
Die Von Neumann-Architektur ist die gemeinsame Architektur aller PC-Prozessoren. Jede einzelne der CPUs von ARM bis x86, von 8086 bis Ryzen durch Pentium. Alle von ihnen sind von Neumann-Architekturen und sie alle erben ein bestimmtes gemeinsames Problem.
John Von Neumann war ein in Ungarn geborener Mathematiker, der für zwei Dinge berühmt ist. Die erste ist die Arbeit am Manhattan-Projekt, bei dem die Atombombe entwickelt wurde, die die USA am Ende des Zweiten Weltkriegs gegen Japan abgeworfen hatten. Die zweite ist die Entwicklung der Basisarchitektur, die unsere PCs heutzutage verwenden, unabhängig von ihrer Größe sowie der Form der von ihnen ausgeführten Programme.
Was ist Von Neumann-Architektur?
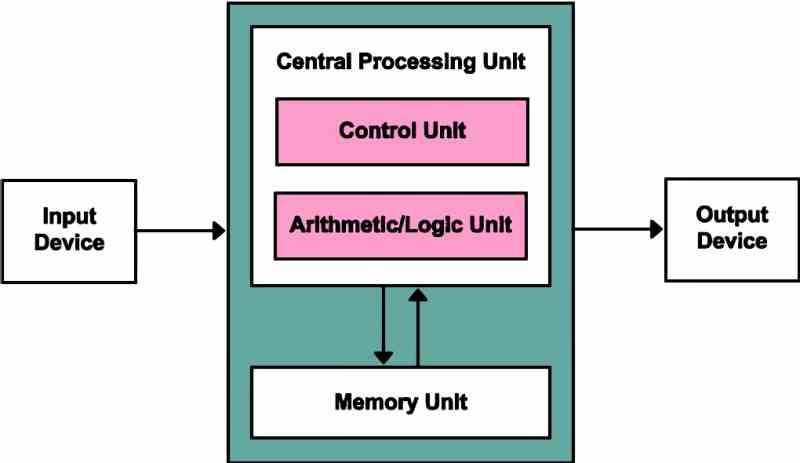
Die Von Neumann-Architektur basiert auf allen PC-Prozessoren, da alle mit einer Reihe gemeinsamer Komponenten organisiert sind:
- Steuereinheit: In Ladung der Erfassungs- und Decodierungsstufen des Befehlszyklus.
- Logisch-arithmetische Einheit oder ALU: In Verantwortung für die Ausführung der von den Programmen geforderten mathematischen und logischen Operationen.
- Erinnerung: Der Speicher, in dem das Programm gespeichert ist, den wir als RAM-Speicher kennen
- Eingabegerät: Von wo aus kommunizieren wir mit dem Computer.
- Ausgabegerät: Von wo aus der Computer mit uns kommuniziert.
Wie Sie sehen können, ist es die gemeinsame Architektur in allen Prozessoren und deshalb hat es kein Geheimnis mehr, aber es gibt eine andere Art von Architektur, die als Harvard-Architektur bekannt ist, in der die RAM Der Speicher ist in zwei verschiedene Vertiefungen unterteilt. In einer von ihnen speichern sie die Programmanweisungen und die Daten im anderen Speicher und haben separate Busse sowohl für die Speicheradressierung als auch für die Anweisungen.
Was sind die Grenzen der Von Neumann-Architektur?
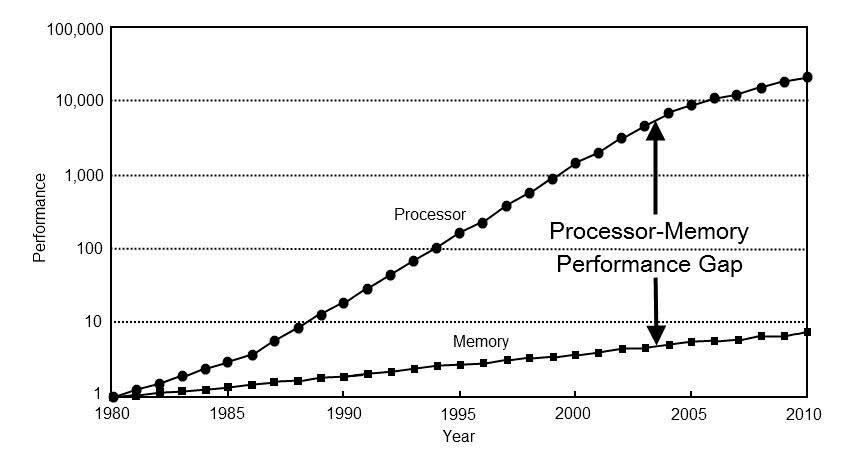
Der Hauptnachteil besteht darin, dass der RAM-Speicher, in dem sich die Anweisungen und die zu verarbeitenden Daten befinden, über denselben Datenbus und dieselbe gemeinsame Adressierung vereinheitlicht und gemeinsam genutzt werden. Die Anweisungen und Daten müssen also nacheinander aus dem Speicher erfasst werden. Dieser Engpass ist der sogenannte Von Neumann-Engpass. Aus diesem Grund haben die verschiedenen Mikroprozessoren den dem Prozessor am nächsten gelegenen Cache, der in zwei Typen unterteilt ist, einen für Daten und einen für Anweisungen.
In den letzten Jahren sind die Prozessorgeschwindigkeiten viel schneller gestiegen als der RAM-Speicher, wodurch sich die Zeit für die Datenübertragung aus dem Speicher erhöht. Was gezwungen hat, Lösungen zu entwickeln, um dieses Problem zu lindern, ist ein Produkt des Von Neumann-Engpasses.
In den Prozessoren, in denen normalerweise die Harvard-Architektur verwendet wird, sind sie in sich geschlossen und haben daher keinen Zugriff auf den gemeinsamen RAM des Systems, sondern führen ihren eigenen Speicher und ihr eigenes Programm isoliert vom Hauptspeicher aus CPU. Diese Prozessoren erhalten die Liste der Daten und Anweisungen in zwei verschiedenen Datenzweigen. Eine für den Befehlsspeicher und die andere für den Datenspeicher des Prozessors.
Warum wird es in CPU und GPU verwendet?

Der Hauptgrund ist die Tatsache, dass das Erhöhen der Anzahl von Bussen das Erhöhen des Umfangs des Prozessors selbst bedeutet, da für die Kommunikation mit dem externen Speicher die Schnittstelle außerhalb des Prozessors sein muss. Dies führt zu viel größeren und viel teureren Prozessoren. Der Hauptgrund für die Standardisierung der Von Neumann-Architektur sind die Kosten.
Der zweite Grund ist, dass die beiden Speichervertiefungen synchronisiert werden müssen, damit eine Anweisung nicht für fehlerhafte Daten gilt. Dies führt dazu, dass Koordinationssysteme zwischen beiden Speicherquellen erstellt werden müssen. Natürlich würde ein großer Teil der Engpässe durch die Trennung beider Busse beseitigt. Aber es würde auch den Von Neumann-Engpass nicht vollständig reduzieren.
Dies liegt an der Tatsache, dass der Von Neumann-Engpass, obwohl er eine Folge des Speicherns von Daten und Anweisungen im selben Speicher ist, auch in einer Harvard-Architektur auftreten kann, wenn er nicht schnell genug ist, um den Prozessor mit Strom zu versorgen. Aus diesem Grund wurden Harvard-Architekturen speziell auf Mikrocontroller und DSP reduziert. Während Von Neumann auf CPU und CPU üblich ist GPU
