यह विवाद का परिणाम है कि उपयोगकर्ताओं के लिए तोप चारे का कम उपयोग उस प्रौद्योगिकी के शुद्ध आनंद से संबंधित है जो दोनों कंपनियां प्रदान करती हैं और फिर भी यह एक तथ्य है जिसे Radeon X800 के बाद से बनाए रखा गया है। NVIDIA 2005 के अंत में ग्राफिक्स कार्ड की कमान संभाली और तब से 15 साल तक लोहे की मुट्ठी के साथ शासन किया, लेकिन क्या रुक रहा है एएमडी लॉन्च करने से GPU जो अपने प्रतिद्वंद्वी से बेहतर प्रदर्शन करता है?
कई प्रमुख कारक हैं जो बाजार में नए जीपीयू को लॉन्च करते समय एनवीआईडीआईए हमेशा स्पष्ट रहे हैं और एएमडी ने केवल दो साल के लिए समझना शुरू कर दिया है।

ये कारक वास्तव में स्वयं आर्किटेक्चर से परे प्रासंगिक नहीं हैं, लेकिन उनके पास दिलचस्प संकेत हैं जो एक स्पष्ट संदेश छोड़ते हैं जो वर्तमान ग्राफिक्स परिदृश्य को बदलने का वादा करता है।
आर्किटेक्चर
हम इस आधार पर शुरू करते हैं कि हम एक GPU की प्रकृति को इस तरह समझते हैं, अर्थात्, वे एफपी संचालन के शानदार "विशाल कैलकुलेटर" हैं, इसलिए वे समानांतर संचालन के लिए महान हैं। भारी संख्या में गणना एफपीयू इकाइयों द्वारा की जाती है और सीपीयू के विपरीत, ये इकाइयां सॉफ्टवेयर डिजाइनरों द्वारा प्रोग्राम करने योग्य नहीं होती हैं, बल्कि सभी कुछ अधिक सारगर्भित होती हैं और पूरी तरह से ड्राइवर पर निर्भर करती हैं जो उनका समर्थन करता है।
यह AMD और NVIDIA को अपने उत्पादों को अनुकूलित करने के लिए छोड़ देता है क्योंकि पीसी पर कुछ डिवाइस होते हैं। इसी समय, यह इस लेख के मुख्य तर्क के साथ समस्या की शुरुआत है, और यह है कि NVIDIA इतनी बड़ी मात्रा में संसाधनों का आवंटन करता है कि इसके विकास समूह को आंतरिक रूप से "NVIDIA सेना" के रूप में संदर्भित किया जाता है।

सॉफ्टवेयर डेवलपर्स की संख्या उनके पास एएमडी से कहीं बेहतर है और यहां उनके जीपीयू की श्रेष्ठता का हिस्सा है। यह समझना चाहिए कि आर्किटेक्चर में और ठीक 2005 के अंत से, ग्राफिक्स कार्ड के पास काम करने के लिए एक ही इकाइयाँ हैं: ALUs / FPU TMUs और ROP (संगत कैश और स्पष्ट VRAM के अलावा) और केवल Turing ने नया RT लगाया है विभिन्न कार्यों के लिए कोर और सेंसर करोड़।
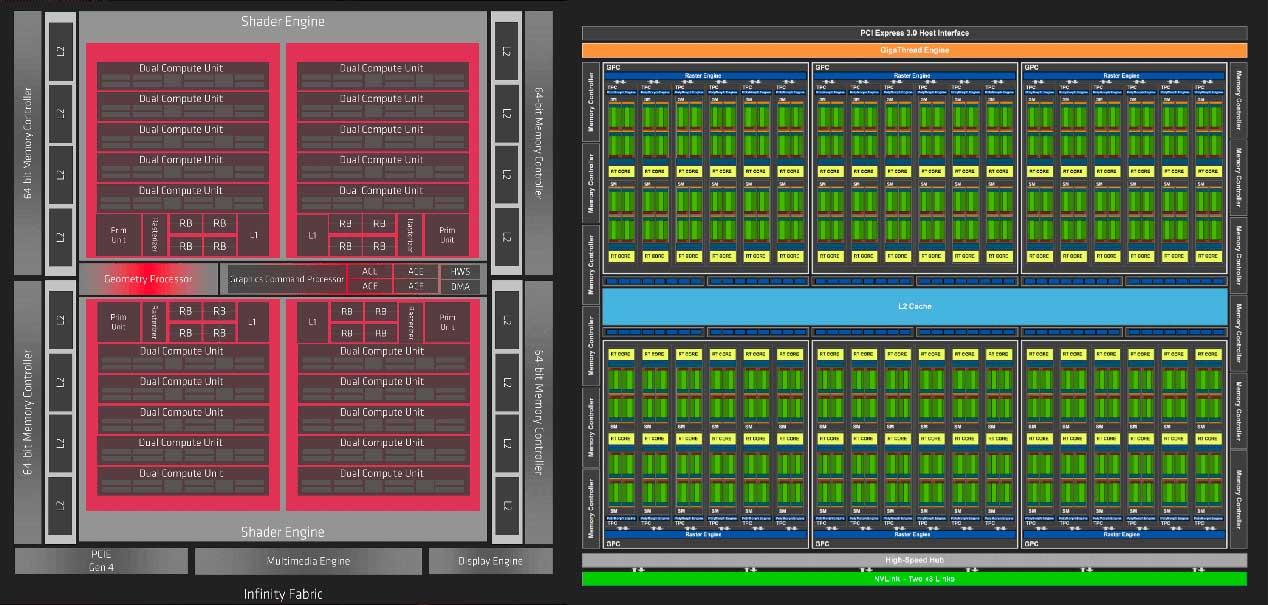
