Infinity Cache to najbardziej zauważalna różnica między niedawno wprowadzonymi kartami graficznymi z serii RX 6000 (RX 6800, RX 6800 XT i RX 6900) a Xbox Seria X SoC GPU, również oparty na RDNA 2. ¿Ale czym dokładnie jest pamięć podręczna Infinity, do czego służy i jak działa? Powiemy Ci wszystkie jego sekrety.
Od tygodni przed prezentacją RX 6000 wiedzieliśmy o istnieniu tej ogromnej puli pamięci wewnątrz GPU, ogromnej, ponieważ mówimy o największej pamięci podręcznej w historii GPU z ok. 128 MB pojemności , Ale AMD nie podał wielu informacji na jego temat, po prostu opowiedział nam o jego istnieniu.

Dlatego konieczne jest szczegółowe wyjaśnienie, aby zrozumieć, dlaczego AMD umieściło pamięć podręczną takiej wielkości w wersji swojego RDNA 2 na PC.
Lokalizowanie Infinity Cache

Pierwszą kwestią, która jest niezbędna do zrozumienia, jaka jest funkcja elementu w sprzęcie, jest wyprowadzenie jego funkcji z jego lokalizacji w systemie.
Ponieważ RDNA 2 to ewolucja RDNA przede wszystkim musimy przyjrzeć się pierwszej generacji obecnej architektury graficznej AMD, z której znamy dwa układy, czyli Navi 10 i Navi 14.
