발표 후 가장 주목을받은 세부 사항 중 하나 NVIDIA RTX 3000은 FP32에서 성능을 발휘했습니다. 지금까지 NVIDIA의 소위 TFLOPS 셰이더 어느 정도 확장 가능했지만 Ampere를 사용하면 그 숫자가 두 배로 늘어 났고 FP32 성능이 아키텍처 비교의 정확성과 동의어라는 생각을 계속하는 많은 사용자의 경고를 불러 일으켰습니다. 왜 이런 일이 발생합니까?
이 설명은 아키텍처의 근본적인 변화 중 하나와 NVIDIA가 1/2 FP32 속도라고 부르는 것과 관련이 있습니다. 이 이름은 지금부터 나온 것이 아니라 Turing 아키텍처와 SM에서 유래했습니다. 우리가 잘 알고 있듯이 정수가 부동 소수점과 분리되어 세 가지 다른 엔진을 포함 할 수 있지만 몇 가지 단점이 있습니다.

FP32 셰이더 TFLOPS 속도는 CUDA 수와 직접 관련이 있습니다.
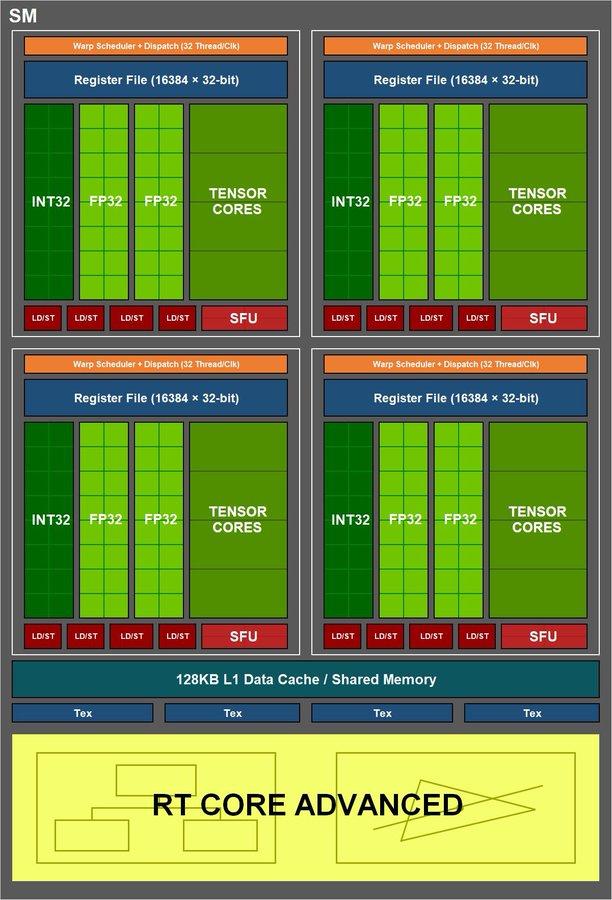
"마 법적"(아이러니에 주목) NVIDIA는 일방적으로 Ampere 그래픽 카드의 셰이더 수를 두 배로 늘리기로 결정했습니다. Shaders TFLOPS의 성능 데이터와 연결되는 작은 기반이있는 마케팅 활동입니다.
모든 것을 이해하려면 NVIDIA가 이야기하는 1/2 FP32의 선구자 였고 Turing을 동일한 작업으로 끌어 들이기 때문에 아키텍처로서의 Volta 기반에서 시작해야합니다. 두 아키텍처 모두에서 각 SM은 클럭 당 1 개의 명령어 패키지 32 개를 실행할 수 있었으며 FP16는 32 개, INT16는 32 개 , 또는 동일한 것, 부동 소수점에 대한 16 개의 명령어와 숫자에 대한 16 개의 명령어. 각 클록 사이클에 대한 정수.
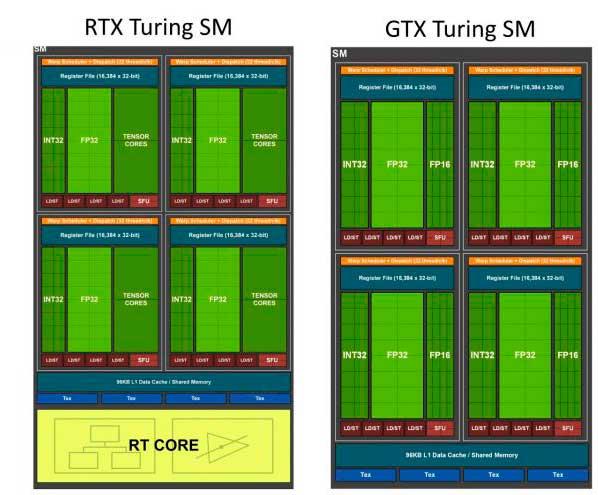
왜 이렇게합니까? 음, 처음에 NVIDIA는 일반적인 아키텍처로 임대했기 때문에 FP32 작업이 더 적다는 사실을 대가로 각 프레임의 렌더링을 위에서 언급 한 XNUMX 개의 엔진으로 나누어 Ray Tracing 또는 DLSS와 함께 작동 할 수 있습니다.
