
AMD Zen4アーキテクチャはAMDZenアーキテクチャの第3世代であり、前世代と比較して一連の重要な変更と一連の特定の新規性をもたらします。 Zen XNUMXよりもパフォーマンスを向上させ、 インテル それはすべての肉をグリルに置くことです。 AMD Zen 4アーキテクチャの新機能は何ですか? 説明します。
AMDが第1000世代のZenアーキテクチャに基づく最初のRyzenXNUMXプロセッサをリリースしてから数年が経過しました。 これはリサ・スーが率いる会社にとって運の変化であり、AMDはもはやIntelから常に牽引されている安価なCPUのブランドとは見なされなくなります。 今日、AMDアーキテクチャはIntelと打撃を交換できるだけでなく、いくつかの点でそれらを上回っています。
![]()
Zen 3の場合、AMDのカメがIntelのうさぎを追い抜いたと想定されています。 これは、AMDがあなたからあなたへと競争する同じセグメントの異なるセグメントでx86プロセッサの市場シェアを削減するという危険性を認識しています。 しかし、その最終的な利点にもかかわらず、AMDは絶え間ない変化と進化の市場で眠ることを許すことはできません。 そのため、AMDはZen4と比較して重要な変更を加えたZen3を設計し、それにはいくつかの範囲のプロセッサが含まれています。
Zen4でのコアの構成

Zenアーキテクチャには、AMDがCCXと呼ぶコアが含まれています。CCXは、次の特性を持つ一連のコアで構成されています。
- 各コアにはプライベートの第XNUMXレベルと第XNUMXレベルのキャッシュがあります。つまり、残りのコアはそれにアクセスできません。
- L3キャッシュは共有されており、すべてのキャッシュにアクセスできます。 さらに、さまざまなコアがInfinityFabricインターフェイスのネットワークを介して内部で通信します。
- ZenとZen2では、各CCXは4つのコアとそれらの共有L3で構成されていました。 Zen 3では、4コアから8コアになりました。 Zen4はZen3と同じタイプの構成になるため、 CCXあたり8コア .
もう4つの違いは、Zen 5アーキテクチャがTSMCの7nmノードの下で構築されるように設計されていることです。これは、4nmノードとは異なる設計ルールを持っています。 したがって、Zen XNUMXコアを使用するチップはすべて、その製造ノードに基づいています。 CCDチップレットまたはモノリシックAPUのいずれか。
Zen4アーキテクチャはAVX-512命令を統合します
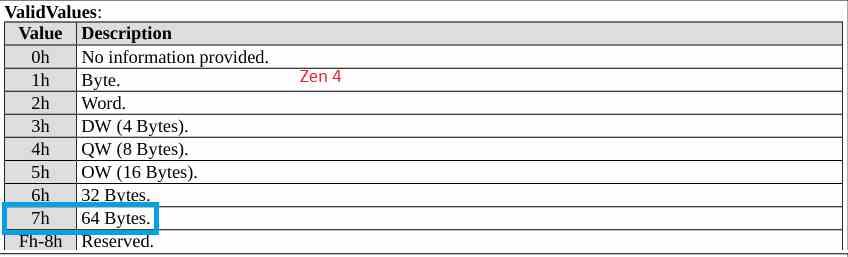
最初の主要な目新しさは AVX-512命令のサポート 、これまではIntelCPU専用でした。 これらの命令は、その名前が示すように、512ビット長のSIMD命令であり、これまでに使用された中で最も長いものです。 CPU x86アーキテクチャを使用します。 さらに、AVX-512命令には、アプリケーションごとに異なる拡張機能が含まれています。 Zen 512コアでサポートされているAVX4拡張機能? それらは次のとおりです
- AVX512VL
- AVX512BW
- AVX512CD
- AVX512_IFMA
- AVX512DQ
- AVX512F
- AVX512_VPOPCNTDQ
- AVX512_BITALG
- AVX512_VNNI
- AVX512_VBMI2
- AVX512_VBMI
- AVX512_BF16
