De RTX 3000 kwam een paar maanden geleden uit ter vervanging van de RTX 2000, maar hoe verhouden beide architecturen zich en wat zijn de veranderingen van de ene generatie naar de andere, is het een even spectaculaire sprong als NVIDIA verkoopt of zijn het eerder kleine veranderingen? We leggen de verschillen uit tussen de Turing- en Ampere-architecturen.
Is het de moeite waard om een RTX 2000 in te ruilen voor een equivalent in de RTX 3000? Vanuit ons oogpunt, als je maximale prestaties wilt, ja, maar tegelijkertijd zijn we van mening dat het belangrijk is om beide generaties GPU's te demystificeren, dus we gaan ze vergelijken.

Hoe zijn Turing en Ampere hetzelfde in architectuur?

Er zijn een aantal elementen waarbij er geen veranderingen zijn geweest van de ene generatie op de volgende, dus er zijn geen interne veranderingen en ze werken nog steeds hetzelfde in Ampere in vergelijking met Turing.
De lijst met items die niet zijn gewijzigd, wordt geopend door de opdrachtprocessors in het midden van beide GPU's. Welke is het deel dat verantwoordelijk is voor het lezen van de commandolijsten van de main RAM en het organiseren van de rest van de GPU elementen. Gevolgd door de vaste functie-eenheden voor weergave via rastering: rastereenheden, mozaïekpatroon, texturen en de ROPS.
De interne geheugenstructuur is ook niet veranderd, dat wil zeggen, de cache-hiërarchie die hetzelfde blijft in Ampere en niet is veranderd met betrekking tot Turing, aangezien het hetzelfde blijft in beide architecturen, het enige element van de geheugenhiërarchie is het GDDR6X-geheugen. interface gebruikt door GPU's op basis van de NVIDIA GA102-chip zoals de RTX 3080.
In welke elementen zijn Turing en Ampere verschillend

We moeten binnen de SM-units gaan om veranderingen te zien in de op Ampere gebaseerde RTX 3000 in vergelijking met de op Turing gebaseerde RTX 2000 en het zijn wijzigingen die op drie verschillende fronten zijn aangebracht:
- Drijvende-komma-eenheden in FP32
- De Tensor-kernen.
- De RT-kernen.
Buiten deze elementen en buiten het aantal SM-eenheden, dat hoger is in de GeForce Ampere dan in de GeForce Turing, is er geen verandering, dus NVIDIA heeft een groot deel van de hardware van de vorige generatie gerecycled om de nieuwe te maken. En voordat u de conclusie trekt dat dit iets negatiefs is, wil ik u vertellen hoe vaak hardware-ontwerpen voorkomen.
Wijzigingen in drijvende komma op GeForce Ampere SM's

Op alle GeForces tot aan Pascal werden alle drijvende-komma-eenheden door NVIDIA CUDA-kernels genoemd. Dus zonder verder oponthoud, zonder te verduidelijken wat dat betekende buiten drijvende-kommaberekeningen. Ze suggereerden dat het 32-bits precisie-eenheden met drijvende komma waren.
Eigenlijk waren de CUDA-kernels eigenlijk logicoaritmetische eenheden voor 32-bits drijvende-kommaberekeningen, maar ook eenheden van hetzelfde type voor 32-bits gehele getallen. De bijzonderheid? Ze werkten geschakeld, zodanig dat beide typen niet tegelijkertijd konden werken.