즉, 32 년 만에 아키텍처의 가장 큰 도약에 대한 대가로 INT32 용 FP10 용량을 희생했습니다.이 변경 사항은 각 SM에 대해 약간의 성능 이점이 있으며 부분적으로는 BVH 및 AI 알고리즘을 사용하여 작업 할 수있는 기능을 제공했습니다. 계략.
Ampere는 물건을 제자리로 되돌립니다.
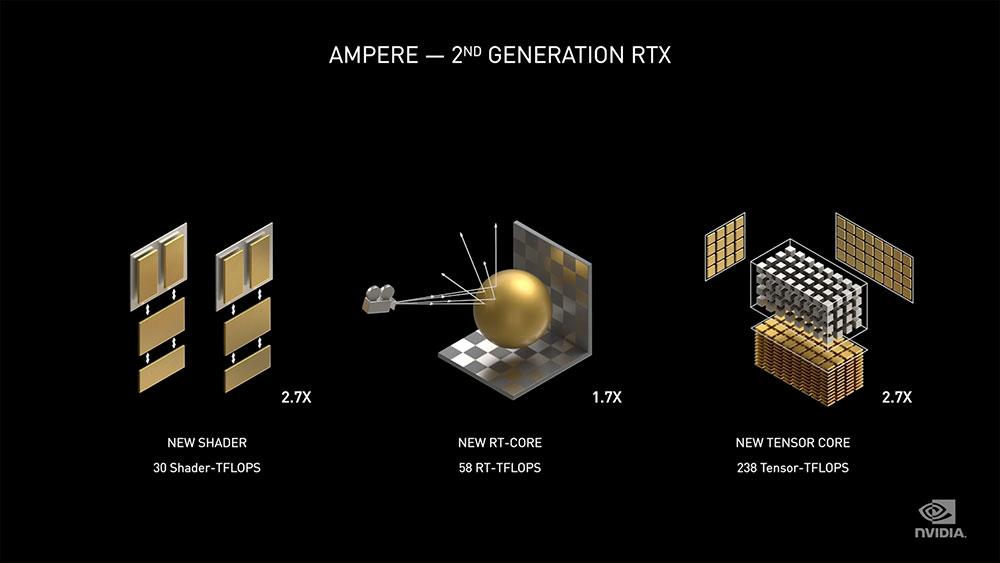
RTX 3000 및 Ampere 아키텍처를 통해 NVIDIA는 1/2 FP32를 중단하고 SM 내의 각 클록에 대해 32 개의 FP32 작업을 다시 실행합니다 (최소한 이론적으로는 4 개 엔진 대신 XNUMX 개 엔진에 대해 말할 수 있음). 회사의 돋보기와 광학은 사양의 전체 셰이더 수를 "마법처럼"두 배로 늘리는 것이지만 실제로는 NVIDIA가 엔진의 일부만 두 배로 늘 렸기 때문에 실제로 그렇게 작동하지 않습니다. 나머지는 그대로두기 때문에 성능은 셰이더 수를 두 배로 늘리는 것과 같지 않습니다.
- RTX 3090 -> 10496/2 = 5248
- RTX 3080 -> 8704/2 = 4352
- RTX 3070 -> 5888/2 = 2944
오늘날 세 개의 NVIDIA 참조 카드의 실제 셰이더 수는 절반에 불과하며 이는 FP32에서 이론적 성능의 논리적 계산에 영향을줍니다. 사양의 성능을 실제 성능과 비교할 때이 값이 나타내는 희소성을 이미 보았으므로 이론에 중점을 둡니다.
그러니 NVIDIA가 성능을 마술처럼 두 배로 늘릴 수 있었던 방법을 설명하겠습니다.
FP32에서 성능을 두 배로 늘리는 것부터 "작은"마진 만 표시 할 수있는 것까지

공식 NVIDIA 사양을 살펴보면 RTX 3090은 다음과 같은 FP32 성능을 얻습니다. 35.58 TFLOPS , 또는 이름 : Shader TFLOPS. 이 수치는 계산하기가 매우 쉽고 TFLOPS를 하드웨어 구성 요소 간의 표준 측정 값으로 비교하는 끔찍한 오류를 보여줍니다.
셰이더 x 주파수 x주기 당 작업 2 회 x 1 GPU
RTX 3090의 경우 10,496 x 1,700 x 2 x 1-> 35,686,400 FLOPS 또는 35,686 TFLOPS (아키텍처에서 100 % 효율성을 가정하면 어떤 칩에서도 불가능한 것입니다). 논리적으로이 값은 위에서 언급 한 내용에 대해 완전히 비현실적이며 RTX 2080 Ti에 비해 성능이 거의 XNUMX 배인 우월성을 반영하지 않습니다.
TFLOPS의 올바른 숫자는 다음과 같습니다. 17,843 TFLOPS , 또는 RTX 32.66 Ti보다 2080 % 더 높은 부동 소수점 성능. 그러나이 차이는 FP32에만 해당되며 예를 들어 INT32의 성능은 제외됩니다.
지금까지 본 것은 성능의 차이가 24%에서 29% 사이라고 안내하고 있다. 대략적으로 그리고 선택한 해상도에 따라 다르지만 회사가 설정하려고 시도한 마케팅과는 매우 거리가 멀고 안타깝게도 스스로 당당하게 될 것입니다. TFLOPS 셰이더로.
