De huidige samenleving heeft een overvloedige uitwisseling van informatie nodig voor de ontwikkeling van de meeste activiteiten of banen. Bedrijven, vooral multinationals, verdelen bijvoorbeeld hun projecten over de vele hoofdkantoren die ze over de hele wereld hebben; Dit betekent dat er communicatie en informatie-uitwisseling tussen de verschillende locaties moet zijn voor een goede ontwikkeling van hun projecten. Een ander voorbeeld zijn universiteiten, die een systeem nodig hebben om informatie uit te wisselen met studenten, om hen aantekeningen, examens, enz. Te bezorgen.
Daarom ontstond rond 1996 de eerste P2P-applicatie uit de handen van Adam Hinkley, Hotline Connect, die bedoeld was als hulpmiddel voor universiteiten en bedrijven voor het verspreiden van bestanden. Deze applicatie gebruikte een gedecentraliseerde structuur en het duurde niet lang voordat het verouderd raakte (omdat het afhankelijk was van een enkele server); en omdat het is ontworpen voor Mac OS, het wekte niet veel interesse van gebruikers.

Met Napster, in 1999, wekte het gebruik van P2P-netwerken de nieuwsgierigheid van de gebruikers. Dit muziekuitwisselingssysteem maakte gebruik van een hybride P2P-netwerkmodel, aangezien het naast communicatie tussen peers een centrale server bevatte om deze paren te organiseren. Hun grootste probleem was dat de server breekpunten introduceerde en een grote kans op bottlenecks.
Dit is de reden waarom nieuwe topologieën zoals gedecentraliseerd in opkomst zijn, waarvan het belangrijkste kenmerk is dat er geen centrale server nodig is om het netwerk te organiseren; een voorbeeld van deze topologie is Gnutella. Een ander type zijn gestructureerde P2P-netwerken, die zich richten op het organiseren van inhoud in plaats van op het organiseren van gebruikers; als voorbeeld belichten we JXTA. We hebben ook de netwerken met Distributed Hashes Table (DHT), zoals Chord.
Vervolgens zullen we de bovengenoemde typen P2P-netwerken ontwikkelen.
Eerste P2P-systemen: een hybride benadering
De eerste P2P-systemen, zoals Napster of SETI @ home, waren de eersten die de zwaarste taken van servers naar de computers van gebruikers verplaatsten. Met behulp van internet, dat het mogelijk maakt om alle bronnen die gebruikers bieden te combineren, zijn ze erin geslaagd om deze systemen een grotere opslagcapaciteit en grotere rekenkracht te laten bereiken dan servers. Maar het probleem was dat zonder een infrastructuur die als tussenpersoon tussen de peer-entiteiten fungeerde, het systeem chaos zou worden, omdat elke peer uiteindelijk onafhankelijk zou handelen.
De oplossing voor het probleem van wanorde is de introductie van een centrale server, die de coördinatie van de paren zal regelen (coördinatie tussen paren kan sterk variëren van het ene systeem tot het andere). Dit soort systemen worden hybride systemen genoemd, omdat ze het client-server-model combineren met het model van P2P-netwerken. Veel mensen denken dat deze aanpak niet als een echt P2P-systeem moet worden omschreven, aangezien het een gecentraliseerde component (server) introduceert, maar desondanks is en blijft deze aanpak zeer succesvol.
In dit type systemen, wanneer een entiteit verbinding maakt met het netwerk (met behulp van een P2P-applicatie), wordt deze geregistreerd op de server, zodat de server te allen tijde het aantal paren heeft gecontroleerd dat op die server is geregistreerd, waardoor ze kunnen aanbieden diensten aan andere peers. Normaal gesproken is peer-to-peer-communicatie point-to-point, aangezien de peers geen groot netwerk vormen.
Het grootste probleem met dit ontwerp is dat het een systeembreekpunt introduceert en een grote kans dat er een zogenaamde 'bottleneck' optreedt (bij gegevensoverdracht, wanneer de verwerkingscapaciteit van een apparaat groter is dan de capaciteit waarop het apparaat is aangesloten ). Als het netwerk groeit, zal de serverbelasting ook toenemen en als het systeem niet in staat is om het netwerk te schalen, zal het netwerk instorten. En als de server uitvalt, kan het netwerk zichzelf niet reorganiseren.
