Når du kjøper en prosessor eller en GPU Vi finner tekniske spesifikasjoner som klokkehastighet, antall flytende punktoperasjoner, minnebåndbredde osv. Men en av måtene å måle ytelse og designe en prosessor har å gjøre med latens i instruksjonene. Vi forklarer hva det er og hvorfor det er så viktig å få raskere CPUer.
Ytelsen til en prosessor fremfor en annen måles av tiden det tar å løse det samme programmet. Dette kan oppnås på mange forskjellige måter, og det er forskjellige måter å øke ytelsen på og dermed redusere tiden det tar å løpe. En av dem er å kutte ventetiden til instruksjonene som utføres. Men hva består den egentlig av?

Hva mener vi med instruksjonsforsinkelse?
Latens er tiden det tar en prosessor å utføre en instruksjon, og dette er variabelt fra hvor dataene er lokalisert, siden jo lenger det er, jo mer tid har det å reise for at disse skal plasseres i de tilsvarende registerene. Det er av denne grunn, og fordi minnet ikke skaleres i samme hastighet som prosessorene, måtte mekanismer som cache opprettes og til og med integrere minnekontrolleren i prosessoren for å redusere ventetiden til instruksjonene.
Imidlertid blir dette vanligvis ikke tatt i betraktning når du selger en CPU og til og med en GPU, andre ytelsesmålinger brukes ofte til å snakke om at en arkitektur er bedre enn en annen. Men ventetiden til instruksjonene brukes vanligvis ikke når du promoterer en prosessor når det er en annen måte å forstå ytelse på.
Klokkesykluser per instruksjon og ventetid

Det første måling av ytelse er sykluser per instruksjon, siden det er instruksjoner som er kompliserte nok til å måtte utføres i flere forskjellige instruksjonssykluser. Mange ganger når de designer nye prosessorer, gjør arkitekter ofte endringer i måten å løse en instruksjon med hensyn til tidligere prosessorer med samme ISA, enten vi snakker om CPUer, GPUer eller andre typer prosessorer.
Det som aldri endres er instruksjonsformen, men det som gjøres er å kutte antallet kloksykluser som er nødvendige for å kryptere den. For eksempel kan vi ha en instruksjon som er beregnet på å beregne gjennomsnittet mellom to tall som tar 4 klokkesykluser i en prosessor med samme ISA, og som forbedres med 20% til en tidligere versjon av samme instruksjon som tar 5 sykluser.
Ideen er ingen ringere enn å redusere tiden det tar for en del av instruksjonene for å redusere tiden det tar å gjennomføre et program. På denne måten oppnås det med små akselerasjoner i instruksjonene at den totale ytelsen øker.
Cache og instruksjonsforsinkelse

Cache-minnet lagrer en kopi av RAM minne som instruksjonene som blir utført på det øyeblikket, tillater dette at prosessoren får tilgang til minnet uten å måtte få tilgang til RAM-en, og siden hurtigbufferen er nærmere enhetene til CPU-en at minnet ender med å kunne utføre instruksjonen på kortere tid, siden opptak av instruksjoner krever kortere tid.
Det faktum at vi snakker om forskjellige hurtigbuffernivåer, betyr ikke at alle hurtignivåer på første nivå, andre nivå og til og med tredje nivå har samme avstand og derfor ventetid, men heller at de varierer fra en arkitektur til en annen. For eksempel i gjeldende Intel Core fra Intel, ventetiden med cachene er lavere enn i konkurrentenes ekvivalenter, AMDer AMD Zen.
For å forbedre en arkitektur fra en versjon til en annen, er en av endringene som vanligvis heves, reduksjonen i ventetid med hensyn til hurtigbufferen. Spesielt når du porterer den samme arkitekturen fra en node til en annen, takket være reduksjonen av prosessorstørrelsen og avstanden mellom enhetene og cachen.
Chiplet- og latensdilemmaet

