The Infinity Cache is the most notable difference between the recently introduced RX 6000 series graphics cards (RX 6800, RX 6800 XT and RX 6900) with the Xbox Series X SoC GPU, also based on RDNA 2. ¿ But what exactly is the Infinity Cache, what is its use and how does it work? We are going to tell you all its secrets.
Since the weeks before the presentation of the RX 6000 we have known of the existence of this huge memory pool inside the GPU, huge because we are talking about the largest cache in the history of GPUs with about 128 MB of capacity . But AMD has not given much information about it, it has simply told us about its existence.


That is why a detailed explanation is necessary to understand why AMD has placed a cache of such size in the version of its RDNA 2 for PC.
Locating the Infinity Cache


The first point that is necessary to understand what the function of a piece is within the hardware is to deduce its function from its location within the system.
Since RDNA 2 is an evolution of RDNA , first of all, we have to take a look at the first generation of the current AMD graphics architecture, of which we know two chips that are Navi 10 and Navi 14.

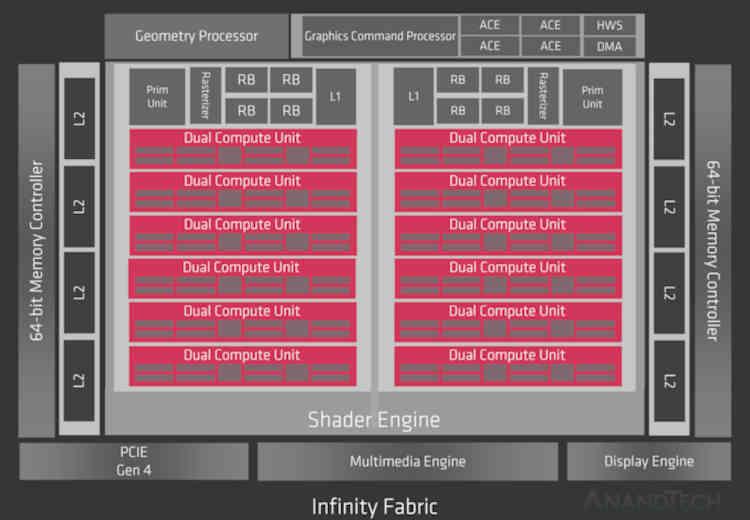

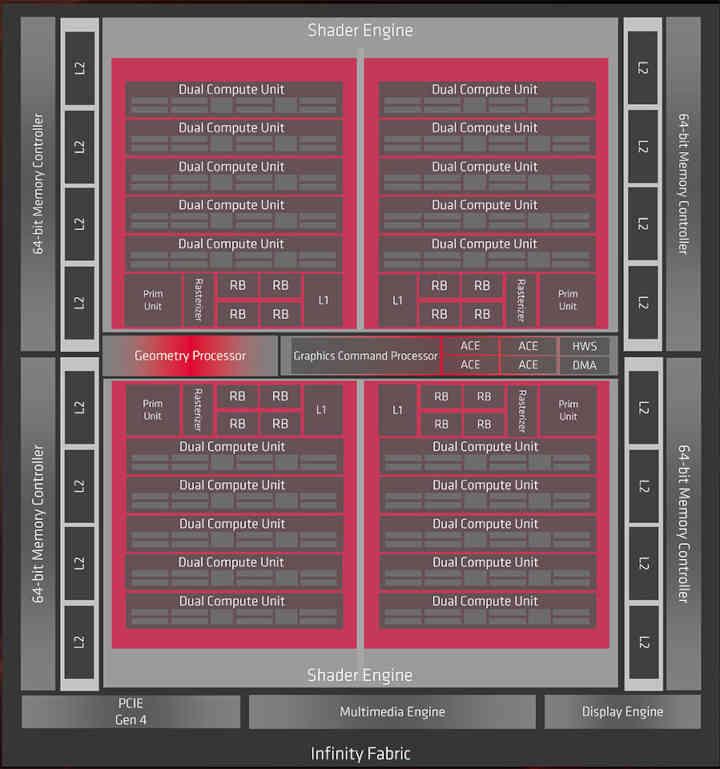
Well, if the Infinity Cache had been implemented in RDNA, it would be in the part that says Infinity Fabric of the diagram, so at the cache organization level we would go from this:
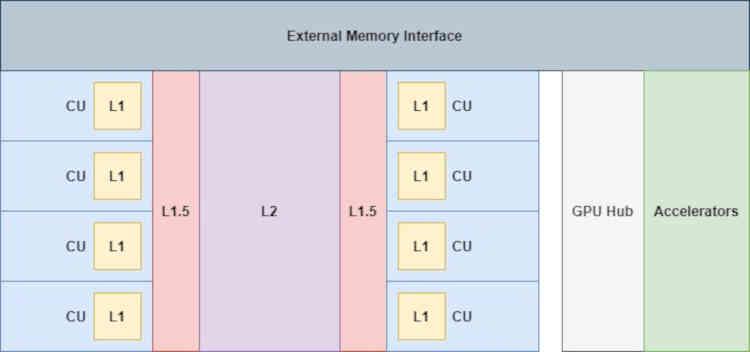
Where the accelerators connected to the GPU Hub (the video codec, the display controller, the DMA drives, etc.) have no direct access to the caches, not even the L2 cache.