यह फिर से मानता है कि वास्तु सुधार के साथ युग्मित सॉफ़्टवेयर अनुकूलन प्रत्येक पीढ़ी के लिए एक बड़ा अंतर बनाता है यदि आप प्रतिद्वंद्वी की तुलना में तेजी से आगे नहीं बढ़ते हैं। विशिष्ट होने के लिए, वास्तुकला के रूप में नवी में दो शामिल हैं शेडर इंजन ब्लॉक एएमडी बदले में प्रसिद्ध में विभाजित होता है अतुल्यकालिक गणना इंजन (ACE) , जहां हर एक में 5 WGP और दो CUs हैं।
शुद्ध तुलना के लिए, ट्यूरिंग में एनवीआईडीआईए है 6 टीपीसी के साथ 6 जीपीसी प्रत्येक में और दो एस.एम. प्रत्येक ब्लॉक के लिए। प्रत्येक वास्तुकला की संरचना के बारे में यह सरल दृष्टि हमें देखती है कि हुआंग के उन लोगों के समानांतर एएमडी की तुलना में बहुत अधिक और अधिक विन्यास है, जिसमें पूरी तरह से अधिक शक्तिशाली ब्लॉक हैं, लेकिन एक ही समय में जो कम ऊर्जा कुशल है आपके प्रतिद्वंद्वी का विकल्प।
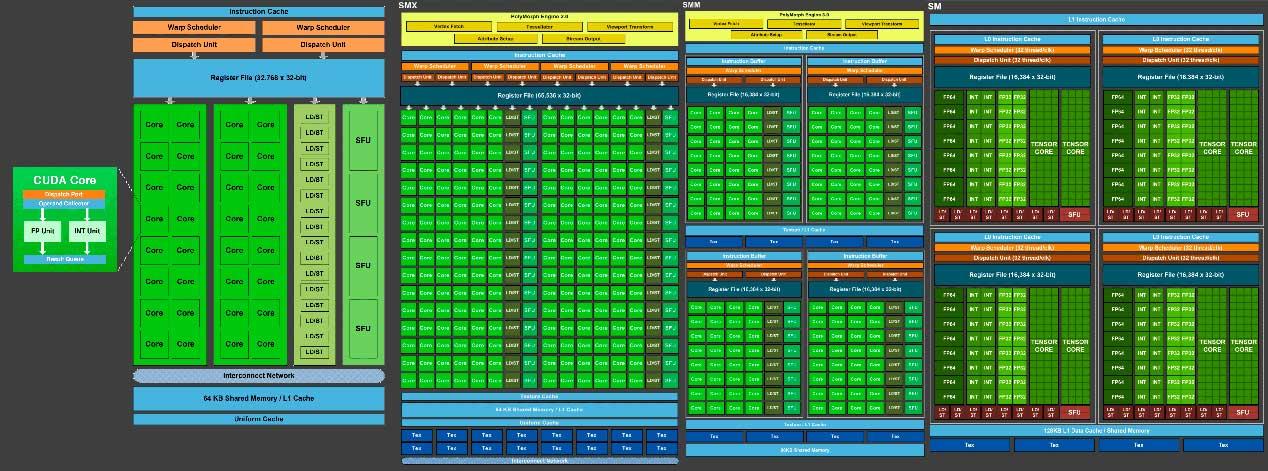
अंत में, यह समझना चाहिए कि दोनों आर्किटेक्चर के संचालन के दृष्टिकोण में एक क्रांतिकारी अंतर है, जो अतीत से आता है उसी के सरल विकास द्वारा: NVIDIA स्केलर निष्पादन इकाइयों के साथ काम करता है, एएमडी अपने हिस्से के लिए उन इकाइयों का उपयोग करता है जो साथ काम करते हैं वैक्टर।
इसका तात्पर्य क्या है? डेवलपर्स द्वारा काम करने के लिए एक पूरी तरह से अलग अनुकूलन और इसकी अपारदर्शिता के लिए एक ही समय में, यह एक दीवार है जो एएमडी की पेशकश करने वाली इकाइयों को तोड़ने की कोशिश करती है जो प्रोग्राम के लिए सरल और बेहतर संसाधनों के साथ हैं।
खपत
एक अन्य समस्या जो कि AMD के लिए वर्षों से है, और यह भी कि एक लिथोग्राफिक प्रक्रिया के साथ अपने प्रतिद्वंद्वी की तुलना में बहुत अधिक उन्नत है, यह आगे होने का प्रबंधन नहीं करता है। फिर, सब कुछ एक वास्तुकला और अनुकूलन समस्या है।
NVIDIA TPCs के किसी भी समूह और यहां तक कि पूरे GPC को मिलीसेकंड में निष्क्रिय करने में सक्षम है, कार्यभार को काफी हद तक अलग कर सकता है और साथ ही विभिन्न तकनीकों जैसे टाइल या उच्च-स्तरीय रंग संपीड़न के साथ मिलकर उनकी इकाइयों को और अधिक कुशलता से काम करता है और इसलिए वे इसे बढ़ावा देने का प्रबंधन करते हैं। कम ऊर्जा की खपत द्वारा प्रदर्शन।
अनुकूलन कुंजी है और यहाँ अपनी इकाइयों के संचालन के माध्यम से NVIDIA एक ही घड़ी चक्र में एएमडी से अधिक करने का प्रबंधन करता है। आपको इसे प्रदर्शन के दृष्टिकोण से इतना नहीं देखना चाहिए (जो स्पष्ट रूप से बेहतर है) लेकिन खपत से।