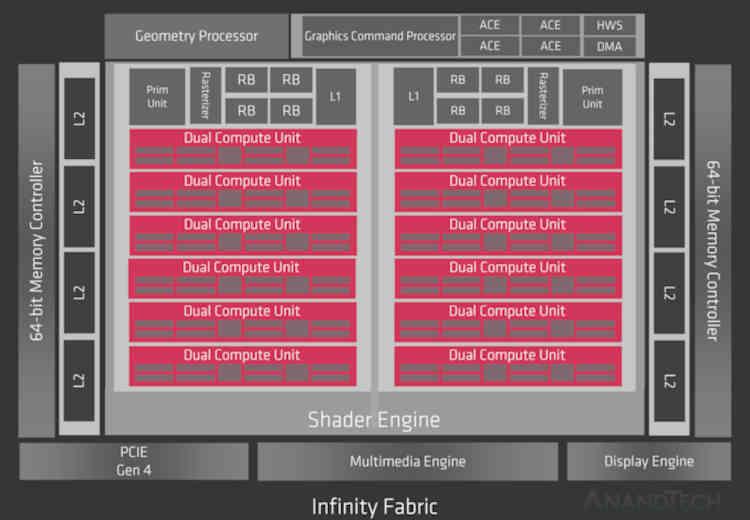
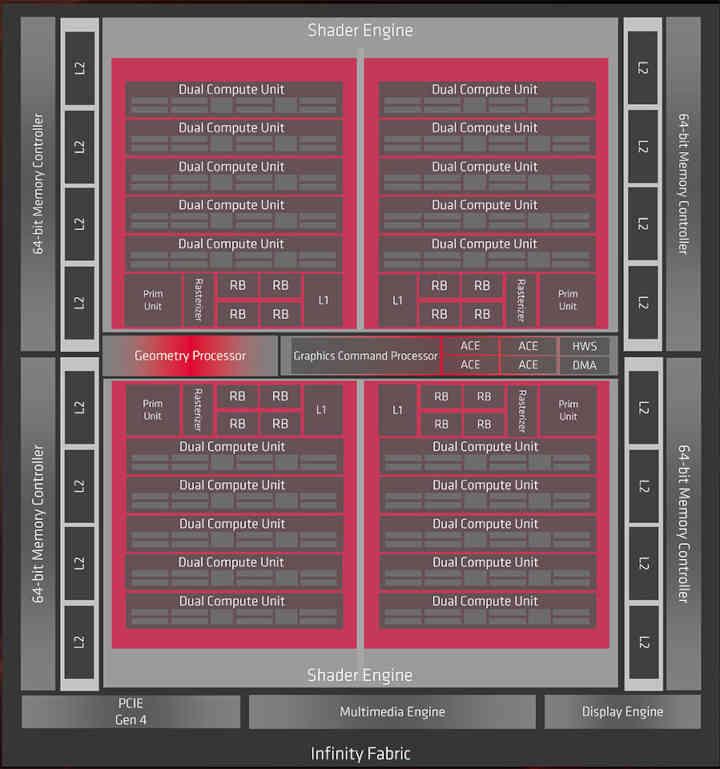
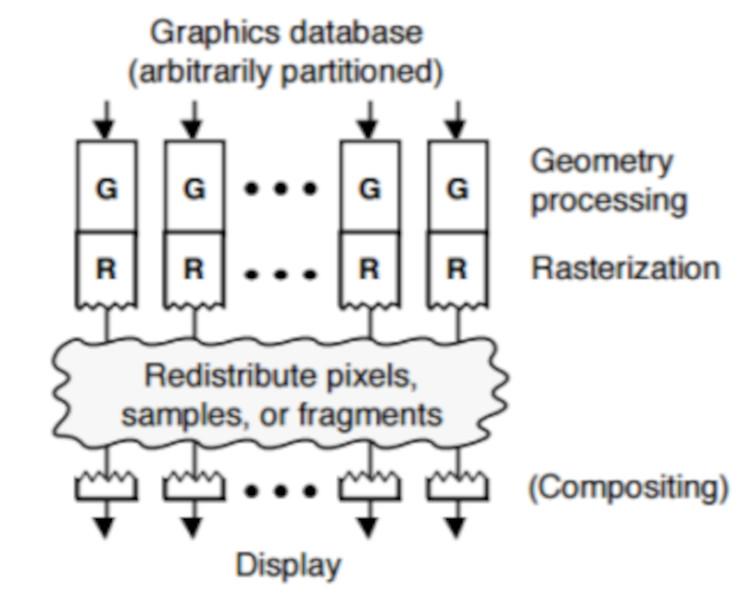
Cóż, gdyby Infinity Cache został zaimplementowany w RDNA, znajdowałby się w części, która mówi Infinity Fabric z diagramu, więc na poziomie organizacji pamięci podręcznej zaczniemy od tego:
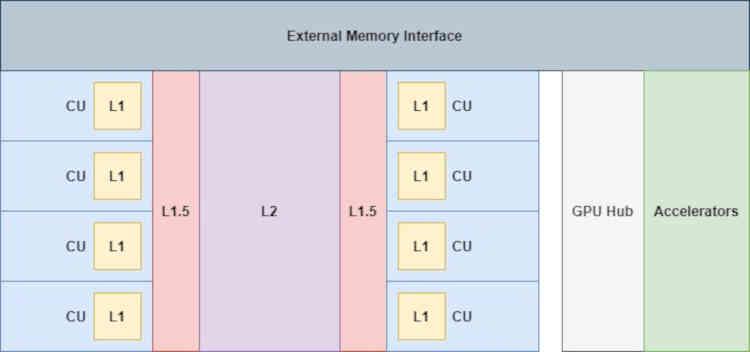
Gdzie akceleratory podłączone do GPU Hub (kodek wideo, kontroler wyświetlacza, dyski DMA itp.) Nie mają bezpośredniego dostępu do pamięci podręcznych, nawet pamięci podręcznej L2.
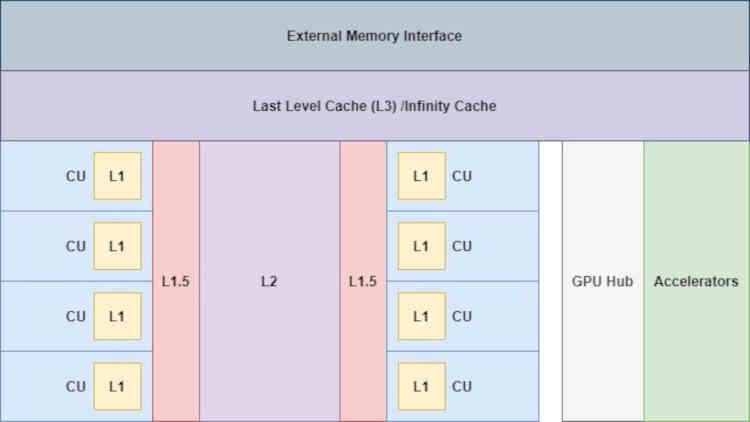
Po dodaniu Infinity Cache rzeczy już się „trochę” zmieniają, ponieważ akceleratory mają teraz dostęp do tej pamięci,
Jest to bardzo ważne, szczególnie w przypadku Display Core Next, który odpowiada za odczyt końcowego bufora obrazu i przesłanie go do odpowiedniego Display Port lub interfejsu HDMI tak, aby obraz był wyświetlany na ekranie, jest to ważne w celu ograniczenia dostępu do pamięci VRAM przez te jednostki.
