AMDLes architectures graphiques Radeon de Radeon ont peu changé ces dernières années par rapport à la concurrence, puisque GCN lancé en 2012, nous sommes passés à RDNA en 2019, qui a récemment subi une refonte avec RDNA. Mais quelle a été réellement l'évolution des GPU AMD? Lisez la suite pour en savoir plus sur les changements d'architecture de GCN à RDNA 2.
Tandis que NVIDIA a eu beaucoup de GPU architectures ces dernières années, AMD est traditionnellement plus conservateur, conservant la même architecture GPU avec des modifications mineures pendant des années. Nous l'avons vu avec GCN, qui était l'architecture GPU AMD depuis plusieurs générations et nous le voyons avec RDNA, où les feuilles de route indiquent déjà l'existence d'un futur RDNA 3 avec moins de changements que ceux que nous allons voir dans NVIDIA Lovelace. et Hopper.


Mais nous n'allons pas regarder vers le futur comme Prométhée, mais être plus Epiméthée et regarder à la fois vers le passé et vers le présent et nous allons le faire dans le cas d'AMD pour vraiment savoir comment les différentes architectures d'AMD ont évolué. La comparaison ne se fait donc pas au niveau des générations, ni entre les cartes graphiques entre elles, mais pour comprendre comment s'est déroulée l'évolution de GCN vers RDNA 2.
L'évolution du GCN au RDNA
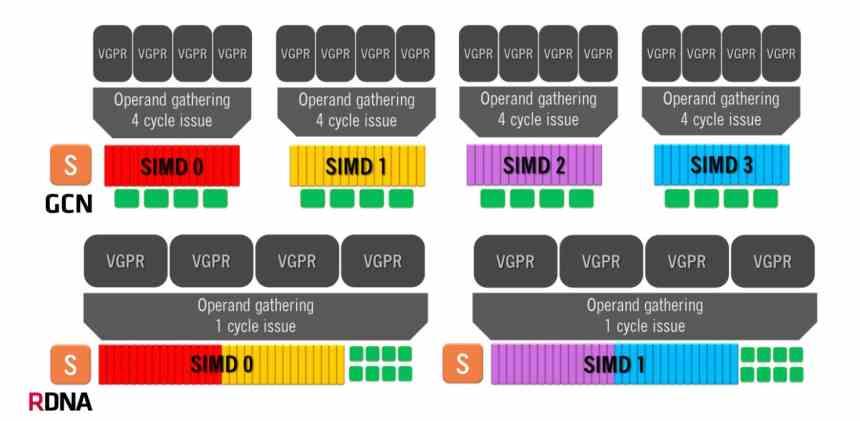
L'architecture Graphics Compute Next utilise une unité de calcul composée de 4 groupes SIMD de 16 ALU chacun, qui gère des vagues de 64 éléments. Cela signifie que dans le meilleur des cas, où une instruction est résolue par cycle, l'architecture GCN va prendre 4 cycles d'horloge par onde de 64 éléments.
Par contre, les architectures RDNA ont un fonctionnement différent, puisque nous avons deux groupes de 32 ALU et que la taille des ondes est passée de 64 éléments à 32 éléments. La même taille que NVIDIA utilise dans ses GPU, donc maintenant le temps minimum par vague est de 1 cycle unique car nous avons les 32 unités d'exécution fonctionnant en parallèle. Bien que le nombre moyen d'instructions résolues soit encore de 64, c'est une organisation beaucoup plus efficace.
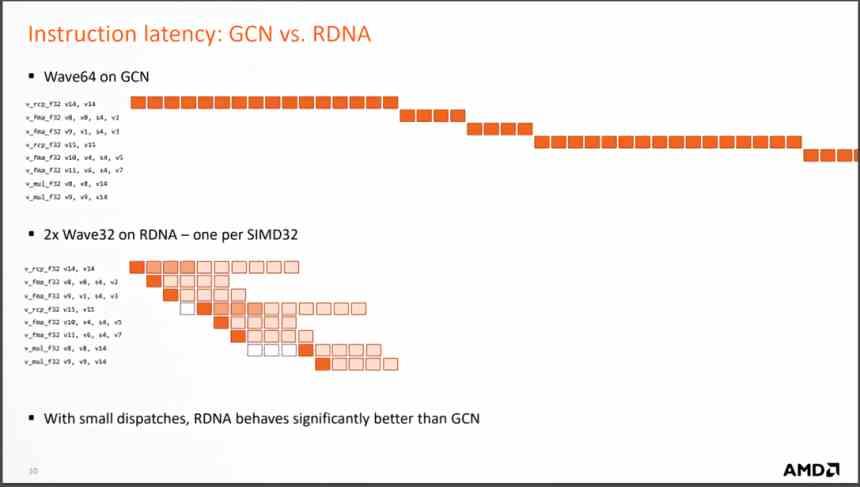
Mais le changement le plus important est le changement lors de l'exécution des instructions qui arrivent de chaque vague, puisque RDNA les résout en beaucoup moins de cycles, ce qui signifie que le nombre moyen d'instructions par cycle qui sont résolues est beaucoup plus grand. et avec lui, l'IPC moyen augmente.
Qu'est-ce que cela signifie? Eh bien, étant donné que beaucoup moins d'unités de calcul sont nécessaires pour obtenir les mêmes performances, moins d'unités de calcul signifie un GPU plus petit pour obtenir les mêmes performances. En fait, AMD a commencé à faire la conception RDNA dès qu'ils ont vu une GTX 1080 avec «seulement» 40 SM balayant le sol avec les unités de calcul AMD Vega 64. C'est à ce moment-là qu'ils ont vu comment l'architecture GCN ne se donnait pas plus d'elle-même.
Évolution du système de cache

