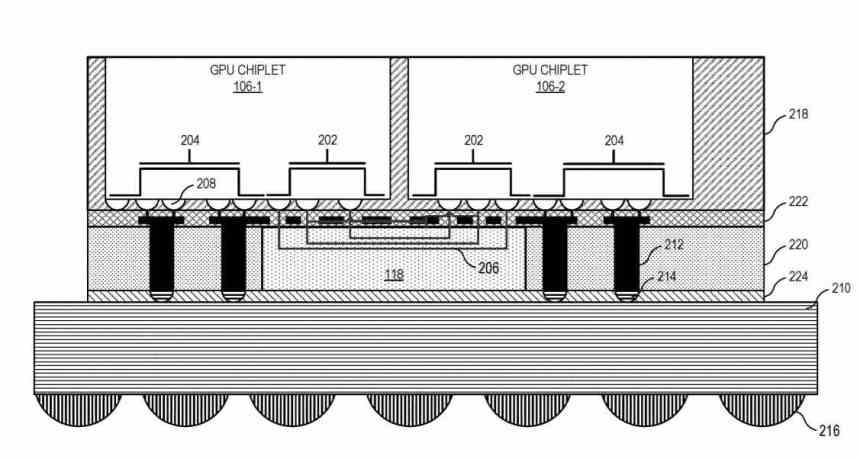
Basicamente, tudo se resume ao fato de que agora temos um GPU dual funcionando como um, que é composto por dois chips interconectados através de um interposer que estaria localizado abaixo.
Crosslinks passivos de alta largura de banda
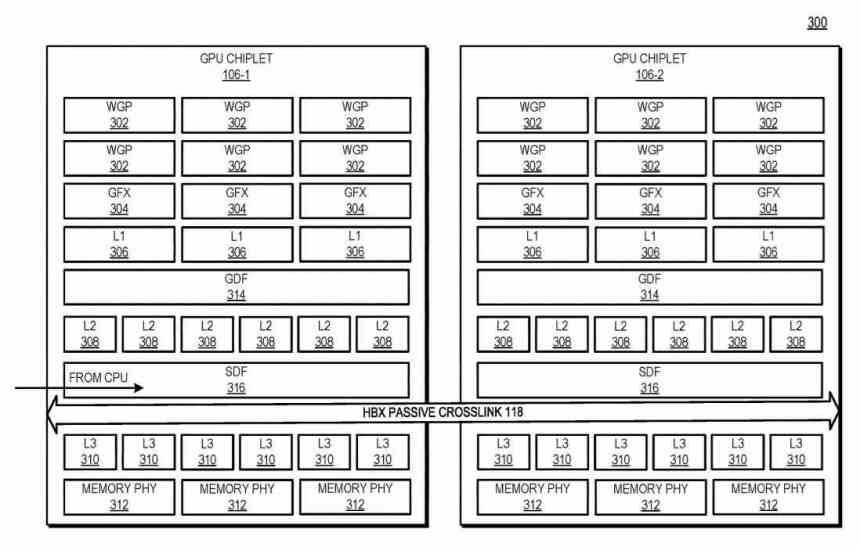
Como os chips se comunicam com o mediador? Usando um tipo de interface que comunica o Scalable Data Fabric (SDF) de cada um dos chips entre si, o SDF em GPUs AMD é a parte que normalmente fica entre o cache de nível superior da GPU e a interface. memória, mas neste caso há um cache L3 entre o SDF de cada chip da GPU e o SDF e antes disso uma interface que intercomunica os dois chips um com o outro.
