
アウト・オブ・オーダーで実行された最初のプロセッサーはIBM POWER 1でした。これは、同じ名前のRISCプロセッサーとPowerPCの基礎となります。 インテル PentiumProのx86にこのテクノロジーを採用しました。 それ以来、すべてのPC CPUは、可能な限り最大のパフォーマンスを得るための基盤のXNUMXつとしてアウトオブオーダーテクノロジーを利用しています。
プロセッサの設計における主な関心事は、多くの場合、最大の電力を得ることではなく、命令を実行するときに最高のパフォーマンスを得ることにあります。 パフォーマンスは、プロセッサの動作の理論上の理想に近づくという事実として理解されています。 最も強力なものを持つことは無意味です CPU 制限のために、それが持っている唯一のものが存在する可能性とそうでない可能性である場合。
並列処理を処理するXNUMXつの方法
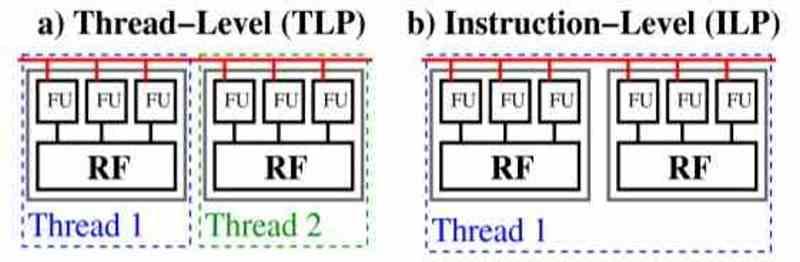
プログラムのコードで並列処理を処理する方法はXNUMXつあります。これらは、スレッドレベルの並列処理(ILP)と命令並列処理(TLP)です。
TLPでは、コードはいくつかのサブプログラムに分割されます。これらのサブプログラムは他のサブプログラムから独立しており、非同期で動作します。つまり、各サブプログラムは残りのコードに依存しません。 TLPプロセッサを使用している場合、重要なのは、何らかの理由で実行停止が発生した場合、TLPプロセッサは別の実行スレッドを取得し、アイドル状態のスレッドを保留にすることです。
ILPプロセッサは異なり、並列処理は命令レベルであるため、同じ実行スレッド内にあるため、メインスレッドを保留にしてチートすることはできません。 現在、CPUはXNUMX種類の実行を組み合わせていますが、ILPは依然としてCPU専用であり、完全に並列化可能なコードよりもシリアルコードの点で大きな利点があります。
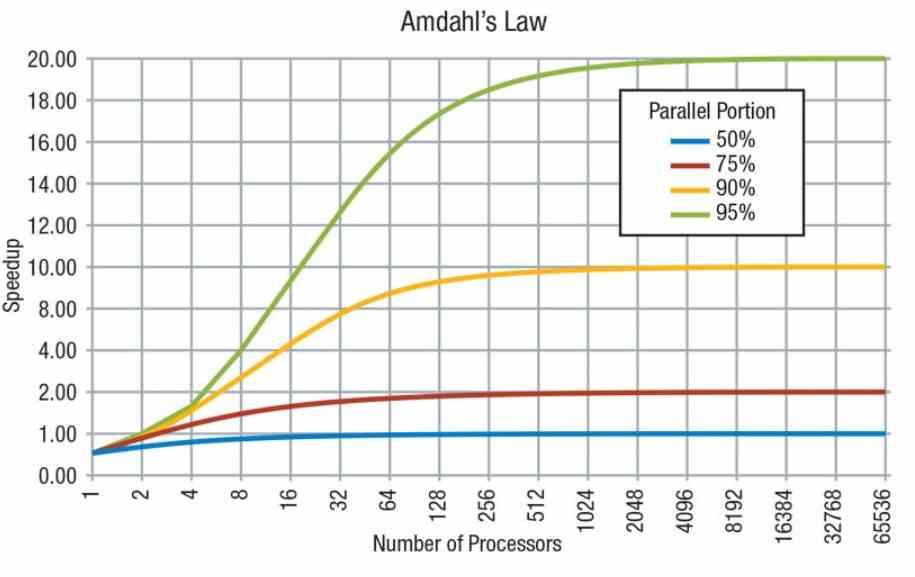
アムダールの法則によれば、コードは、XNUMXつのプロセッサでのみ実行できる直列の部分と、複数のプロセッサで実行できる並列の部分で構成されていることを忘れることはできません。 ただし、すべてを並列化できるわけではなく、コードのシリアル部分にはシリアル操作が必要です。
過去15年間で、並列アルゴリズムがコアがTLPタイプのGPUで実行され、シリアルコードがILPタイプのCPUで実行されるという概念が開発されました。
命令の順序どおりの実行
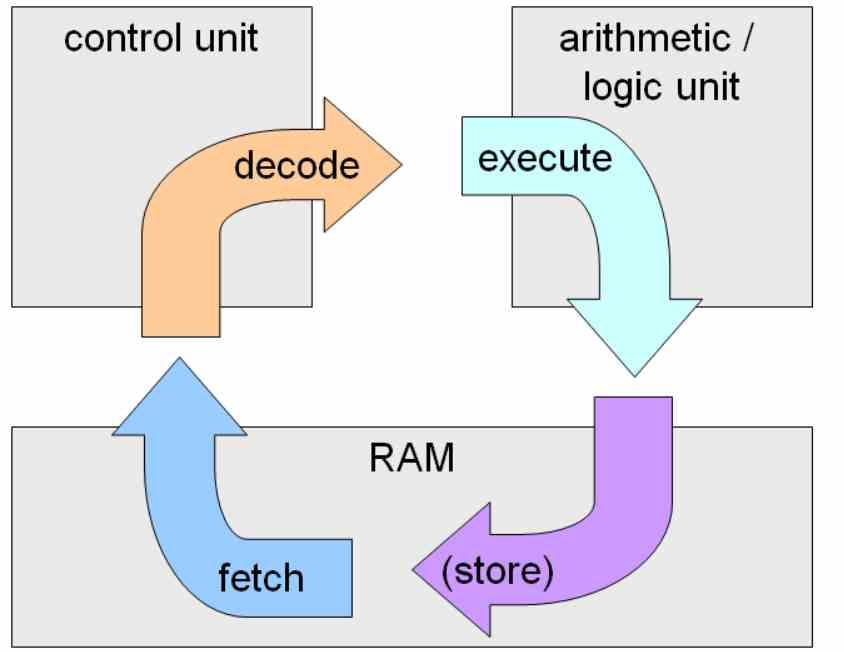
インオーダー実行は古典的な命令実行であり、その名前は、命令がコードに表示される順序で実行され、前の命令が解決されない限り次の命令を続行できないという事実に由来しています。
インオーダー実行の最大の難しさは、条件付き命令とジャンプ命令にあります。これは、条件が発生したときに実行され、コード実行の速度が大幅に低下するためです。 これは、プロセッサのステージ数が非常に多い場合に大きな問題になります。これは、CPUが高いクロック速度で実行されている場合に発生します。