Pour comprendre l'évolution d'une architecture graphique à une autre, il est important de connaître le système de cache et son évolution d'une génération à l'autre.
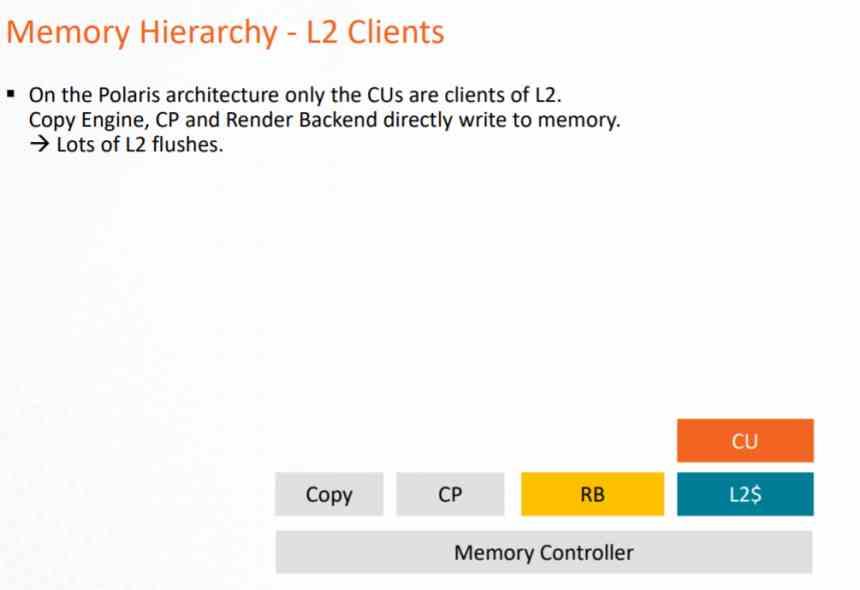
Dans l'architecture GCN, le système de cache ne pouvait être utilisé que par le pipeline de calcul, puisque les Pixel Shaders lors de leur exécution exportent vers le ROPS et ceux-ci directement sur la VRAM, ce qui suppose une très forte charge sur la VRAM et une consommation d'énergie très importante. .

Ce problème a été résolu à la fin de la vie de cette architecture avec AMD Vega, où le ROPS et l'unité raster communiquaient au cache L2 afin de réduire la charge sur le bus de données vers la VRAM. Mais surtout pour appliquer le DSBR ou Tiled Caching, qui consiste à adopter le Tile Rendering, mais partiellement et que NVIDIA avait déjà adopté chez Maxwell.