Pamiętając o systemie pamięci podręcznej RDNA

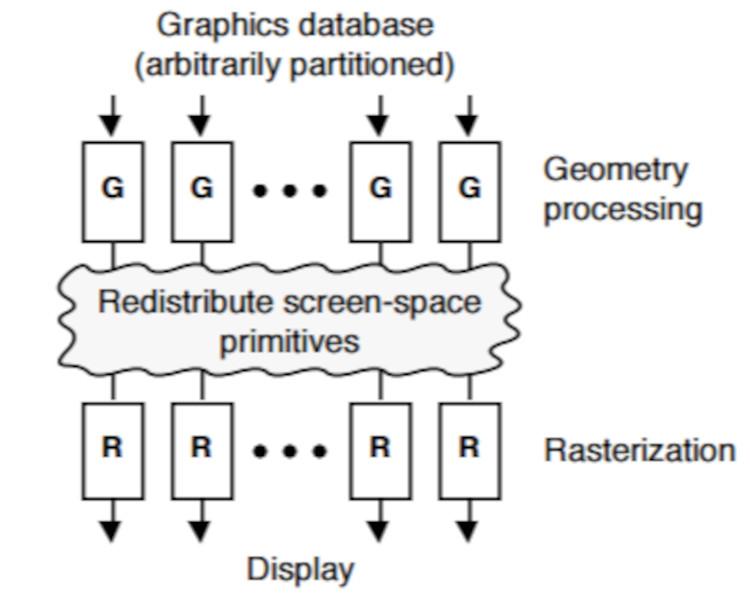
W RDNA pamięci podręczne są połączone ze sobą w następujący sposób:

Pamięć podręczna L2 jest podłączona na zewnątrz do 16 kanałów po 32 bajty / cykl każdy, jeśli spojrzymy na diagram Navi 10, zobaczysz, jak ten GPU ma około 16 partycji pamięci podręcznej L2 i 256-bitowa magistrala GDDR6 do którego są podłączone.
Należy pamiętać, że GDDR6 wykorzystuje 2 kanały na chip które działają równolegle, każdy z 16 bitów.
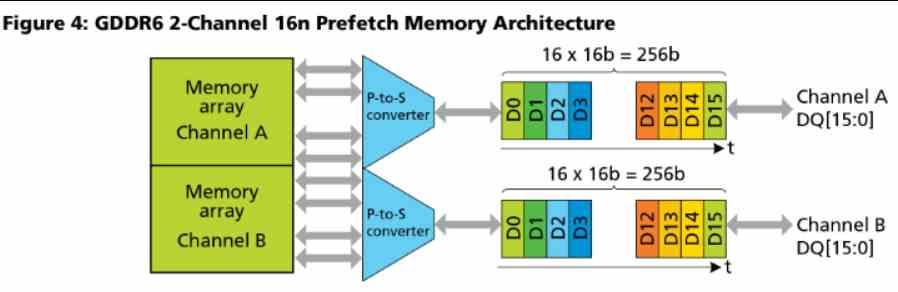
Innymi słowy, liczba partycji pamięci podręcznej L2 w architekturach RDNA jest równa liczbie 16-bitowych kanałów GDDR6 podłączonych do procesora graficznego. W RDNA i RDNA 2 każda partycja ma 256 KB, jest to powód, dla którego Xbox Series X, który ma 320-bitową magistralę, a zatem 20 kanałów GDDR6, ma około 5 MB pamięci podręcznej L2.