Maar ondanks alles zijn er nog steeds veel systemen die dit model gebruiken. Deze benadering is handig voor systemen die geen inconsistenties kunnen verdragen en die geen grote hoeveelheden middelen nodig hebben voor coördinatietaken. Hier is als voorbeeld hoe Napster werkt. Napster ontstond eind 1999, door de hand van Shawn Fanning en Sean Parke, met het idee om muziekbestanden tussen gebruikers te delen.

De manier waarop Napster werkt, is dat gebruikers verbinding moeten maken met een centrale server, die verantwoordelijk is voor het bijhouden van een lijst met verbonden gebruikers en de bestanden die beschikbaar zijn voor die gebruikers. Wanneer een gebruiker een bestand wil krijgen, zoeken ze op de server en de server geeft hem een lijst met alle paren die het bestand hebben waarnaar ze op zoek zijn. Zo zoekt de geïnteresseerde naar de gebruiker die het beste kan voorzien in wat hij nodig heeft (bijvoorbeeld door diegene met de beste overdrachtssnelheid te selecteren) en krijgt hij zijn dossier rechtstreeks bij hem, zonder tussenpersonen. Napster werd al snel een zeer populair systeem onder gebruikers en bereikte in 26 2001 miljoen gebruikers, wat ongemak veroorzaakte bij platenmaatschappijen en muzikanten.
Daarom hebben de RIAA (Recording Industry Association of America) en verschillende platenmaatschappijen, in een poging er een einde aan te maken, een rechtszaak aangespannen tegen het bedrijf, waardoor de servers zijn gesloten. Dit veroorzaakte een netwerkcrash omdat gebruikers hun muziekbestanden niet konden downloaden. Als gevolg hiervan migreerde een groot deel van de gebruikers naar andere uitwisselingssystemen zoals Gnutella, Kazaa, enz.
Later, rond 2008, werd Napster een verkoopbedrijf voor mp3-muziek, met een groot aantal nummers om te downloaden: free.napster.com.
Ongestructureerde P2P-netwerken
Een andere manier om bestanden te delen, is door gebruik te maken van een niet-gecentraliseerd netwerk, dat wil zeggen een netwerk waarin elk type tussenpersoon tussen gebruikers wordt geëlimineerd, zodat het netwerk zelf verantwoordelijk is voor het organiseren van communicatie tussen peers.
In deze benadering wordt, als een gebruiker bekend is, een ‘unie’ tussen hen tot stand gebracht, zodat ze een ‘netwerk’ vormen, waaraan meer gebruikers kunnen deelnemen. Om een bestand te vinden, voert een gebruiker een zoekopdracht uit, die het hele netwerk overspoelt, om het maximale aantal gebruikers te vinden dat over die informatie beschikt.
Om bijvoorbeeld een zoekopdracht in Gnutella uit te voeren, stuurt de geïnteresseerde gebruiker een zoekopdracht naar zijn buren en deze naar die van hen. Maar om te voorkomen dat het netwerk met een kleine zoekopdracht instort, is de uitzendhorizon beperkt tot een bepaalde afstand van de oorspronkelijke host en ook tot de levensduur van het verzoek, omdat elke keer dat het bericht wordt doorgestuurd naar een andere gebruiker, de levensduur ervan afneemt.
Het grootste probleem met dit model is dat als het netwerk groeit, het vraagbericht slechts enkele gebruikers bereikt. Als wat we zoeken iets bekend is, zal elke gastheer binnen onze verspreidingshorizon het zeker hebben, maar aan de andere kant, als wat we zoeken iets heel speciaals is, zullen we het misschien niet vinden omdat door de diffusiehorizon te hebben beperkt, hebben we de hosts die misschien de informatie bevatten waarnaar we op zoek zijn, weggelaten.
Tot op de dag van vandaag zijn pure niet-gecentraliseerde P2P-netwerken vervangen door nieuwe technologieën, zoals Supernods .
