क्या यह संभव है कि भविष्य में आरटी कोर भविष्य के जीपीयू से गायब हो जाएंगे NVIDIA, इंटेल और / या एएमडी? क्या उनकी विशाल कंप्यूटिंग शक्ति के साथ शेडर इकाइयां समावेशन को पूरी तरह से डिस्पेंसेबल बनाने के लिए पर्याप्त हो सकती हैं? इस प्रकार की इकाइयों के?
आरटी कोर, रे एक्सेलेरेटर इकाइयाँ या चौराहे इकाइयाँ विशिष्ट इकाइयाँ हैं जो जीपीयू में एक ही कार्य के प्रभारी हैं और जो पहली बार आरवीएक्स आरएक्सएक्स के हाथ से पहली बार आई थीं।

इस लेख में हम यह नहीं बताएंगे कि वे क्या हैं, इसके लिए हम आपको हार्डज़ोन शीर्षक में लेख देखने की सलाह देते हैं रे ट्रेसिंग के लिए आरटी कोर क्या हैं और वे कैसे काम करते हैं? जिसमें हम एक सरल लेकिन विस्तृत तरीके से इस प्रकार की इकाइयों के संचालन के बारे में बताते हैं।
आरटी कोर या चौराहे इकाइयाँ क्या हैं?
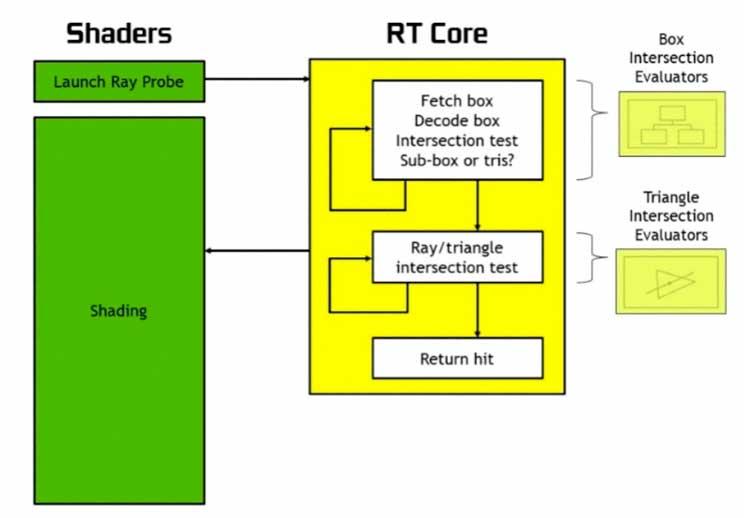
AMD में NVIDIA या रे एक्सीलरेटर इकाइयाँ में RT कोर, वे किरणें और दृश्य के विभिन्न तत्वों के बीच चौराहे की गणना करने के लिए इकाइयाँ हैं, जो यह समझने के लिए हैं कि नए ग्राफिक्स कार्ड के हार्डवेयर में इस प्रकार की इकाई की क्या आवश्यकता है। समझना होगा कि किरण अनुरेखण एल्गोरिथ्म का सबसे सरल संस्करण कैसे काम करता है:
प्रत्येक पिक्सेल या ऑब्जेक्ट के लिए जिसमें पिक्सेल स्थित है, यदि किरण उक्त वस्तु के साथ अंतर करती है: स्क्रीन पर उस पिक्सेल का रंग मूल्य बदल जाता है।
यह प्रत्येक और हर एक फ्रेम में दोहराव से किया जाता है GPU रेंडर ट्रेसिंग एल्गोरिथ्म या इसके किसी एक वेरिएंट का उपयोग करके उत्पन्न होने वाले रेंडरर्स, या तो आंशिक रूप से अप्रत्यक्ष प्रकाश की समस्याओं को हल करने के लिए होते हैं जो कि रेखांकन स्वयं से हल नहीं कर सकते हैं।
मोलर - किरणों और त्रिभुजों के बीच के चौराहे के लिए ट्रंबोर एल्गोरिदम
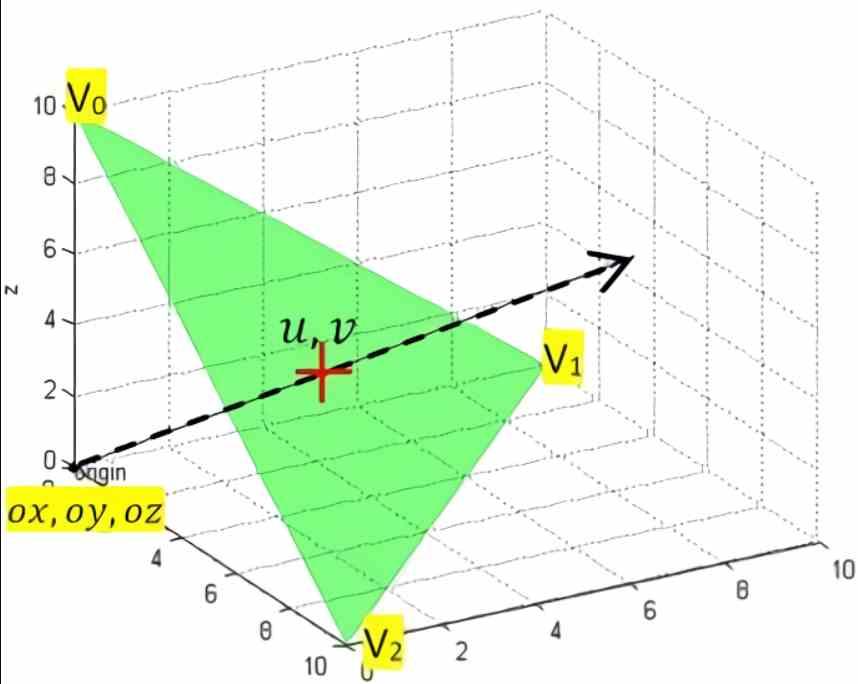
रे चौराहे की इकाइयाँ निश्चित कार्य इकाइयाँ होती हैं जो मोलर-ट्रंबोर एल्गोरिदम । यह ध्यान में रखा जाना चाहिए कि फ़िक्स्ड फंक्शन इकाइयाँ हमेशा कुछ इनपुट डेटा से एक ही प्रोग्राम को लागू करती हैं, कहा गया प्रोग्राम माइक्रो-वायर्ड है, इसलिए कहा जाता है कि मेक-अप करने वाले ट्रांजिस्टर को इस तरह से रखा जाता है कि वे केवल उसे चला सकें कार्यक्रम और दूसरा नहीं।