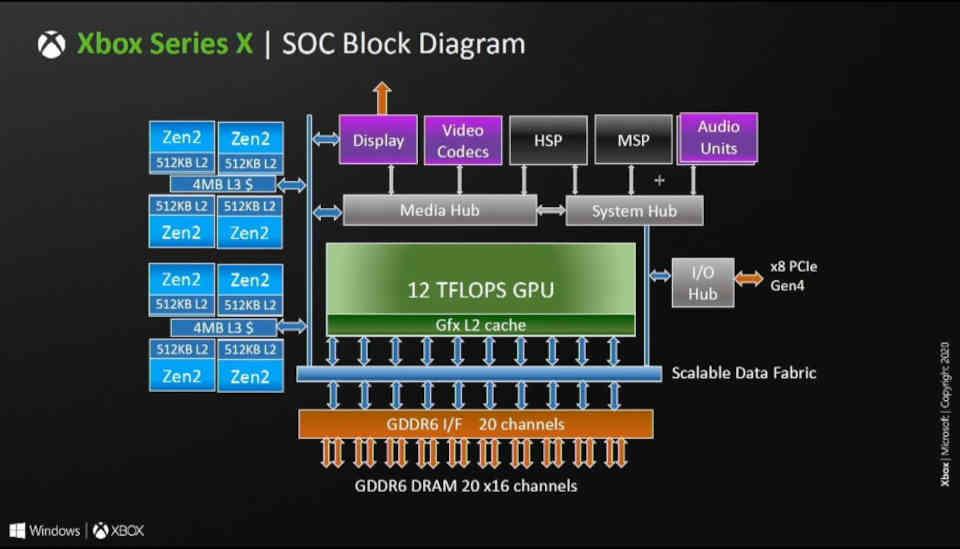
Nowy poziom pamięci podręcznej: Infinity Cache

Ponieważ jest to dodatkowy poziom pamięci podręcznej, Infinity Cache musi być bezpośrednio podłączony do pamięci podręcznej L2, która jest poprzednim poziomem w hierarchii pamięci podręcznej, potwierdza to samo AMD w stopce:
Pomiar obliczony przez inżynierów AMD na karcie z serii Radeon RX 6000 z 128MB Pamięć podręczna AMD Infinity i 256-bitowa pamięć GDDR6. Mierzenie średniego wskaźnika sukcesu AMD Infinity Cache w grach 4k na poziomie 58% w głównych grach, pomnożonego przez teoretyczną maksymalną przepustowość 16 kanałów 64B AMD Infinity Fabric podłączenie pamięci podręcznej do silnika graficznego przy częstotliwości boost do 1.94 GHz.
GPU zastosowane w RX 6800, RX 6800 XT i RX 6900 to Navi 21, który ma 256-bitową magistralę GDDR6, ergo ma 16 kanałów, a zatem 16 partycji Caché L2 jest podłączonych do partycji Infinity Cache.
Jeśli chodzi o kwestię „wskaźników trafień” na poziomie 58%, jest ona bardziej skomplikowana i postaramy się to wyjaśnić poniżej.
Buforowanie kafelkowe na procesorach graficznych NVIDIA

Zanim przejdziemy dalej do Infinity Cache, musimy zrozumieć powody jego istnienia, a w tym celu musimy przyjrzeć się ewolucji GPU w ostatnich latach.
Począwszy od NVIDIA Maxwell, seria GeForce 900, NVIDIA dokonały poważnej zmiany w swoich procesorach graficznych, które nazwali Tile Caching, która polegała na podłączeniu ROPS i jednostki rastrowej do pamięci podręcznej L2.
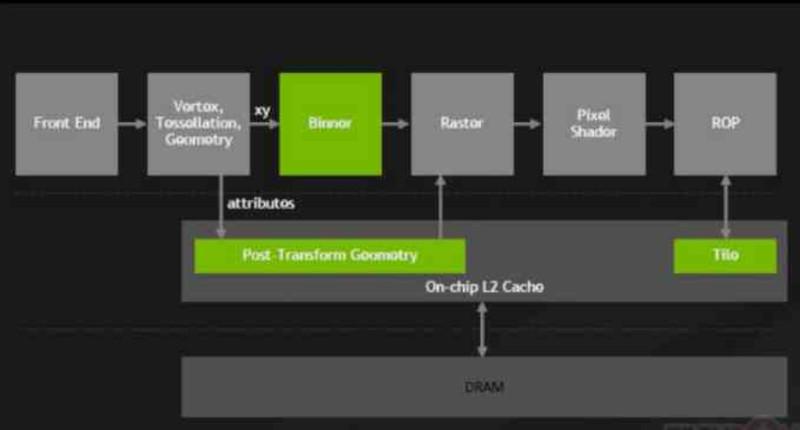
Wraz z tą zmianą ROPS przestał zapisywać bezpośrednio do VRAM, ROPS są wspólne dla wszystkich GPU i są odpowiedzialne za tworzenie buforów obrazu w pamięci.
Dzięki tej zmianie firma NVIDIA była w stanie zmniejszyć wpływ energii na magistralę pamięci poprzez zmniejszenie ilości transferów wykonywanych do iz pamięci VRAM, a dzięki temu NVIDIA zdołała uzyskać efektywność energetyczną od AMD z architekturami Maxwell i Pascal.