SUPERNODOS, een hiërarchie in ongestructureerde netwerken
De belangrijkste problemen met ongestructureerde netwerken waren de diffusiehorizon en de omvang van het netwerk. We hebben twee mogelijke oplossingen: ofwel vergroten we de uitzendhorizon, ofwel verkleinen we de omvang van het netwerk. Als we ervoor kiezen om de uitzendhorizon te vergroten, verhogen we het aantal hosts waarnaar we het vraagbericht exponentieel moeten verzenden. Dit zou, zoals we al hebben gezien, problemen in het netwerk veroorzaken, zoals het instorten ervan. Als we er daarentegen voor kiezen om de omvang van het netwerk te verkleinen, kunnen de systemen veel beter over het netwerk schalen met behulp van de supernodes.
Het belangrijkste idee van dit systeem is dat het netwerk is verdeeld over talloze eindknooppunten en een kleine groep supernodes die goed daartussen zijn aangesloten, waarmee de eindknooppunten zijn verbonden. Om een supernode te zijn, is het nodig om voldoende bronnen aan andere gebruikers te kunnen bieden, met name bandbreedte. Dit netwerk van supernodes, waarvan er maar een paar kunnen worden, is verantwoordelijk voor het klein genoeg houden van het netwerk om de efficiëntie bij het zoeken niet te verliezen.
De werking is vergelijkbaar met die van het hybride model, aangezien de eindknooppunten zijn verbonden met de superknooppunten, die de rol van servers vervullen, zodat gebruikers alleen verbinding maken met andere gebruikers om uitsluitend downloads uit te voeren. Supernodes slaan informatie op over wat elke gebruiker heeft, zodat het de zoektijd kan verkorten en de informatie naar de eindknooppunten kan sturen die hebben wat we zoeken.
Dit type structuur wordt nog steeds veel gebruikt, vooral omdat het erg handig is voor het uitwisselen van informatie over populaire inhoud of voor het zoeken naar trefwoorden. Omdat het netwerk van supernodes wordt verkleind, zijn deze systemen zeer goed schaalbaar over het netwerk en bieden ze geen breekpunten zoals het hybride model. Aan de andere kant verminderen ze de robuustheid tegen aanvallen en netwerkuitval en verliezen ze de precisie bij het zoeken naar resultaten vanwege de replicatie via de supernodes. Als een klein aantal supernodes uitvalt, wordt het netwerk opgedeeld in kleine partities.
Gestructureerde P2P-netwerken
Deze benadering wordt parallel met de hierboven beschreven supernode-benadering ontwikkeld. Het belangrijkste kenmerk is dat in plaats van het organiseren van de knooppunten, het zich richt op de organisatie van inhoud, het groeperen van vergelijkbare inhoud op het netwerk en het creëren van een infrastructuur die onder meer efficiënt zoeken mogelijk maakt.
De peers organiseren onderling een nieuwe virtuele netwerklaag, “een overlay-netwerk”, die zich bovenop het basis-P2P-netwerk bevindt. In dit overlay-netwerk wordt de nabijheid tussen hosts gegeven als een functie van de inhoud die ze delen: ze zullen dichter bij elkaar staan naarmate ze meer bronnen gemeen hebben. Op deze manier garanderen we dat de zoekopdracht efficiënt wordt uitgevoerd binnen een niet al te verre horizon en zonder de omvang van het netwerk te verkleinen. Bijvoorbeeld JXTA, waar peers optreden in een virtueel netwerk en vrij zijn om groepen peers te vormen en te verlaten. Zo blijven zoekberichten normaal gesproken binnen het virtuele netwerk en fungeert de groep als een groeperingsmechanisme, waarbij paren met dezelfde of vergelijkbare interesses worden gecombineerd.
Deze benadering biedt hoge prestaties en nauwkeurige zoekopdrachten, als het virtuele netwerk de gelijkenis tussen de knooppunten met betrekking tot zoekopdrachten nauwkeurig weergeeft. Maar het heeft ook een aantal nadelen: het heeft hoge kosten voor het opzetten en onderhouden van het virtuele netwerk in systemen waar hosts heel snel binnenkomen en vertrekken; ze zijn niet erg geschikt voor zoekopdrachten die Booleaanse operatoren bevatten, aangezien knooppunten nodig zijn die in staat zijn om met meer dan één term te zoeken.