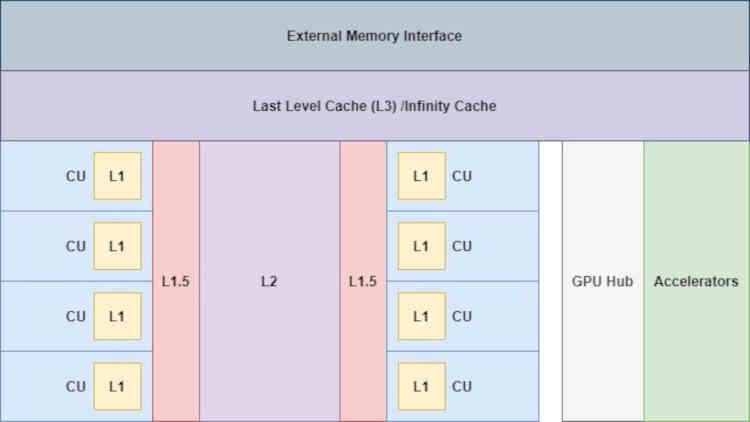

With the addition of the Infinity Cache things already change “a little”, since now the accelerators have access to this memory,
This is very important, especially for the Display Core Next, which is responsible for reading the final image buffer and transmitting it to the corresponding Display Port or HDMI interface so that the image is displayed on the screen, this is important in order to reduce accesses to VRAM by these units.
Remembering the RDNA cache system


In RDNA, the caches are connected to each other in the following way:


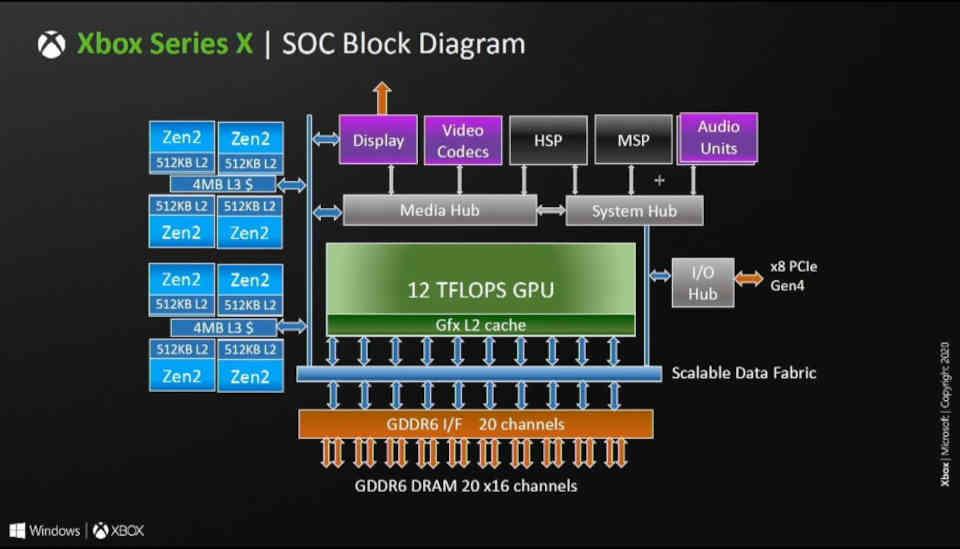
The L2 cache is connected to the outside to 16 channels of 32 Bytes / cycle each, if we look at the Navi 10 diagram then you will see how this GPU has about 16 L2 Cache partitions and a 256-bit GDDR6 bus to which they are connected.
Keep in mind that GDDR6 uses 2 channels per chip that operate in parallel, each of 16 bits.
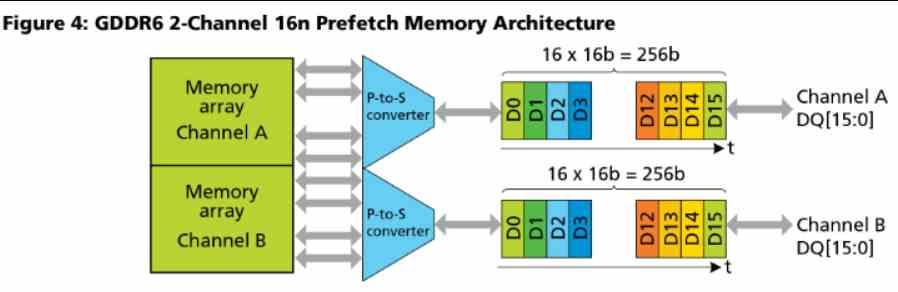

