Foveros by . जैसे पैकेजिंग सिस्टम की उपस्थिति के साथ इंटेल और TSMC द्वारा SoIC, तथाकथित एकीकृत सर्किट या 3DIC का उपयोग करने वाली प्रौद्योगिकियां धीरे-धीरे विकसित हो रही हैं, लेकिन उन सभी में एक बात समान है। इन शक्तिशाली विषम प्रोसेसरों के विभिन्न तत्वों को संप्रेषित करने के लिए ऊर्ध्वाधर अंतर्संबंधों का उपयोग।
प्रोसेसर को डिजाइन करते समय सबसे बड़ी चुनौतियों में से एक ऊर्जा की खपत है जो सूचना को संसाधित करते समय और सूचनाओं को स्थानांतरित करते समय होती है। समस्या तब आती है जब हाल के वर्षों में सभी इंजीनियरिंग प्रयासों को सबसे तेज़ निष्पादन इकाइयों को प्राप्त करने पर केंद्रित नहीं किया गया है, बल्कि पर्याप्त संचार होने पर प्रसंस्करण पर्याप्त तेज़ है।

भले ही कोई कंप्यूटर हार्वर्ड या वॉन न्यूमैन मॉडल का उपयोग करता हो, उसे एक मेमोरी की आवश्यकता होगी जिसे प्रोसेसर काम करने के लिए एक्सेस करता है। सरलतम सिस्टम में, यह मेमोरी एक अलग चिप पर होती है और इसे इंटरकनेक्ट या केबल के माध्यम से एक्सेस किया जाना चाहिए। खैर, बड़ी समस्या तब सामने आती है जब हम बुनियादी सिद्धांतों की एक श्रृंखला को ध्यान में रखते हैं।
पहला और सबसे महत्वपूर्ण तथ्य यह है कि एक केबल में प्रतिरोध जितना लंबा होता है, अगर हम ओम के नियम को ध्यान में रखते हैं तो हम जानेंगे कि वोल्टेज प्रतिरोध को तीव्रता से गुणा करने का परिणाम है। इसका अर्धचालकों से क्या लेना-देना है? आइए यह न भूलें कि वे छोटे पैमाने के विद्युत सर्किट हैं और इसलिए यदि डेटा को संचालित करने की दूरी बढ़ जाती है, तो ऊर्जा की खपत बढ़ जाएगी।
इसका कारण ऊर्जा खपत की गणना के मूल सूत्र में पाया जाता है, जो है: पी = वी 2 * सी * एफ। जहां वी वोल्टेज है, सी वह भार क्षमता है जिसे अर्धचालक झेल सकता है और एफ आवृत्ति है। खैर, हमने देखा है कि प्रतिरोध के साथ वोल्टेज कैसे बढ़ता है और हमें यह जोड़ना होगा कि यह घड़ी की गति के साथ भी बढ़ता है।
लंबवत अंतर्संबंध
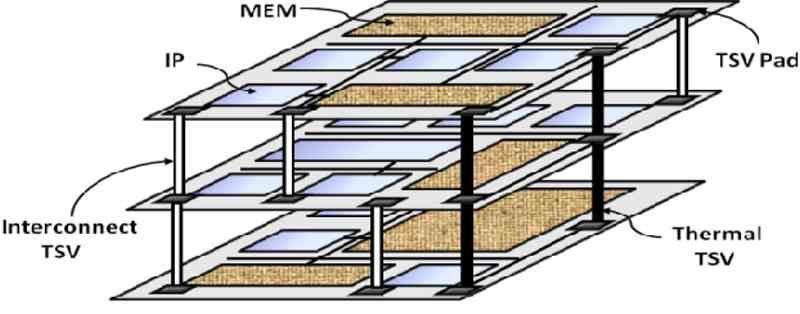
अब जब हमारे पास मूल सिद्धांत है तो हम पाते हैं कि मेमोरी को प्रोसेसिंग के करीब लाने के लिए केबल को छोटा करना इसका समाधान है। शुरू से ही हम एक सीमा पाते हैं और यह कोई और नहीं बल्कि बीच संचार है सी पी यू और रैम पीसीबी पर क्षैतिज रूप से होता है और प्रत्येक छोर से संबंधित संचार इंटरफ़ेस को रूट करता है, ताकि एक बिंदु पर हम दूरी को कम करना जारी नहीं रख पाएंगे।
चूंकि घड़ी की गति के साथ ऊर्जा की खपत तेजी से बढ़ती है, तो सबसे अच्छा समाधान संचार इंटरफेस में मौजूदा इंटरकनेक्शन की संख्या में वृद्धि करना है, लेकिन हम इसके आकार से सीमित हैं और चूंकि यह प्रोसेसर की परिधि पर स्थित है, इसका मतलब है कि इसका आकार बढ़ाएं, जिससे इसे बनाना और महंगा हो जाता है। समाधान? उक्त मेमोरी को चिप के ऊपर इस प्रकार रखें कि हमारे पास मैट्रिक्स वायरिंग हो सके।
दोनों चीजें संयुक्त रूप से हमें इंटरकनेक्शन की संख्या बढ़ाने की अनुमति देती हैं, जो समान बैंडविड्थ प्राप्त करने के लिए हमें घड़ी की गति को कम करने की अनुमति देती है, लेकिन हमारे पास यह भी फायदा है कि हमने संचार केबलिंग की दूरी कम कर दी है, इसलिए हम खपत भी कम करते हैं उस बिंदु पर। परिणाम? डेटा ट्रैफ़िक की ऊर्जा लागत में 10% की कमी करें।
एलएलसी समस्या और खपत