फिक्स्ड फंक्शन यूनिट्स का फायदा यह है कि उन्हें प्रोग्रामेबल यूनिट्स की तुलना में कम ट्रांजिस्टर की जरूरत होती है, जो कि ज्यादा जटिल होती है, लेकिन एक फिक्स्ड फंक्शन यूनिट केवल हार्डवेयर में ही काम करती है, जहां प्रोग्रामेबल यूनिट्स एक समय में अपना काम कर सकती हैं। गति और लागत स्तर पर गति प्रोग्रामयोग्य भाग से मेल नहीं खा सकती है।
जाहिर है, किसी भी एल्गोरिथ्म की तरह, इसे shader इकाइयों में निष्पादित करना संभव है, लेकिन इसके लिए संभव होने के लिए यह आवश्यक होगा कि उक्त इकाइयों को निश्चित फ़ंक्शन इकाइयों के साथ तेजी से फैलाने के लिए पर्याप्त हो।
मोलर की लागत - ट्रंबोर एल्गोरिदम

इस तथ्य के बावजूद कि अधिक एल्गोरिदम हैं, यह सबसे प्रसिद्ध और उपयोग किया जाता है, यही कारण है कि हमने इसे एक उदाहरण के रूप में उपयोग करने का निर्णय लिया है और मेरा विश्वास है कि इसकी लागत सीधे सस्ती नहीं है क्योंकि कुल मिलाकर प्रति पिक्सेल 27 फ़्लोटिंग पॉइंट ऑपरेशन हैं । लेकिन, कुछ आर्किटेक्चर में, क्योंकि डिवीजन शादर्स में लागू करने के लिए अधिक जटिल है, यह पारंपरिक SIMD इकाइयों द्वारा नहीं बल्कि एसएफयू द्वारा किया जाता है, जो बहुत अधिक जटिल अंकगणितीय ऑपरेशन कर सकता है, लेकिन रकम की तुलना में कम गति के साथ। और गुणन।
दूसरे शब्दों में, हमें पिक्सेल या प्रतिच्छेदन के अनुसार प्रति पिक्सेल 27 FLOPS की आवश्यकता होगी, अब एक दृश्य में चौराहों और पिक्सेल की संख्या के बारे में सोचें और आपको इस बात का अंदाज़ा हो जाएगा कि चौराहे की इकाइयाँ या RT कोर इतने आवश्यक क्यों हैं।
आरटी कोर को बदलने वाले शेड प्रोग्राम का प्रकार
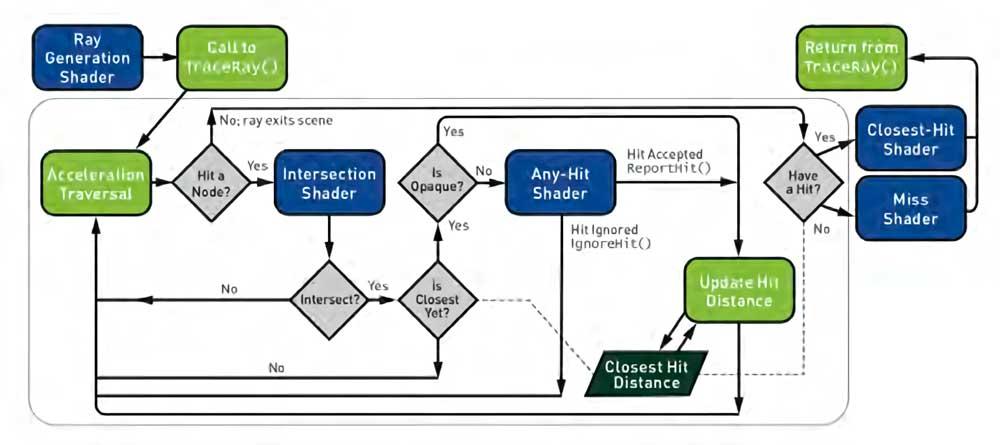
वास्तविक समय रे ट्रेसिंग के लिए API विशिष्टताओं में, DX12 अल्टीमेट के भीतर DXR में और वुलकन के लिए रे ट्रेसिंग एक्सटेंशन दोनों में, एक प्रकार का शेडर है जो अप्रचलित हो गया है, जो कि इन्टरसेक्शन शैडर है, जो इसे पूरी तरह से प्रतिच्छेदन इकाइयों में बदल देता है हार्डवेयर में जहां वे मौजूद नहीं हैं।