एक स्केलर यूनिट एक अस्थायी निर्देश और एक पूर्णांक एक ही समय और प्रति घड़ी चक्र की अनुमति देता है। NVIDIA में वास्तुकला का पुनर्गठन एक प्रोग्रामर को एएमडी की तुलना में वेक्टर ऑपरेशन के साथ सरल तरीके से काम करने की अनुमति देता है, खासकर अब जबकि ट्यूरिंग में प्रत्येक एसएम के भीतर तीन अलग-अलग अच्छी तरह से विभेदित इंजन हैं।
यह इन मोटरों पर बेहतर तरीके से ध्यान केंद्रित करने की अनुमति देता है, यह हो INT32 , FP32 या टेंसर कोर अनुमति देने, यदि आवश्यक नहीं है, तो संपूर्ण जीपीसी या इनमें से किसी भी मोटर को निष्क्रिय करने, खपत को बचाने और काम में अधिक कुशल होने के लिए। ।
मूल्य

जब हम GPU "बेहतर" के बारे में बात करते हैं तो यह एक निर्धारित कारक है। एनवीआईडीआईए के लिए, नवीन तकनीकों की पेशकश करने वाले उच्च मूल्यों की रणनीति ने इस समय काम किया है, लेकिन वास्तविकता यह है कि रे ट्रेसिंग और डीएलएसएस दोनों नेत्रहीन रूप से उतना बड़ा कदम नहीं है, जितना कि इरादा था, और वे विवाद या समस्याओं से मुक्त नहीं हुए हैं।
कम कीमत पर कम उत्पाद की पेशकश करने से यह प्रति से बेहतर नहीं होता है, आपको यह जानना होगा कि इसे आकर्षक तरीके से कैसे लगाया जाए। उपभोग और वास्तुकला के खंड सीधे इसकी ओर जाते हैं और अधिक से अधिक उपयोगकर्ताओं को कीमत देकर AMD को सबसे किफायती विकल्प के रूप में देखा जाता है।
एनवीआई ने इस बिंदु पर एनवीआईडीआईए को आश्चर्यचकित किया, क्योंकि वास्तुकला में सुधार गहरा रहा है और यह एक महत्वपूर्ण छलांग है जिसने अंतराल को कवर करने के लिए हुआंग के कार्ड की एक नई श्रृंखला शुरू की। लेकिन दुनिया भर में वास्तविकता यह है कि उपयोगकर्ता उन प्रौद्योगिकियों, प्रदर्शन और खपत को महत्व देता है जो एनवीआईडीआईए उच्च कीमत पर प्रदान करता है। यह कुछ भी नहीं है कि यह विश्व बाजार में 60% से अधिक का मालिक है, इसलिए हम उन लोगों की स्थिति में हैं जो अपनी नई तकनीकों का लाभ उठाने के लिए एक NVIDIA GPU के लिए कुछ और भुगतान करना चुन सकते हैं और जो लोग बस नहीं चाहते हैं विभिन्न कारणों के लिए उस अंगूठी के माध्यम से जाने के लिए।
किसी भी मामले में, 15 से अधिक वर्षों के लिए एएमडी सामान्य रूप से इस खंड में टो में रहा है। एनवीआईडीआईए अपने नए जीपीयू के साथ कीमतें तय करता है और एएमडी अपने जीपीयू के साथ अंतराल में भरता है।