DSBR, buforowanie kafelków w procesorach graficznych AMD
Z drugiej strony AMD, podczas wszystkich generacji architektury GCN poprzedzającej Vegę, łączyło Render Backends (RB) bezpośrednio z kontrolerem pamięci.

Ale zaczynając od AMD Vega, wprowadził dwie zmiany w architekturze, aby dodać buforowanie kafelków do swoich GPU, pierwszą z nich było odnowienie jednostki rastrowej, którą nazwał DSBR, Draw Stream Binning Rasterizer.

Druga zmiana polegała na tym, że podłączyli jednostkę rastrową i ROPS do pamięci podręcznej L2, zmiana, która nadal istnieje w RDNA i RDNA 2.
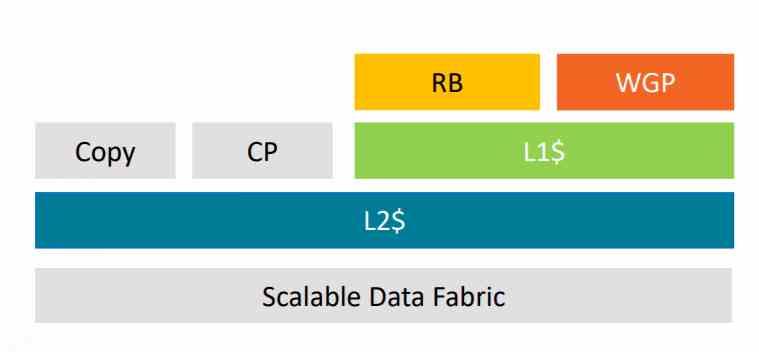
Narzędzie DSBR lub buforowanie kafelków
Tile Caching lub DSBR jest wydajne, ponieważ porządkuje geometrię sceny zgodnie z jej pozycją na ekranie przed rasteryzacją, była to ważna zmiana, ponieważ GPU przed wdrożeniem tej techniki zamówił już teksturowane fragmenty tuż przed wysłaniem ich do bufora obrazu.
W buforowaniu kafelków / DSBR robi się to uporządkuj wielokąty sceny, zanim zostaną zamienione na fragmenty przez jednostkę rasteryzacji.
W pamięci podręcznej kafelków wielokąty są uporządkowane zgodnie z ich pozycją na ekranie w kafelkach, gdzie każdy kafelek jest fragmentem n * n pikseli.
Jedną z zalet tego jest to, że pozwala to z góry wyeliminować niewidoczne piksele fragmentów, które są nieprzezroczyste, gdy znajdują się w tej samej sytuacji. Coś, czego nie można zrobić, jeśli elementy składające się na scenę są uporządkowane po teksturowaniu.
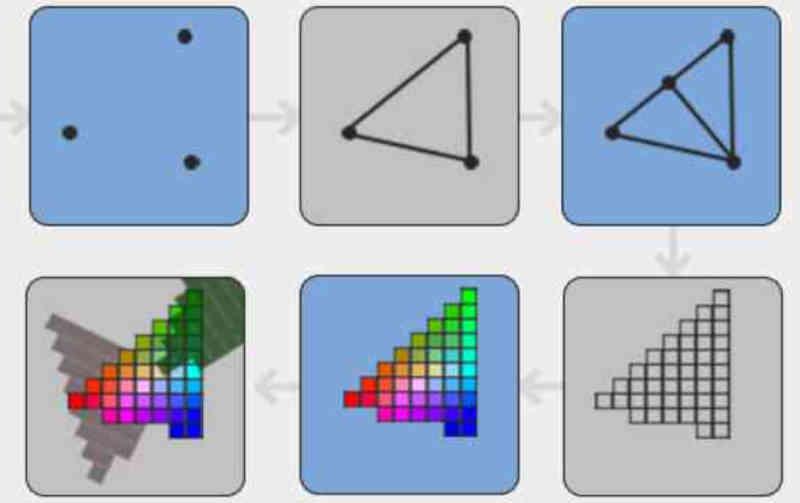
Oszczędza to procesor graficzny przed marnowaniem czasu na zbędne piksele i poprawia wydajność GPU. W przypadku, gdy uznasz to za zagmatwane, wystarczy pamiętać, że w całym potoku graficznym różne prymitywy tworzące scenę przyjmują różne formy na różnych etapach.