Toen Turing dingen veranderde en wat gelijktijdige uitvoering werd genoemd, verscheen, is de reden dat de GPU-thread gecombineerde threads opgesomd door gehele getallen en drijvende komma weergeeft en niet de maximale sleufbezetting van de SIMT-eenheid met elke sub -ola heeft bereikt, dus NVIDIA heeft besloten om om gelijktijdige uitvoering toe te passen. Waarin een golf van 32 uitvoeringsdraden op een gecombineerde manier kan worden uitgevoerd tussen de integer en de floating-point ALU's tegelijkertijd, zolang deze beschikbaar zijn.
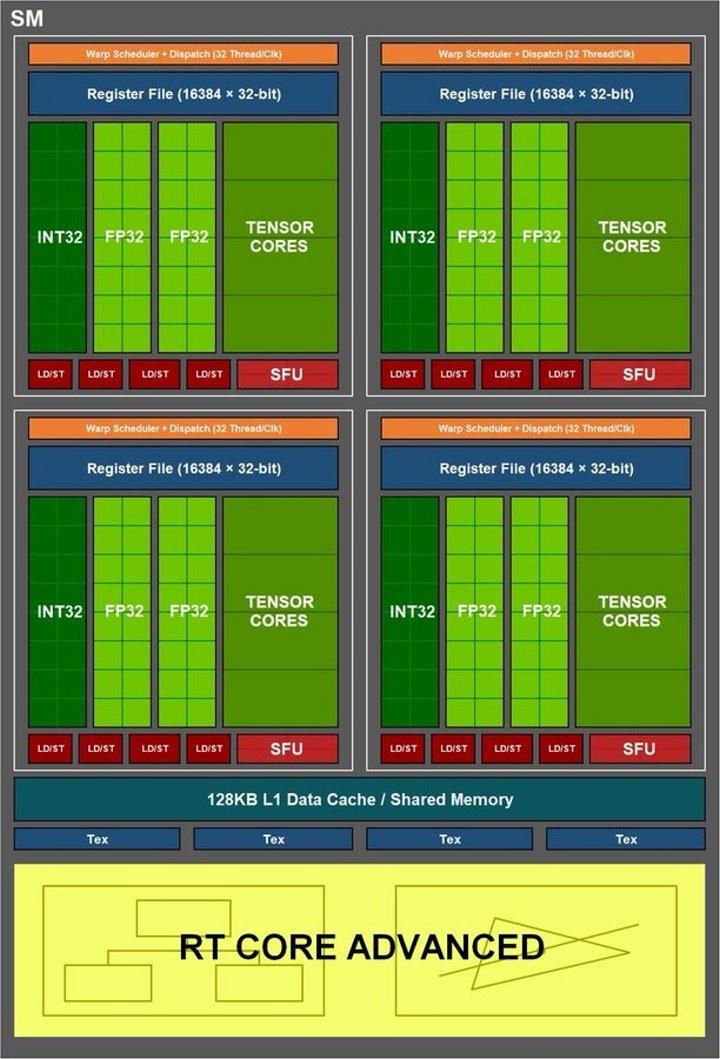
Dit betekent dat de 32-wave thread-distributie, de standaardgrootte voor NVIDIA GPU's, kan worden verdeeld over maximaal 16 integer-threads en 16 floating-point-threads. Maar iemand bij NVIDIA kwam met een voorstel voor een wijziging voor Ampere, namelijk die set van integer ALU's wordt omgeschakeld naar een tweede set van floating point ALU's, waarvoor de rest van de SM niet hoeft te worden gewijzigd.
Daarom wordt op bepaalde momenten en wanneer de voorwaarde dat een 32-draads drijvende-kommagolf binnenkomt, de rekensnelheid, gemeten in TFLOPS, verdubbeld. Hoewel alleen als ze onder deze omstandigheden worden vervuld en als we een apparaat hadden om de TFLOPS-snelheid te meten, zouden we zien dat dit niet degene is die NVIDIA zegt, die de maximale piek in zijn specificaties geeft, maar dat het oscillaties zou hebben.
Tensor-kernen op GeForce Ampere

Tensor Cores zijn systolische arrays die voor het eerst werden uitgebracht op NVIDIA Volta GPU's, en het zijn systolische arrays die het type uitvoeringseenheid zijn dat wordt gebruikt om op AI gebaseerde algoritmen te versnellen. Deze eenheden gebruiken, in tegenstelling tot de RT-kernen, de besturingseenheid van de SM en kunnen niet tegelijkertijd worden gebruikt met de eenheden met drijvende komma en gehele getallen, dus hoewel ze gelijktijdig kunnen werken, doen ze dit door de stroom van de rest te verwijderen. eenheden behalve RT Cores.
Als we de ALU-hoeveelheid die de RT-kernen vormen tussen de ene generatie en de andere toevoegen, zullen we zien dat er dezelfde hoeveelheid is, maar met een andere configuratie. In Turing hebben we 8 units, 2 per sub-core, van 64 ALU's elk in een Tensor 4 x 4 x 4 configuratie. In Ampere hebben de Tensor Cores een configuratie van 4 eenheden, 1 per sub-core, met 128 ALU's. voor elk van hen.
RT-kernen op GeForce Ampere
De RT Cores zijn het minst bekende onderdeel van allemaal, aangezien NVIDIA geen informatie heeft gegeven over wat hun interne werking is. We weten wat het doet, hoe het werkt, maar we weten niet wat de elementen erin zitten en welke veranderingen er van de ene generatie op de andere hebben plaatsgevonden.
Het eerste dat opvalt, is de vermelding door NVIDIA dat RT Cores nu twee keer zoveel kruispunten per driehoek kan maken, wat niet twee keer zoveel kruispunten per seconde betekent. De reden hiervoor is dat bij het doorkruisen van de BVH-boom, het de kruising maakt van de dozen die de verschillende knooppunten van de boom zijn en alleen de laatste kruising van de boom is die gemaakt met de driehoek, de die is het meest complex om uit te voeren. De eenheden voor het berekenen van het snijpunt van de dozen zijn veel eenvoudiger, in Turing hebben we in theorie vier eenheden die parallel werken om door de verschillende niveaus van een boom te gaan en een enkele eenheid die de kruising van de straal met de driehoek uitvoert.
De tweede verandering op hardwareniveau is de mogelijkheid om de driehoek te interpoleren op basis van zijn positie in de tijd, wat de sleutel is tot de implementatie van Ray Tracing met Motion Blur, een techniek die nog steeds ongekend is in games die compatibel zijn met Ray Tracing. In het geval dat er andere wijzigingen zijn, heeft NVIDIA dit niet publiekelijk gemeld en daarom kunnen we geen verdere conclusies trekken.