さらに、Zen 512でのAVX-4命令の実装は、第XNUMXレベルのデータキャッシュラインとそれに続くキャッシュレベルが増加したことを前提としています。 32〜64バイトまたは512ビットのキャッシュラインのサイズ 。 これは、単一サイクルのAVX-512命令のすべてのデータを収集するために不可欠です。 この小さな改善は、AVX-512命令のサポートを意味するだけでなく、CPUのロード/ストアユニットの帯域幅が増加し、それに伴ってプロセッサの内部帯域幅も増加しました。 さらに、Zen 4が64バイトのデータを直接ロードできるという事実は、 新しいAVX-512ユニット これらの命令を単一のサイクルで実行できます。
ただし、AVX-512命令には制限があり、消費量が多くなります。 これにより、これらのタイプの命令を使用すると、Zen 4CPUが通常のクロック速度を下回る可能性があります。
Zen4アーキテクチャでのキャッシュシステムの変更
| キャッシュ | AMD Zen 4 | AMD Zen 3 |
|---|---|---|
| L1データ | 32 KB8ウェイ | 32 KB8ウェイ |
| L1の説明 | 32 KB8ウェイ | 32 KB8ウェイ |
| L2 | 1 MB8ウェイ | 512 KB8ウェイ |
| L3 | 32MB16ウェイ | 32MB16ウェイ |
| L1 ITLB(MMU) | 64の完全に連想的な入力 | 64の完全に連想的な入力 |
| L1 DTLB(MMU) | 512入力4.Way | 512入力4.Way |
| L2 ITLB(MMU) | 72の完全に連想的な入力 | 64の完全に連想的な入力 |
| L2 DTLB(MMU) | 3072ウェイチケット | 2048ウェイチケット |
最初のAMDZen以来、AMDCPUのキャッシュシステムはほぼ同じままです。 CCDのすべてのコアで共有される最後のレベルのキャッシュを除いて、Zen 4の場合、コア自体のキャッシュ構造が変更されます。これを次の表に示します。
ハイライトする最初の変更は 各コアのL2キャッシュ内 、これにより容量が増加します 512 KB〜1MBのメモリ 、これにより、上記のキャッシュでデータが見つかる可能性が高くなりますが、代わりにL1およびL3キャッシュのサイズは変更されません。 もちろん、前にコメントしたように、キャッシュラインあたりのサイズは32バイトから64バイトになりました。
もあります TLBまたはトランスレーションルックアヘッドバッファへの変更 。 これらは、仮想アドレスを物理アドレスに変換するために、各プロセッサコアのMMUによって使用されます。 このセクションを開始する表からわかるように、 第64レベルのデータキャッシュが72エントリからXNUMXエントリに増加しました 。 一方、L2キャッシュは 2048エントリから3072エントリ NS。 これは、この点で、容量だけでなく、 同時アクセス数 .
Compute ExpressLinkを介したRAMメモリのサポート
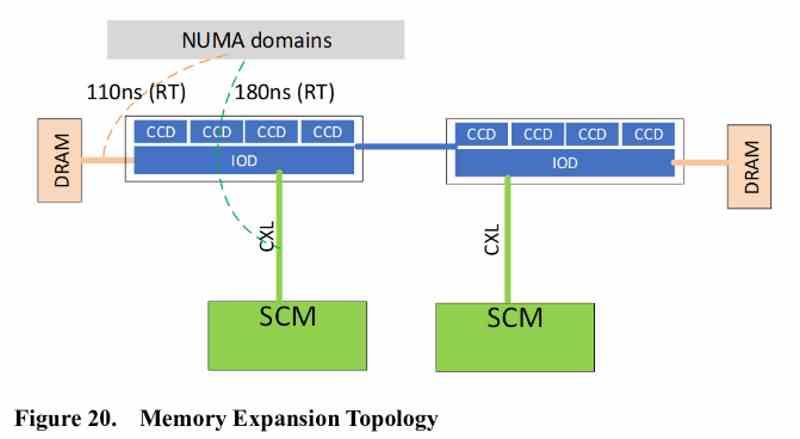
ここで、ラップトップおよびデスクトップ用のプロセッサの範囲を、コードネームGenoaで将来のAMD EPYCと区別する必要があります。つまり、PCI Express 5.0標準は、ソケットAM5のCPUでは使用できません。 そうなる。 Zen4ベースのAMDHEDTおよびサーバーCPU それで CXLのサポート .
