現在のアーキテクチャとパフォーマンスを理解するための重要な概念のXNUMXつ インテル & AMD CPUは、マイクロオペレーションの概念であり、キャッシュなどのユニットでもあります。 この記事では、アクセス可能な方法で、それらが何であるか、そして今日のプロセッサーが可能な限り最大のパフォーマンスを達成するためにすべての操作をそれらに基づいている理由を説明します。
A CPU 今日では、多数の異なる命令を実行でき、初期のパーソナルコンピュータの最大5,000倍の周波数で実行されます。 私たちは、MHzまたはGHzの量が多いのは、新しいものが製造されたためであると完全に誤解する傾向があります。 現実は非常に異なり、これが今日のマイクロプロセッサの巨大な計算能力を達成するための鍵となるマイクロオペレーションの出番です。

マイクロオペレーションとは何ですか?
プログラムが何であるかを説明するために通常使用される現実の直喩のXNUMXつは、料理レシピの直喩です。 動詞で実行しなければならない一連のアクションが割り当てられているのを見ることができます。 たとえば、私はあなたが鍋で肉片を揚げるレシピを入れることができます、しかしあなたのためにそれは鍋を探し、油で同じことをし、後者を鍋に入れ、待つ必要があることがわかります熱くして肉を入れます。 ご覧のとおり、原則として単一の動詞によって定義されるものを一連のアクションに変換しました。
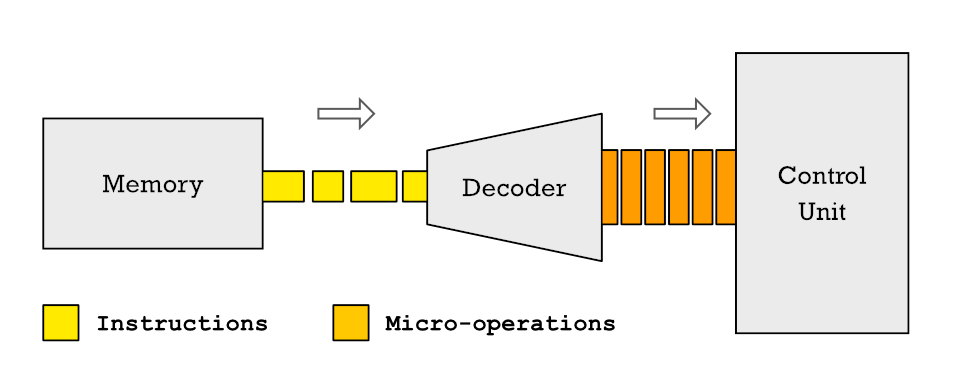
さて、CPUの命令は、マイクロオペレーションと呼ばれる小さな命令に分解できます。 そして、なぜマイクロインストラクションではないのですか? まあ、命令が実行のためにいくつかのサイクルにセグメント化するだけで、解決するのに数クロックサイクルかかるという事実のために。 一方、マイクロオペレーションは単一のクロックサイクルを必要とします。
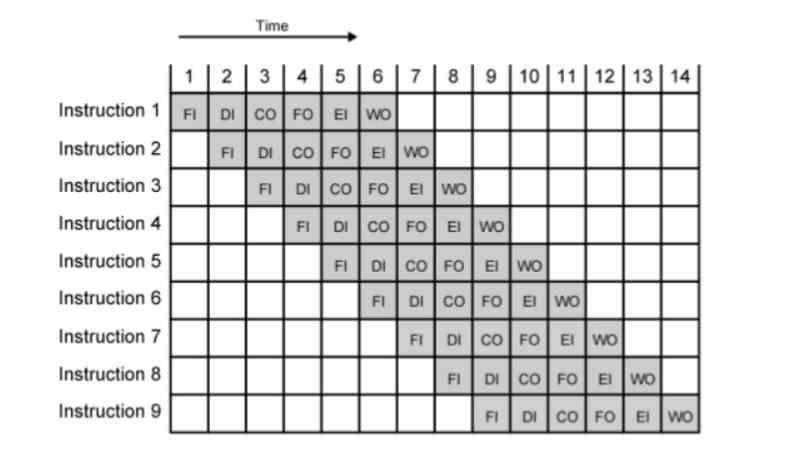
MHzまたはGHzを最大にするXNUMXつの方法は、パイプライン化です。パイプラインでは、各命令がXNUMXクロックサイクル続く複数のステージで実行されます。 周波数は時間の逆数であるため、より多くの周波数を取得するには、時間を短縮する必要があります。 問題は、命令を分解できなくなり、パイプラインのステージ数が短くなり、達成できるクロック速度が遅くなることです。
実際、これらは、IntelP6アーキテクチャとその派生CPU(Pentium IIやIIIなど)のアウトオブオーダー実行の出現とともに生まれました。 この理由は、P5またはPentiumのセグメンテーションでは、200MHzを少し超える範囲にしか到達できなかったためです。 マイクロオペレーションでは、各命令のステージ数をさらに長くすることで、Pentium 3でGHzバリアを超え、Pentium16で4倍のクロック速度を実現しました。ブランド、レジスタ、および命令セットに関係なく、アウトオブオーダー実行。
CPUはx86でもRISC-VでもARMでもありません
現在のCPUでは、命令がデコードされて制御ユニットに割り当てられるCPU制御ユニットに到着すると、最初にいくつかの異なるマイクロオペレーションに分割されます。 これは、プロセッサが実行する各命令が一連の基本的なマイクロ操作で構成されており、順序付けられたフロー内のそれらのセットがマイクロコードと呼ばれることを意味します。