Een subklasse binnen dit type P2P-netwerken zijn gedistribueerde hashtabellen.
Gedistribueerde hash-tabellen (DHT)
Het belangrijkste kenmerk van DHT's is dat ze het overlay-netwerk niet organiseren op basis van de inhoud of de services ervan. Deze systemen verdelen hun volledige werkruimte door middel van identifiers, die worden toegewezen aan de peers die dit netwerk gebruiken, waardoor ze verantwoordelijk zijn voor een klein deel van de totale werkruimte. Deze identificatoren kunnen bijvoorbeeld gehele getallen zijn in het bereik [0, 2n-1], waarbij n een vast getal is.
Elk paar dat aan dit netwerk deelneemt, fungeert als een kleine database (de set van alle paren zou een gedistribueerde database vormen). Deze database organiseert uw informatie in paren (sleutel, waarde). Maar om te weten welk paar verantwoordelijk is voor het opslaan van dat paar (sleutel, waarde), moet de sleutel een geheel getal zijn binnen hetzelfde bereik waarmee de deelnemende paren van het netwerk zijn genummerd. Omdat de sleutel mogelijk niet wordt weergegeven in de gehele getallen, hebben we een functie nodig die de sleutels omzet in gehele getallen binnen hetzelfde bereik waarmee de paren zijn genummerd. Deze functie is de hash-functie. Deze functie heeft het kenmerk dat ze, wanneer ze met verschillende inputs wordt geconfronteerd, dezelfde outputwaarde kan geven, maar met een zeer lage waarschijnlijkheid. Daarom praten we niet over een "gedistribueerde database", maar over Distributed Hashes Table (DHT), want wat elk paar van het paar (sleutel, waarde) feitelijk opslaat, is niet de sleutel als zodanig, maar de hash van de sleutel.
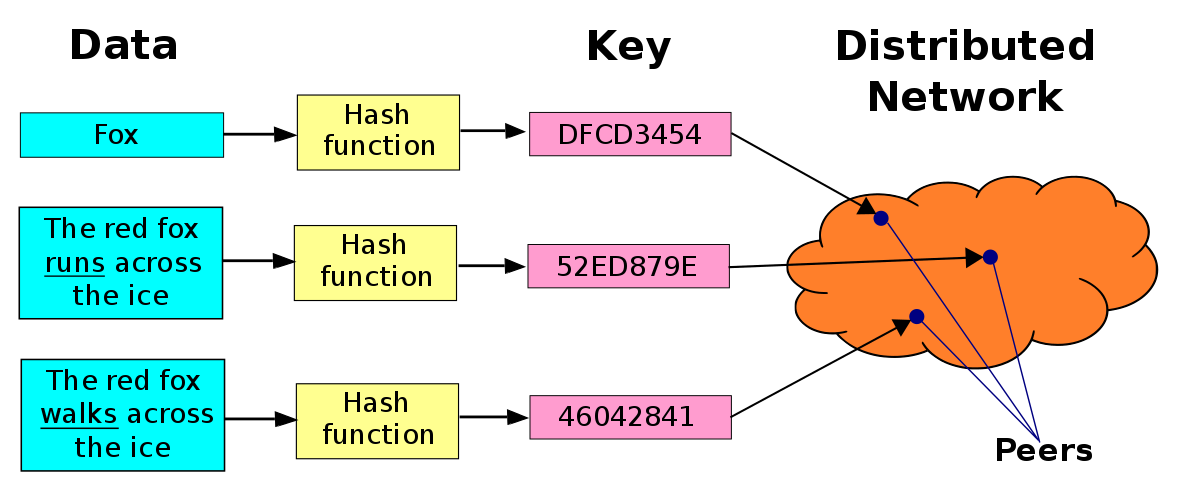
We hebben al besproken dat elk paar verantwoordelijk is voor een deel van de netwerkwerkruimte. Maar hoe wijs je het paar (sleutel, waarde) toe aan het juiste paar? Hiervoor wordt een regel gevolgd: zodra de hash van de sleutel is berekend, wordt het paar (sleutel, waarde) toegewezen aan het paar waarvan de identifier het dichtst (de onmiddellijke opvolger) van de berekende hash is. In het geval dat de berekende hash groter is dan de identifiers van de paren, wordt de modulo 2n-conventie gebruikt.