In other words, the number of L2 cache partitions in RDNA architectures is equal to the number of 16-bit GDDR6 channels that are connected to the graphics processor. In RDNA and RDNA 2 each partition is 256 KB, this is the reason why the Xbox Series X that has a 320-bit bus and therefore 20 GDDR6 channels has about 5 MB of L2 Cache.

A new level of cache: the Infinity Cache


Since it is an additional level of cache, the Infinity Cache has to be connected to the L2 cache directly, which is the previous level in the cache hierarchy, this is confirmed to us by AMD itself in a footer:
Measurement calculated by AMD engineers, on a Radeon RX 6000 series card with 128MB AMD Infinity Cache and 256-bit GDDR6. Measuring the average AMD Infinity Cache success rates in 4k games of 58% across major game titles, multiplied by the theoretical maximum bandwidth of the 16 64B AMD Infinity Fabric channels connecting the cache to the graphics engine at a boost frequency up to 1.94 GHz.
The GPU used in the RX 6800, RX 6800 XT and RX 6900 is Navi 21 which has a 256-bit GDDR6 bus, ergo it has 16 channels and hence the 16 partitions of Caché L2 being each connected to a partition of the Infinity Cache.
As for the issue of “hit rates” of 58%, it is more complicated and is what we will try to explain below.
Tile Caching on NVIDIA GPUs


Before continuing with the Infinity Cache we have to understand the reasons for its existence and for this we have to look at how GPUs have evolved in recent years.
Starting with the NVIDIA Maxwell, GeForce 900 Series, NVIDIA made a major change in their GPUs that they called Tile Caching, whose change involved connecting the ROPS and the raster unit to the L2 cache.
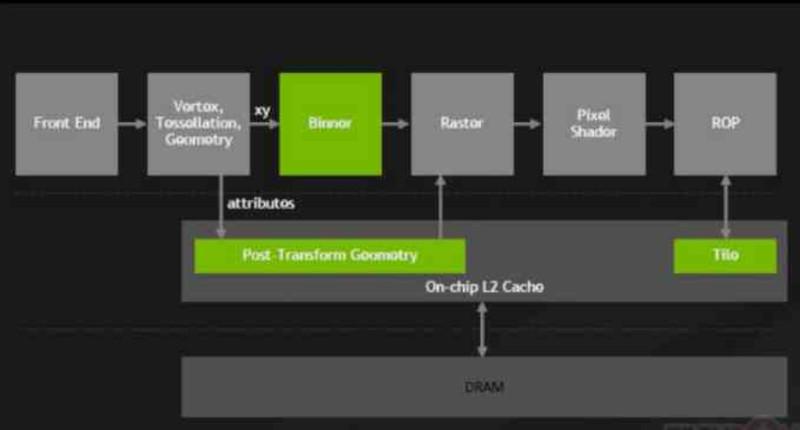
With this change, the ROPS stopped writing to the VRAM directly, the ROPS are common in all GPUs and are responsible for creating the image buffers in memory.