मल्टीकोर डिज़ाइन में, आइए CPU या a के बारे में बात करें GPU, हमेशा एलएलसी या अंतिम स्तर नामक एक कैश होता है जो प्रोसेसर से सबसे दूर होता है, लेकिन मेमोरी के सबसे करीब, इसका काम है:
- विभिन्न कोर की स्मृति को संबोधित करने में निरंतरता दें जो इसका हिस्सा हैं।
- रैम में किए बिना विभिन्न कोर के बीच संचार की अनुमति दें, इस प्रकार खपत को कम करें।
- यह विभिन्न कोर को एक सामान्य मेमोरी तक अच्छी तरह से पहुंचने की अनुमति देता है।
समस्या तब आती है जब एक डिज़ाइन में हम कई चिप्स बनाने के लिए कई कोर को एक दूसरे से अलग करने का निर्णय लेते हैं, लेकिन उन सभी के लिए समग्र रूप से कार्यक्षमता खोए बिना। पहली समस्या जिसका हमने सामना किया? उन्हें अलग करके हमने दूरी बढ़ा दी है और इसके साथ तारों का प्रतिरोध, ऊर्जा की खपत बढ़ गई है।
इंटरकनेक्ट कार्यान्वयन

खपत के कुछ स्तरों पर यह कोई समस्या नहीं है, लेकिन एक GPU में यह है और अचानक हम पाते हैं कि हम पारंपरिक संचार विधियों का उपयोग करके चिपलेट से बना एक ग्राफिक्स प्रोसेसर नहीं बना सकते हैं। इसलिए विभिन्न चिप्स को संप्रेषित करने के लिए ऊर्ध्वाधर इंटरकॉम का विकास, जिसका अर्थ है कि उन्हें एक सामान्य इंटरकॉम बेस के साथ लंबवत रूप से तार-तार करना होगा जिसे हम इंटरपोजर कहते हैं।
मल्टी-चिप डिज़ाइन तब मौजूद होते हैं जब जटिलता के स्तर तक पहुंचने के लिए आवश्यक होता है जहां एक चिप का आकार विनिर्माण और लागत के मामले में प्रतिकूल होता है, लेकिन यहां लंबवत इंटरकनेक्शन आमतौर पर इंटरपोजर के ऊपर विभिन्न तत्वों के बीच उत्पन्न होते हैं। लेकिन यह एक सीधा इंटरकनेक्शन जितना कुशल नहीं है, क्योंकि यह एक सापेक्ष अंतरसंचार दूरी भी है।

दूसरी ओर, जब हम एक छोटे पैमाने के चिप के साथ कार्यान्वयन के बारे में बात करते हैं, तो हम अंत में दो या दो से अधिक चिप्स को एक के ऊपर एक ढेर करने के लिए चुनते हैं और उन्हें लंबवत रूप से परस्पर जोड़ते हैं। ये दो मेमोरी, दो प्रोसेसर या मेमोरी और प्रोसेसर का संयोजन हो सकता है। वर्तमान हार्डवेयर में हमारे पास पहले से ही इसके कई मामले हैं, जैसे कि एचबीएम मेमोरी या 3डी-नंद फ्लैश, इंटेल से पहले ही वापस ले लिया गया लेकफील्ड और वी-कैश के साथ ज़ेन 3 कोर एएमडी.
तो 3DIC विज्ञान कथा नहीं है, यह कुछ ऐसा है जो हमने हार्डवेयर की दुनिया में कई वर्षों से किया है और इसमें एकीकृत सर्किट बनाना शामिल है जिसमें घटकों के बीच की बातचीत क्षैतिज के बजाय लंबवत रूप से की जाती है। जो अपने साथ उन लाभों को लाता है जिनका उल्लेख हमने ऊर्जा खपत के मामले में ऊर्ध्वाधर अंतर्संबंधों के बारे में पहले किया है।