命令のマイクロオペレーションへの分解とに保存されているプログラムの変換 RAM マイクロコードへの変換は、今日すべてのプロセッサで見られます。 だからあなたの携帯電話のISAが ARM CPUまたはPCのx86CPUはプログラムを実行しており、その実行ユニットはそれらのレジスタと命令のセットを使用して命令を解決していません。
このプロセスには、前のセクションで説明した利点があるだけでなく、同じアーキテクチャ内で、同じレジスタと命令のセットの下でも、異なる方法で分解され、プログラムが完全に互換性のある命令を見つけることができます。 多くの場合、必要なクロックサイクル数を減らすことが目的ですが、ほとんどの場合、プロセッサ内の同じリソースに対して複数の要求がある場合に発生する競合を回避することです。
マイクロオペレーションキャッシュとは何ですか?
可能な限り最大のパフォーマンスを達成するためのもう4つの重要な要素は、マイクロオペレーションのキャッシュです。これは、マイクロオペレーションよりも遅いため、時間的に近くなります。 その起源は、IntelがPentium XNUMXに実装したトレースキャッシュにあります。これは、さまざまな命令と、コントロールユニットによって以前に分解されたマイクロオペレーションとの間の相関関係を格納する命令の第XNUMXレベルキャッシュの拡張です。 。

ただし、x86 ISAは常にRISCタイプに関して問題を抱えていましたが、後者はコード内の命令長が固定されており、x86の場合、それぞれが1〜15バイトを測定できます。 各命令は、いくつかのマイクロオペレーションでフェッチおよびデコードされることに注意する必要があります。 これを行うには、今日でも、必要な最適化なしでエネルギー電力の最大XNUMX分のXNUMXを消費できる非常に複雑な制御ユニットが必要です。
したがって、マイクロオペレーションキャッシュはトレースキャッシュの進化形ですが、命令キャッシュの一部ではなく、ハードウェアに依存しないエンティティです。 マイクロオペレーションキャッシュでは、それぞれのサイズがバイト数で固定されているため、たとえばISA x86を搭載したCPUは、RISCタイプに可能な限り近く動作し、コントロールユニットとその複雑さを軽減できます。消費。 Pentium 4プロットキャッシュとの違いは、現在のマイクロオペレーションキャッシュが、命令に属するすべてのマイクロオペレーションをXNUMX行に格納することです。
システムを教えてください。
マイクロオペレーションキャッシュが行うことは、命令をデコードする作業を回避することです。したがって、デコーダーが上記のタスクを実行した直後に、デコーダーが行うことは、その作業の結果を上記のキャッシュに格納することです。 このように、次の命令をデコードする必要がある場合、それを形成するマイクロオペレーションが上記のキャッシュにあるかどうかを検索することが行われます。 これを行う動機は、複雑な命令を分解しないよりも、キャッシュを参照するのにかかる時間が短いという事実に他なりません。
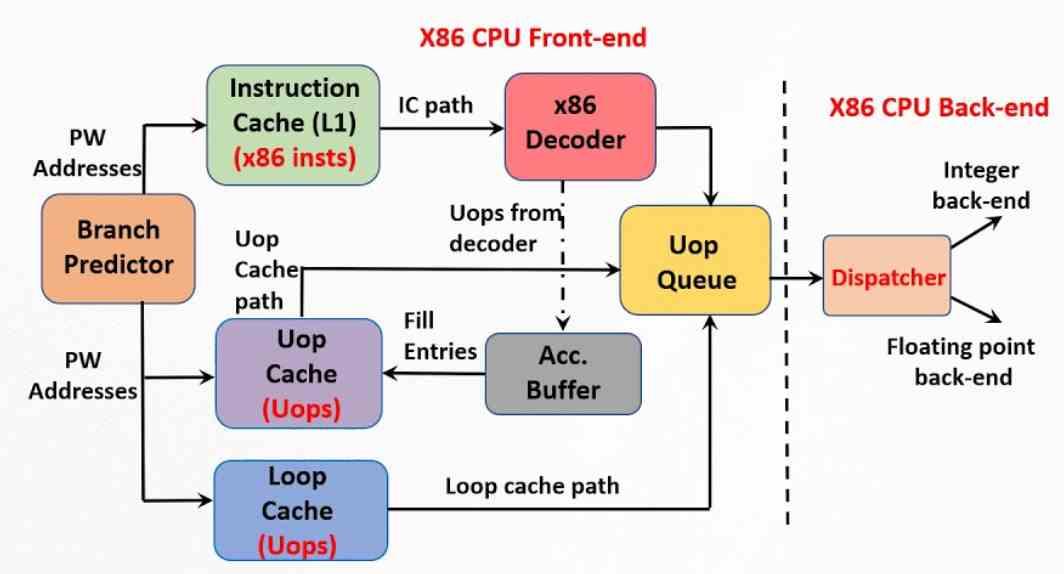
ただし、これはキャッシュのように機能し、新しい命令が到着すると、その内容は時間の経過とともにシフトします。 第XNUMXレベルの命令キャッシュに新しい命令がある場合、マイクロオペレーションキャッシュはすでにデコードされている場合に検索されます。 そうでない場合は、通常どおり続行します。
分解された最も一般的な命令は、通常、マイクロオペレーションキャッシュの一部です。 ただし、廃棄される可能性が少ないのは、新しい指示の余地を残すために、散発的に使用される人がより頻繁に使用されることです。 理想的には、マイクロオペレーションキャッシュのサイズは、それらすべてを格納するのに十分な大きさである必要がありますが、その中の検索がCPUのパフォーマンスに影響を与えないように十分に小さい必要があります。