Thanks to this change, NVIDIA was able to reduce the energy impact on the memory bus by reducing the amount of transfers that were made to and from the VRAM and with this, NVIDIA managed to gain energy efficiency from AMD with the Maxwell and Pascal architectures.
DSBR, the Tile Caching on AMD GPUs
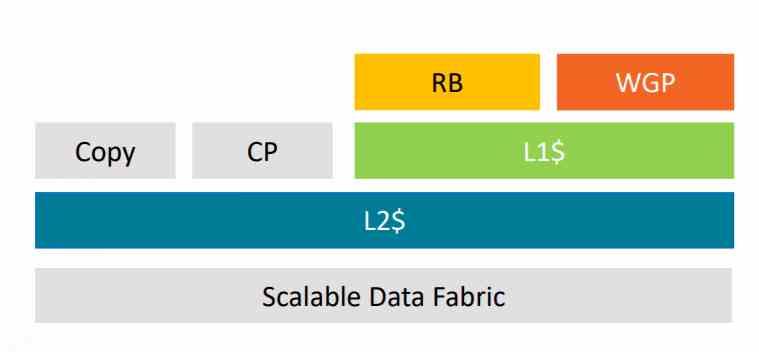
AMD, on the other hand, during all generations of the GCN architecture prior to Vega, connected the Render Backends (RB) directly to the memory controller.


But starting with the AMD Vega, he made two changes in the architecture to add Tile Caching to his GPUs, the first of them was to renew the raster unit, which he renamed DSBR, Draw Stream Binning Rasterizer.


The second change was that they connected the raster unit and ROPS to the L2 cache, a change that still exists in RDNA and RDNA 2.

The utility of DSBR or Tile Caching
The Tile Caching or DSBR is efficient because it orders the geometry of the scene according to its position on the screen before it is rasterized, this was an important change since the GPUs before the implementation of this technique ordered the already textured fragments just before sending them to the image buffer.

In Tile Caching / DSBR what is done is to order the polygons of the scene before they are converted into fragments by the rasterization unit.

In Tile Caching, polygons are ordered according to their screen position in tiles, where each tile is a fragment of n * n pixels.
One of the advantages of this is that it allows to eliminate beforehand the non-visible pixels of the fragments that are opaque when being in the same situation. Something that cannot be done if the elements that make up the scene are ordered after texturing.
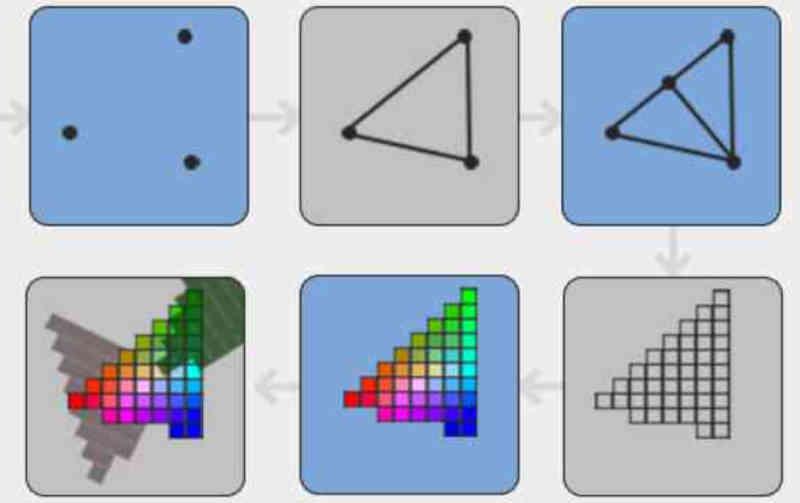

This saves the GPU from wasting time on superfluous pixels and improves the efficiency of the GPU. In case you find this confusing, it is as simple as remembering that throughout the graphical pipeline the different primitives that make up the scene take different forms during the different stages of it.
Tile Caching or DSBR is not equivalent to Tile Rendering