ध्यान रखें कि एक शेडर एक प्रोग्राम से ज्यादा कुछ नहीं है और इस तथ्य से कि प्रोग्रामर को अपनी खुद की चौराहे की यूनिट गेम को गेम से बनाना है, एक टेडियम हो सकता है, इसीलिए दोनों API में उदाहरण चौराहे शेड शामिल हैं। इसके लिए व्यापार बंद? कई डेवलपर्स चौराहे एल्गोरिथ्म को एपीआई में शामिल के साथ-साथ निश्चित फ़ंक्शन इकाइयों को भी अनुपयुक्त देख सकते हैं।
हार्डवेयर डिज़ाइन में, फिक्स्ड फंक्शन यूनिट्स को खत्म करना सामान्य नहीं है, जो कि एक्सीलेटर के रूप में कार्य करते हैं, बल्कि यह सामान्य है कि उक्त इकाइयों की क्षमताओं का विस्तार किया जाए और यहां तक कि इन यूनिटों को प्रोग्राम योग्य बनाया जाए, इसलिए चौराहा इकाइयों के विकास में अगला कदम, यदि यह पहले से नहीं किया गया है, यह माइक्रो-प्रोग्राम कोड के साथ एक विशिष्ट डोमेन उद्देश्य के लिए है जिसे अपडेट किया जा सकता है।
इसलिए, यह संभव है कि हम नए चौराहे एल्गोरिदम के निर्माण को बेहतर प्रदर्शन के साथ देखेंगे, जो एक फर्मवेयर अपडेट के साथ प्रत्येक यूनिट की आंतरिक मेमोरी में लिखे गए हैं।
निश्चित फ़ंक्शन इकाइयों को कभी भी एक जीपीयू से नहीं हटाया गया है

GPU में 3D ग्राफिक्स रेंडर करने के लिए फिक्स्ड फंक्शन यूनिट्स की एक श्रंखला होती है, ये इकाइयाँ, जैसे कि प्रतिच्छेदन इकाइयाँ, प्रत्येक फ्रेम में दोहराव और दोहराव वाले कार्य करने के लिए जिम्मेदार होती हैं। हम बुनावट इकाइयों को संदर्भित करते हैं, जो रेखांकन रेखापुंज के प्रभारी हैं, आदि।
इन इकाइयों को इस तथ्य के कारण कभी भी समाप्त नहीं किया गया है कि उनके कार्यों को एक shader इकाई द्वारा किया जा सकता है, क्या अधिक है, अगर हमने बिना किसी निश्चित इकाइयों के GPU लिया और उन्हें 3D में एक दृश्य प्रदान किया, तो वे परिमाण का एक क्रम होगा कम shader इकाइयों के साथ GPU से अधिक अक्षम लेकिन उन इकाइयों के साथ शामिल थे।
प्रवृत्ति हमेशा यह होती है कि एक ऐसा भाग दिखाई देता है जो प्रत्येक फ्रेम में दोहराव और दोहराव वाला होता है, जो कि शेड्स को निष्पादित करने वाली इकाइयों के समय और संसाधनों के एक अच्छे हिस्से पर कब्जा कर लेता है, क्योंकि यह एक प्रकार की विशेष इकाई का निर्माण करता है जो केवल निर्वहन करता है कहा कि कार्य से उन इकाइयों के लिए लेकिन यह और अधिक जल्दी और लागत के एक हिस्से के लिए करने के लिए।