高いクロック速度を達成するための落とし穴は、命令サイクルの多数のサブステージで命令の分解能を最大にセグメント化することです。 ジャンプまたは誤った状態が発生すると、かなりの数の命令サイクルが失われます。
故障、ILPの加速

アウトオブオーダーまたはアウトオブオーダー実行は、最先端のCPUがコードを実行する方法であり、実行の停止を回避すると考えられています。 その名前が示すように、コードに示されている順序とは異なる順序でプロセッサの命令を実行することで構成されます。
これが行われる理由は、各タイプの命令に実行ユニットのタイプが割り当てられているためです。 命令の種類に応じて、CPUは実行ユニットの種類を使用しますが、これらは制限されています。 これにより実行が停止する可能性があるため、実行中の次の命令を進めて、命令の実際の順序であるメモリまたは内部レジスタをポイントします。実行されると、命令は送り返されます。コード内の元の順序。
アウトオブオーダーを使用すると、サイクルごとに解決される命令の平均数を増やし、理想的なパフォーマンスに近づけることができます。 たとえば、最初のIntel Pentiumは順序どおりに実行され、486つしか機能しない40に対してXNUMXつの命令を処理できるCPUでしたが、それにもかかわらず、停止によるパフォーマンスはXNUMX%しか追加されませんでした。
故障の追加ステージ
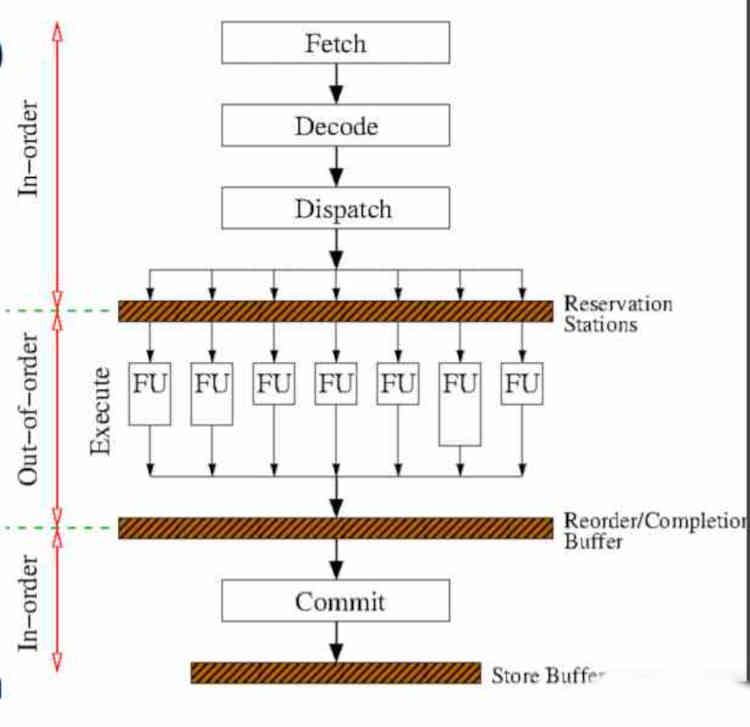
アウトオブオーダー実行の実装は、命令サイクルに追加のステージを追加します。これについては、タイトルの記事ですでに説明しました。 これはあなたのCPUがソフトウェアによって与えられた命令を実行する方法です、 HardZoneで見つけることができます。
実際、命令の実行の中心部分のみが順番に実行に関して変化します。これらの変更は実行ステージの前に発生するため、フェッチおよびデコードされる最初のXNUMXつは影響を受けませんが、XNUMXつの新しいステージは影響を受けます。追加されました。これは、命令の実行の前後に発生します。
最初の段階はスタンバイステーションであり、ハードウェアは実行ユニットが解放されるのを待ちます。 実行ユニットが空いていることを監視するだけでなく、実行されている各命令のクロックサイクルの平均期間をカウントして、命令の並べ替え方法を知るメカニズムに基づいているため、実装は複雑です。
第XNUMX段階は、出力順に命令をソートすることを担当する並べ替えバッファーです。 アウトオブオーダー実行での命令の出力を高速化するために、コード内のすべての投機的命令ブランチが実行されることに注意してください。 投機的命令は、条件が満たされているかどうかに関係なく、条件付きジャンプがある場合に与えられる命令です。 したがって、未確認の実行ブランチが破棄されるのはこの段階です。