Although the name can be misleading, Tile Caching is not equivalent to Tile Rendering for the following reasons:
- Tile renderers store scene geometry in memory, order it, and create screen lists for each tile. This process does not occur in the case of Tile Caching or DSBR.
- In Tile Rendering, the ROPS are connected to scratchpad memories outside the cache hierarchy and do not empty their content into the VRAM until that tile has been 100% finished, so the hit rates are 100%.
- In the Tile Caching / DSBR, since the ROPS / RBs are connected to the L2 Cache, at any time the cache lines from L2 to RAM may be discarded, so there is no guarantee that 100% of the data is in the L2 cache.
Since there is a high probability of cache lines ending up in VRAM, what AMD has done with the Infinity Cache is to add an additional cache layer that collects the discarded data from the GPU’s L2 cache.
The Infinity Cache is a Victim Cache
The Victim Caché idea is a legacy of CPUs under Zen architectures that has been adapted to RDNA 2.
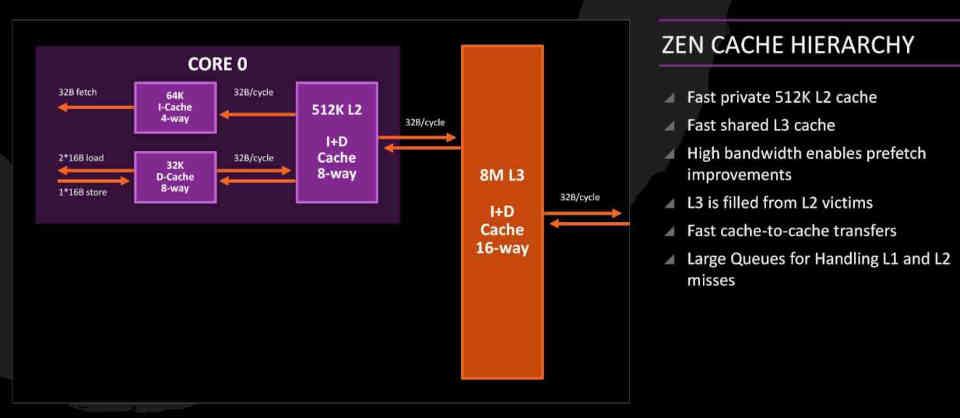


In the Zen cores the L3 Cache is what we call a Victim Caché, these are in charge of collecting the cache lines discarded from the L2 instead of being part of the usual cache hierarchy. That is to say, in Zen cores the data that comes from RAM does not follow the path RAM → L3 → L2 → L1 or vice versa, but instead follows the path RAM → L2 → L1 since the L3 cache acts as Victim Caché.
In the case of the Infinity Cache, the idea is to rescue the lines of the L2 Cache of the GPU without having to access the VRAM , which allows the energy consumed per instruction to be much lower and therefore higher speeds can be achieved. clock.
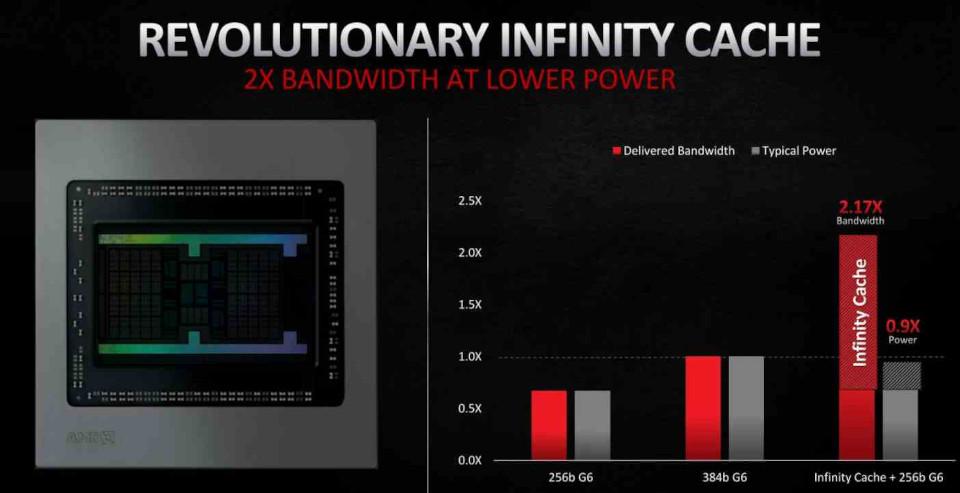

However, although the capacity of 128 MB may seem very high, it does not seem enough to avoid that all the discarded lines end up in the VRAM, since in the best of cases it only manages to rescue 58% . This means that in future iterations of its RDNA architecture it is very likely that AMD will increase the capacity of this Infinity Cache .