CXL規格の鍵は、PCI Express 5.0インターフェイスにメモリの一貫性を与えることです。つまり、メモリモジュールは不揮発性メモリであるかどうかに関係なく、 RAM、またはこれらの組み合わせができます 従来のメモリインターフェイスを介して接続するだけではありません 、PCIExpressポート経由でも。

市場には、ストレージクラスメモリまたはSCMとも呼ばれるCXLを備えたPCIExpressを介したRAMメモリ拡張モジュールがすでに存在します。 AMDはAMDEPYCジェノアに統合する予定です PCIe5.0インターフェイスを介してシステムRAMを拡張する機能 。 もちろん、DDR5、LPDDR5、またはAMDが互換性のあるCPUとAPUをZen 4アーキテクチャと互換性のある他のタイプのメモリと比較して、上記のメモリにアクセスする際の待ち時間が長くなります。
物理レベルでXNUMXつの異なるメモリウェルを使用することは、 XNUMXつのメモリスペースからデータをコピーするDMAメカニズム は、アドレス指定レベルで統合されていますが、物理レベルでは統合されていません。つまり、あるRAMスペースから別のRAMスペースにデータをコピーするためのメカニズムが必要です。
より広い内部および外部帯域幅
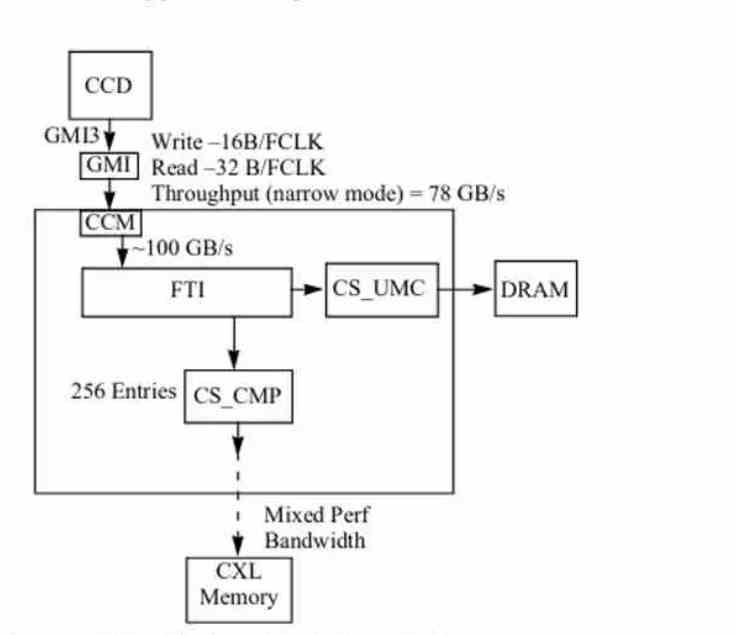
このすべてで述べられていない詳細があります、そしてそれはAMDがそのInfinityFabricインターフェースを使用して内部と外部の両方で異なるコンポーネントを通信するということです。 帯域幅が32バイトのIFインターフェイスは、AMD Zenの数世代にわたってキャッシュを相互に通信するために使用されており、キャッシュラインあたり32バイトから64バイトへのジャンプもその点でのジャンプを表しています。 Zen4アーキテクチャを備えたCCDおよびCCX内で循環するデータの量はZen3と比較してXNUMX倍になりました。
ただし、ノースブリッジまたはIODとの通信に関しては、 変更やGMはないようです Zen4コアを含むCCDチップレットを通信するポートは引き続き使用されます 書き込み用の16バイト/サイクルバスと32バイトバス。 / IODクロック速度で読み取るためのサイクル 。 Zenアーキテクチャでは、 使用するDRAMコントローラーのクロック速度 。 帯域幅を外挿した図では、IODのクロック速度が2400 MHzであると推測できます。これは、DDR5-4800のmemclkに対応します。
忘れられない IOハブのいずれか 。 これもIODまたはノースブリッジにあり、周辺機器との通信を担当します。 新しいI / Oインターフェースのサポートの結果としても改善された部品の4つであること。 USB5.0およびPCIExpressXNUMXの場合と同様です。 そのため、AMDは 750MHzから1150MHzまでの帯域幅 .
そのように役立つ PCIe4.0レーンの最大数が24回線から28回線になりました 。 この意味は マザーボード メーカー 2番目のM.XNUMXNVMeを統合できます SSD またはUSB4インターフェース 。 もちろん、これらの4つの追加行は、これらの最後の4つの段落に付随する表に示されているように、すべてのZenXNUMX互換チップセットで使用できるわけではありません。