Buforowanie kafelków lub DSBR nie jest równoważne z renderowaniem kafelków
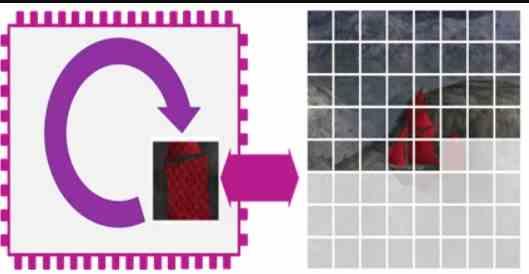
Chociaż nazwa może wprowadzać w błąd, buforowanie kafelków nie jest równoznaczne z renderowaniem kafelków z następujących powodów:
- Mechanizmy renderujące kafelki przechowują geometrię sceny w pamięci, porządkują ją i tworzą listy ekranów dla każdego kafelka. Ten proces nie występuje w przypadku buforowania kafelków lub DSBR.
- W renderowaniu kafelków ROPS są podłączone do pamięci notatnika poza hierarchią pamięci podręcznej i nie opróżniają swojej zawartości do pamięci VRAM, dopóki ten kafelek nie zostanie ukończony w 100%, więc współczynniki trafień wynoszą 100%.
- W przypadku Tile Caching / DSBR, ponieważ ROPS / RB są podłączone do L2 Cache, w dowolnym momencie linie pamięci podręcznej z L2 do RAM mogą zostać odrzucone, więc nie ma gwarancji, że 100% danych znajduje się w pamięci podręcznej L2.
Ponieważ istnieje duże prawdopodobieństwo, że linie pamięci podręcznej trafią do pamięci VRAM, to, co AMD zrobiło z Infinity Cache, polega na dodaniu dodatkowej warstwy pamięci podręcznej, która zbiera odrzucone dane z pamięci podręcznej L2 GPU.
Infinity Cache to Victim Cache
Połączenia Skrzynka ofiar idea jest spuścizną procesorów w architekturze Zen, która została dostosowana do RDNA 2.
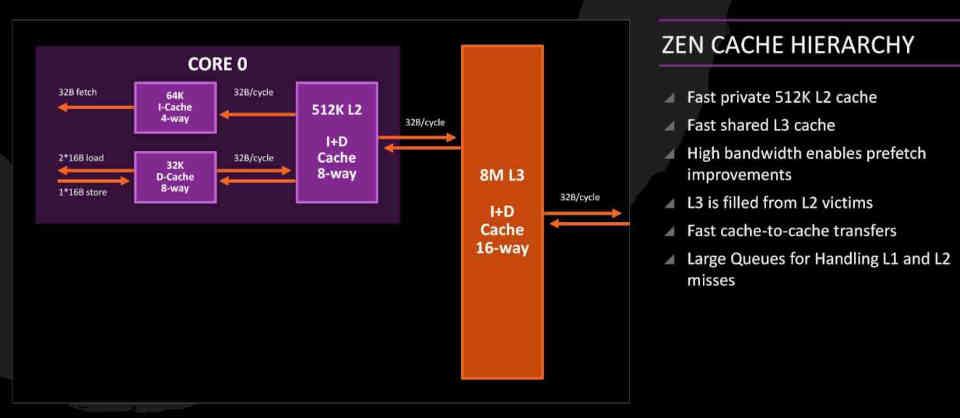

W rdzeniach Zen L3 Cache jest tym, co nazywamy Victim Caché, za które odpowiada zbieranie linii pamięci podręcznej odrzucone z L2 zamiast być częścią tego, co zwykle Pamięć podręczna hierarchia. Oznacza to, że w Zen rdzenie pochodzą z danych RAM nie podąża ścieżką RAM → L3 → L2 → L1 lub odwrotnie, ale zamiast tego podąża ścieżką RAM → L2 → L1, ponieważ pamięć podręczna L3 działa jako pamięć podręczna ofiary.
W przypadku Infinity Cache chodzi o to uratuj linie pamięci podręcznej L2 GPU bez konieczności uzyskiwania dostępu do pamięci VRAM , co pozwala na znacznie mniejszą ilość energii zużywanej na instrukcję, a tym samym pozwala osiągnąć wyższe prędkości. zegar.
Jednak chociaż pojemność 128 MB może wydawać się bardzo wysoka, nie wydaje się wystarczająca, aby uniknąć tego, że wszystkie odrzucone linie trafiają do pamięci VRAM, ponieważ w najlepszych przypadkach udaje się uratować tylko 58% . Oznacza to, że w przyszłych iteracjach architektury RDNA jest to bardzo prawdopodobne AMD zwiększy pojemność tej Infinity Cache .