Dans RDNA, le principal changement était de faire que tout devienne client L2, mais en ajoutant un cache intermédiaire qui est L1, la nomenclature a changé de cette façon.
- Le cache L1 inclus dans Compute Units devient le cache L0, avec la même fonctionnalité.
- Un cache L1 est ajouté, qui est intermédiaire entre le cache L0 et le cache L2.
- Tous les éléments du GPU passent désormais par le cache L2.
Toutes les opérations d'écriture sont effectuées directement sur le cache L2, tandis que le cache L1 est en lecture seule. Ceci est fait pour éviter de mettre en œuvre un système de cohérence plus complexe sur le GPU qui occuperait un grand nombre de transistors. Étant donné que grâce au cache L1 en lecture seule, vous pouvez accorder les données à plusieurs clients au sein du GPU en même temps.
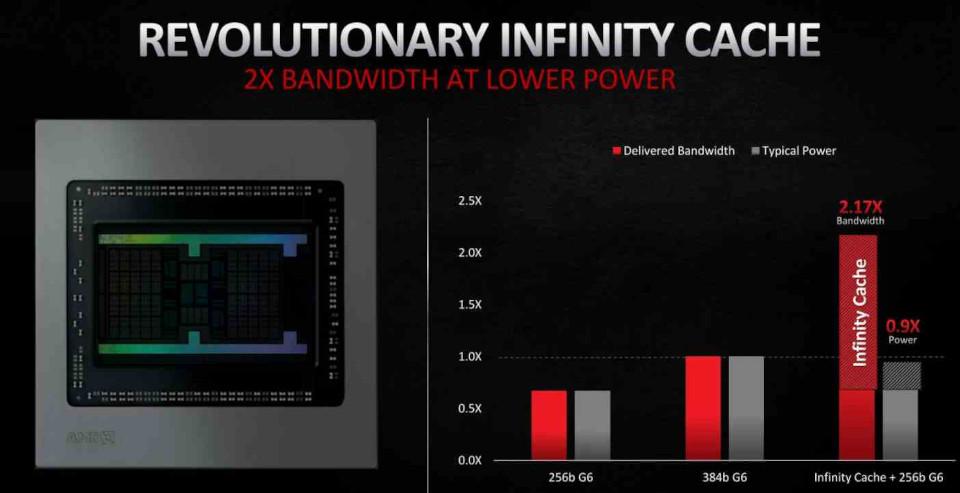
Dans RDNA 2, l'inclusion la plus importante a été sous la forme de Cache infini, qui n'agit pas comme un cache L3 conventionnel mais comme un Victim Cache, en adoptant les lignes de cache rejetées par le cache L2, de cette manière on évite que ces données tombent dans la VRAM, ce qui facilite sa récupération et, comme nous le verrons plus loin , il réduit le coût énergétique de certaines opérations, ce qui en fait un élément clé pour l'amélioration de RDNA 2.
La localisation des données est importante en ce qui concerne la consommation d'énergie. Puisque plus la distance qu'une donnée doit parcourir est grande, plus la consommation d'énergie est grande. C'est là qu'intervient Infinity Cache, ce qui vous permet de travailler avec les données avec une consommation beaucoup plus faible.
RDNA 2, une évolution mineure

RDNA 2, en revanche, est une version légèrement améliorée de RDNA et non un changement moins radical, AMD serait donc revenu à la stratégie de lancer des améliorations continues sur la même architecture. AMD aurait publié RDNA au cours du second semestre de 2019 en tant que solution temporaire pendant qu'ils terminaient le polissage de RDNA 2, qui est la version déjà terminée de l'architecture et entièrement compatible avec DirectX 12 Ultimate.
Si l'on parle en termes de calcul, RDNA 2 n'a aucun avantage sur RDNA et les améliorations ont été apportées plutôt dans des éléments autres que la partie en charge de l'exécution des shaders.
- L'unité de texture a été améliorée et une unité d'intersection de rayons a été ajoutée pour le lancer de rayons.
- Les unités ROPS et raster ont été améliorées pour prendre en charge l'ombrage à taux variable.
- Le GPU prend désormais en charge des vitesses d'horloge plus élevées.
- Inclusion du cache Infinity pour réduire la consommation d'énergie de certaines instructions.
L'une des clés pour pouvoir atteindre une vitesse d'horloge plus élevée dans un processeur est de super-segmenter le pipeline, mais c'est quelque chose qui ne peut pas être fait dans l'unité de shader d'un GPU de la même manière que dans un Processeur. Car ce qu'AMD a fait en interne est de mesurer la consommation d'énergie de chaque instruction que l'unité de calcul peut exécuter. Comme il existe des instructions qui consomment moins d'énergie, elles peuvent être exécutées à une vitesse d'horloge plus élevée, ce qui permet d'atteindre des vitesses de pointe plus élevées au moment de les exécuter.