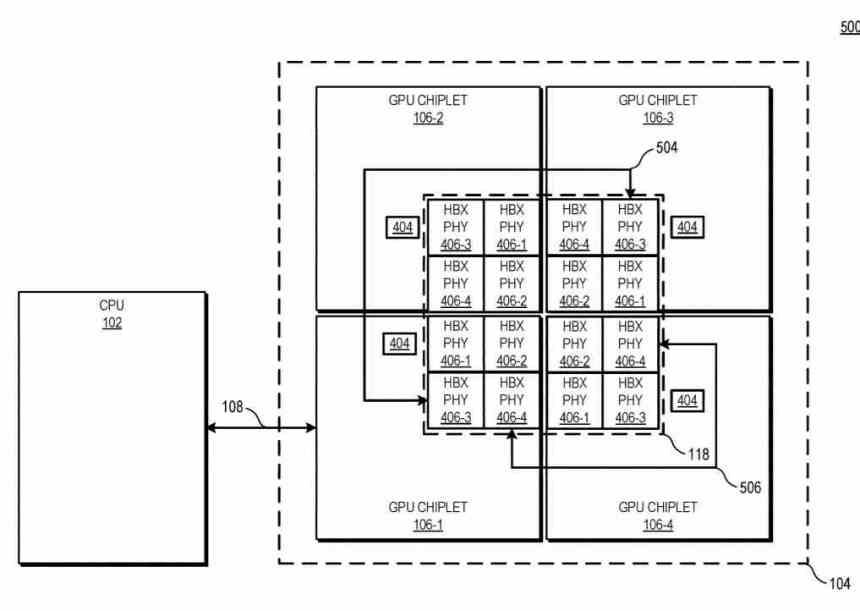
Neste diagrama, você pode ver o exemplo com 4 chips de GPUs, o número de interfaces HBX é sempre 2 2 em que n é o número de chips no mediador. Olhando para o nível da hierarquia do cache, L0 (não descrito na patente) é local para cada Unidade de Computação, L1 para cada Shader Array, L2 para cada chip de GPU, enquanto o cache L3 seria uma novidade, isso é descrito como o cache de último nível ou LCC de todo o conjunto de GPU.
Atualmente, várias arquiteturas têm pelo menos um nível de cache que é consistente em toda a GPU. Aqui, em uma arquitetura de GPU baseada em chip, ele coloca esses recursos físicos em chips separados e os comunica de tal forma que o cache de nível superior permanece consistente em todos os chips de GPU. Portanto, apesar de operar em um ambiente massivamente paralelizado, o cache L3 deve ser consistente.
Durante uma operação, a solicitação de um endereço de memória da CPU para a GPU é transmitida para um único chip de GPU, que se comunica com o crosslink passivo de alta largura para localizar os dados. Do ponto de vista da CPU, parece que você está se dirigindo para uma GPU monolítica de um único chip. Isso permite o uso de uma GPU de alta capacidade, composta por vários chips como se fosse uma única GPU para a aplicação.
É por isso que a solução da AMD não é a divisão de uma GPU em vários chips diferentes, mas o uso de vários GPUs como se fossem um, resolvendo assim um dos problemas que o AMD Crossfire trouxe com ele e permitindo que qualquer software possa usar vários GPUs ao mesmo tempo como se fossem uma e sem ter que adaptar o código.
A outra chave para crosslinks passivos é o fato de que ao contrário do que muitos de nós especulamos, eles não se comunicam com a GPU usando canais através de silício ou TSV, mas que a AMD criou uma intercomunicação proprietária para a construção de SoCs. , CPUs e GPUs, tanto em 2.5DIC como em 3DIC, o que nos leva a questionar se a interface X3D que tem que substituir seu Infinity Fabric.
Os chips AMD são para RDNA 3 em diante

O fato de o problema na utilização de várias GPUs não ser um problema de aplicativos projetados para computação através de GPUs deixa bem claro que a solução proposta pela AMD em sua patente é voltada para o mercado nacional, especificamente GPUs de arquiteturas RDNA, há várias pistas sobre isso:
- Nos diagramas dos chips da patente, aparece o termo WGP, que é típico da arquitetura RDNA e não do CDNA e / ou GCN.
- A menção em uma parte da patente do uso de memória GDDR, que é típica para GPUs domésticas.
A patente não descreve uma GPU específica para nós, mas podemos assumir que a AMD lançará a primeira GPU dupla baseada em chip quando o RDNA 3 for lançado. Isso permitirá que a AMD crie uma única GPU em vez de diferentes variações de uma arquitetura na forma de chips diferentes, como é o caso hoje.

A solução da AMD também contrasta com os rumores da NVIDIA e da Intel. Desde o início sabemos que Hopper será sua primeira arquitetura baseada em chips, mas não conhecemos seu mercado-alvo, então pode muito bem ser voltado para o mercado de computação de alto desempenho, como jogos.
Quanto à Intel, sabemos que o Intel Xe-HP é uma GPU composta também por chips, mas sem a necessidade de uma solução como a da AMD, já que o alvo da Intel para a referida GPU não é o mercado nacional.