Ideen med brikker er ingen ringere enn å bruke flere sjetonger i stedet for bare en for samme funksjon, dette øker derfor kommunikasjonsavstanden mellom de forskjellige delene og dermed forsinkelsen. Dette resulterer i tap av ytelse sammenlignet med den monolitiske versjonen av prosessoren.
Når det gjelder AMD Ryzen, som er det mest kjente tilfellet, er en måte å kutte forskjellen mellom versjonene basert på chiplets og de som er monolitiske prosessorer, å kutte siste nivå cache på få sekunder. Grunnen? Hvis de hadde samme mengde hurtigbuffer, ville versjonene via chiplet bare på grunn av avstanden fra minnekontrolleren ha lavere ventetid i instruksjonene og med den høyere ytelse.
Instruksjonsforsinkelse er nøkkelen til 3DIC

Brikkene integrert i tre dimensjoner er et annet av nøkkelpunktene, spesielt de som stabler minne på en prosessor. Årsaken til dette er at de legger minnet så nær prosessoren at det alene øker ytelsen. Avveiningen av dette er termisk kvelning mellom minnet og prosessoren, noe som tvinger klokkehastigheten til å falle, og i noen design kan det skje at plassering av prosessoren og minnet separat gir høyere klokkehastigheter enn i et 3DIC-design.
Hvis minnet er nær nok til prosessoren, kan det skape en merkelig effekt, der det tar kortere tid å få tilgang til dataene i det innebygde minnet enn å gå gjennom de forskjellige cache-nivåene i arkitekturen en etter en. Noe som fullstendig endrer måten en prosessor er designet på, siden hurtigminnet er en måte å redusere ventetiden når dataene som skal behandles er for langt fra hverandre.
Avstand og forbruk er relatert
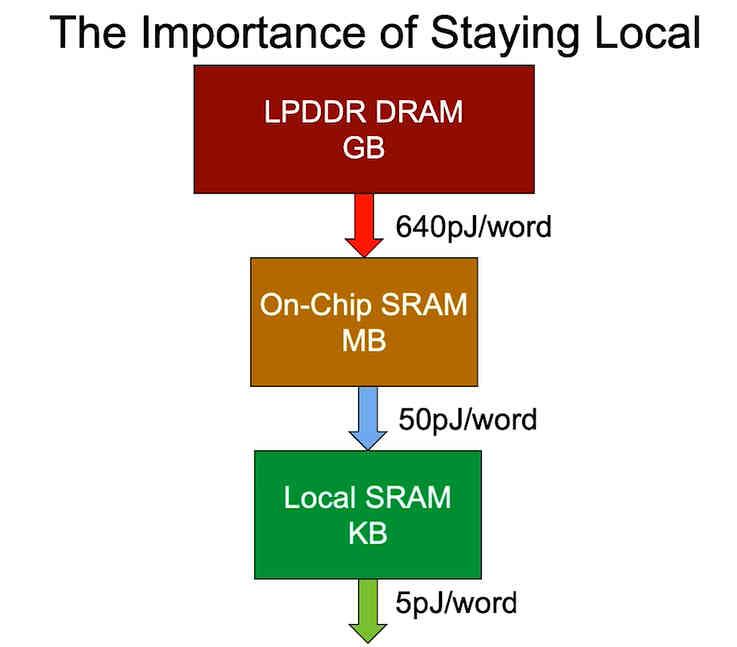
Det siste punktet er energiforbruket, som avhenger av hvor dataene ligger. Det er grunnen til at når man designer en mer optimalisert versjon når det gjelder prosessorforbruk, er det søkt å kutte avstanden dataene ligger i, siden prosessorens energiforbruk øker med avstanden i la dataene bli funnet og ikke bare ventetid, dessverre kan vi ikke passe de store datamengdene vi trenger for å kjøre et program i løpet av en chip.
I en verden der energiforbruk på grunn av klimaendringer har blitt et av de viktigste punktene og bærbarhet og lavt forbruk er et salgsargument og derfor av verdi i mange produkter, det faktum å lete etter måter å bringe minne nærmere prosessoren og dermed reduser ventetiden til instruksjonene, noe som blir ekstremt viktig for å øke ytelsen per watt.