Zodra we een beetje hebben gesproken over de basiswerking van DHT, gaan we een voorbeeld zien van de implementatie ervan, via het CHORD-protocol.
Gedistribueerd zoekprotocol in P2P-netwerken: CHORD
Chord is een van de meest populaire gedistribueerde zoekprotocollen op P2P-netwerken. Dit protocol gebruikt de SHA-1-hashfunctie om, zowel aan de paren als aan de opgeslagen informatie, hun identificatie toe te wijzen. Deze identificatoren zijn gerangschikt in een cirkel (met alle waarden modulo 2m), zodat elk knooppunt weet wie zijn voorouder en zijn meest directe opvolger zijn.
Om de schaalbaarheid van het netwerk te behouden, worden, wanneer een knooppunt het netwerk verlaat, al zijn sleutels doorgegeven aan zijn onmiddellijke opvolger, op een zodanige manier dat het netwerk altijd up-to-date wordt gehouden, waardoor zoekfouten worden vermeden.
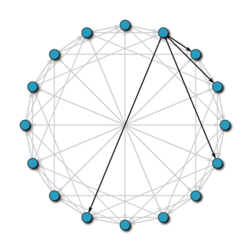
Om de verantwoordelijke persoon te vinden die een sleutel opslaat, sturen de knooppunten berichten naar elkaar totdat ze deze vinden. Maar vanwege de cirkelvormige opstelling van het netwerk kan een query in het ergste geval de helft van de knooppunten beslaan, waardoor het erg duur wordt om het te onderhouden. Om dit te vermijden en dus de kosten te verlagen, heeft elk knooppunt een routeringstabel opgeslagen, waarin het adres van knooppunten die zich op een bepaalde afstand ervan bevinden, wordt opgeslagen. Op deze manier, wanneer we willen weten wie de leiding heeft over de sleutel k, doorzoekt het knooppunt zijn routeringstabel om te zien of het het adres heeft van de persoon die verantwoordelijk is voor k; als dit het geval is, stuurt het u het verzoek rechtstreeks; als het het niet heeft, stuurt het de vraag naar het dichtstbijzijnde knooppunt van k, waarvan de identifier kleiner is dan k.
Met deze verbetering zijn we erin geslaagd om de zoekkosten te verlagen van N / 2 naar log N, waarbij N het nummer van het netwerkknooppunt is.
Conclusies.
Zoals we hebben gezien, zijn er veel soorten P2P-netwerken, elk met zijn sterke en zwakke punten. Geen daarvan steekt boven het andere uit, waardoor bij het programmeren van bijvoorbeeld een P2P-applicatie verschillende opties mogelijk zijn, elk met zijn eigen kenmerken.
Een ding om in gedachten te houden is hoe de manier om informatie te delen zich ontwikkelt. Aan het einde van het vorige millennium was het gebruik van P2P-netwerken overvloedig en voor de meeste mensen was het de enige bekende manier om informatie te delen. Vandaag is de trend veranderd. Mensen wisselen nu liever bestanden uit via grote servers, waar ze in sommige gevallen gebruikers betalen om ze te hosten.
Enkele vragen die bij u opkomen zijn: Wat is de toekomst van P2P-netwerken? Naar welke vormen van het organiseren van informatie zijn we geëvolueerd?
Een van de mogelijke evoluties is de sprong van P2P naar p4p. Wat is de P4P? Samenvattend zullen we zeggen dat P4P, ook wel hybride P2P genoemd, een kleine evolutie is van P2P waarvan het belangrijkste kenmerk is dat serviceproviders, ISP's, een essentiële rol spelen binnen het netwerk, aangezien A search eerst zal zoeken onder de deelnemende knooppunten die tot dezelfde ISP behoren.
