Beim Kauf eines CPU oder eine GPU Wir finden technische Spezifikationen wie Taktrate, Anzahl der Gleitkommaoperationen, Speicherbandbreite usw. Eine der Möglichkeiten, die Leistung zu messen und einen Prozessor zu entwerfen, hängt jedoch mit der Latenz der Anweisungen zusammen. Wir erklären, was es ist und warum es so wichtig ist, schnellere CPUs zu bekommen.
Die Leistung eines Prozessors gegenüber einem anderen wird an der Zeit gemessen, die zum Lösen desselben Programms benötigt wird. Dies kann auf viele verschiedene Arten erreicht werden, und es gibt verschiedene Möglichkeiten, die Leistung zu steigern und dadurch die Zeit zu verkürzen, die für die Ausführung benötigt wird. Eine davon besteht darin, die Latenz der ausgeführten Anweisungen zu verringern. Aber woraus besteht es genau?

Was verstehen wir unter Anweisungslatenz?
Die Latenz ist die Zeit, die ein Prozessor benötigt, um einen Befehl auszuführen, und diese ist variabel, von wo aus sich die Daten befinden. Je weiter sie entfernt sind, desto mehr Zeit muss er zurücklegen, damit diese in die entsprechenden Register gestellt werden. Aus diesem Grund und weil der Speicher nicht mit der gleichen Geschwindigkeit wie die Prozessoren skaliert, mussten Mechanismen wie der Cache erstellt und sogar der Speichercontroller in den Prozessor integriert werden, um die Latenz der Anweisungen zu verringern.
Dies wird jedoch normalerweise beim Verkauf einer CPU und sogar einer GPU nicht berücksichtigt. Andere Leistungsmaßstäbe werden häufig verwendet, um zu sagen, dass eine Architektur einer anderen überlegen ist. Die Latenz der Anweisungen wird jedoch normalerweise nicht verwendet, wenn ein Prozessor hochgestuft wird, wenn dies eine weitere Möglichkeit ist, die Leistung zu verstehen.
Taktzyklen pro Befehl und Latenz

Das erste Maß für die Leistung sind Zyklen pro Befehl, da es Befehle gibt, die komplex genug sind, um in mehreren verschiedenen Befehlszyklen ausgeführt werden zu müssen. Beim Entwurf neuer Prozessoren nehmen Architekten häufig Änderungen an der Art und Weise vor, wie eine Anweisung in Bezug auf frühere Prozessoren mit derselben ISA gelöst wird, unabhängig davon, ob es sich um CPUs, GPUs oder andere Prozessortypen handelt.
Was nie geändert wird, ist die Form des Befehls, aber was getan wird, ist, die Anzahl der Taktzyklen zu verringern, die notwendig sind, um ihn zu verschlüsseln. Zum Beispiel können wir einen Befehl haben, der für die Berechnung des Durchschnitts zwischen zwei Zahlen zuständig ist, der in einem Prozessor mit derselben ISA 4 Taktzyklen benötigt und der sich gegenüber einer früheren Version desselben Befehls, der 20 Zyklen benötigt, um 5% verbessert.
Die Idee ist nichts anderes als die Zeit zu verkürzen, die für einen Teil der Anweisungen benötigt wird, um die Zeit zu verkürzen, die zum Ausführen eines Programms benötigt wird. Auf diese Weise wird mit kleinen Beschleunigungen in den Anweisungen erreicht, dass sich die Gesamtleistung erhöht.
Cache- und Anweisungslatenz

Der Cache-Speicher speichert eine Kopie des RAM Speicher, in dem die Befehle ausgeführt werden, die zu diesem Zeitpunkt ausgeführt werden, ermöglicht dies dem Prozessor, auf den Speicher zuzugreifen, ohne auf den RAM zugreifen zu müssen, und da der Cache näher an den Einheiten der CPU liegt, kann der Speicher den Befehl ausführen in kürzerer Zeit, da die Erfassung von Anweisungen weniger Zeit erfordert.
Die Tatsache, dass es sich um verschiedene Cache-Ebenen handelt, bedeutet nicht, dass alle Caches der ersten Ebene, der zweiten Ebene und sogar der dritten Ebene den gleichen Abstand und damit die gleiche Latenz haben, sondern dass sie von Architektur zu Architektur unterschiedlich sind. Zum Beispiel in der aktuellen Intel Core von Intel, die Latenz mit den Caches ist geringer als bei den Äquivalenten ihrer Konkurrenten. AMDist AMD Zen.
Um eine Architektur von einer Version zur anderen zu verbessern, ist eine der Änderungen, die normalerweise vorgenommen werden, die Verringerung der Latenz in Bezug auf den Cache. Insbesondere beim Portieren derselben Architektur von einem Knoten auf einen anderen, dank der Verringerung der Prozessorgröße und des Abstands zwischen den Einheiten und dem Cache.
Das Chiplet- und Latenz-Dilemma

Die Idee von Chiplets ist nichts anderes als die Verwendung mehrerer Chips anstelle von nur einem für dieselbe Funktion. Dies erhöht daher die Kommunikationsentfernung zwischen den verschiedenen Teilen und damit die Latenz. Dies führt zu einem Leistungsverlust im Vergleich zur monolithischen Version des Prozessors.
Im Fall des AMD Ryzen, dem bekanntesten Fall, besteht eine Möglichkeit, den Unterschied zwischen den auf Chiplets basierenden Versionen und den monolithischen Prozessoren zu verringern, darin, den Cache der letzten Ebene in Sekunden zu schneiden. Der Grund? Wenn sie die gleiche Menge an Cache hätten, hätten die Versionen über Chiplet nur aufgrund der Entfernung vom Speichercontroller eine geringere Latenz in den Anweisungen und damit eine höhere Leistung.
Die Befehlslatenz ist der Schlüssel zu 3DIC

Die in drei Dimensionen integrierten Chips sind ein weiterer wichtiger Punkt, insbesondere diejenigen, die Speicher auf einem Prozessor stapeln. Der Grund dafür ist, dass sie den Speicher so nahe am Prozessor platzieren, dass dies allein die Leistung erhöht. Der Nachteil dabei ist die thermische Drosselung zwischen Speicher und Prozessor, wodurch die Taktrate sinkt. Bei einigen Designs kann es vorkommen, dass die getrennte Anordnung von Prozessor und Speicher höhere Taktraten ermöglicht als bei einem 3DIC-Design.
Wenn der Speicher nahe genug am Prozessor liegt, kann dies zu einem merkwürdigen Effekt führen, bei dem der Zugriff auf die Daten im eingebetteten Speicher weniger Zeit in Anspruch nimmt als das Durchlaufen der verschiedenen Cache-Ebenen der Architektur nacheinander. Dies ändert die Art und Weise, wie ein Prozessor entworfen wird, vollständig, da der Cache-Speicher eine Möglichkeit darstellt, die Latenz zu verringern, wenn die zu verarbeitenden Daten zu weit voneinander entfernt sind.
Entfernung und Verbrauch hängen zusammen
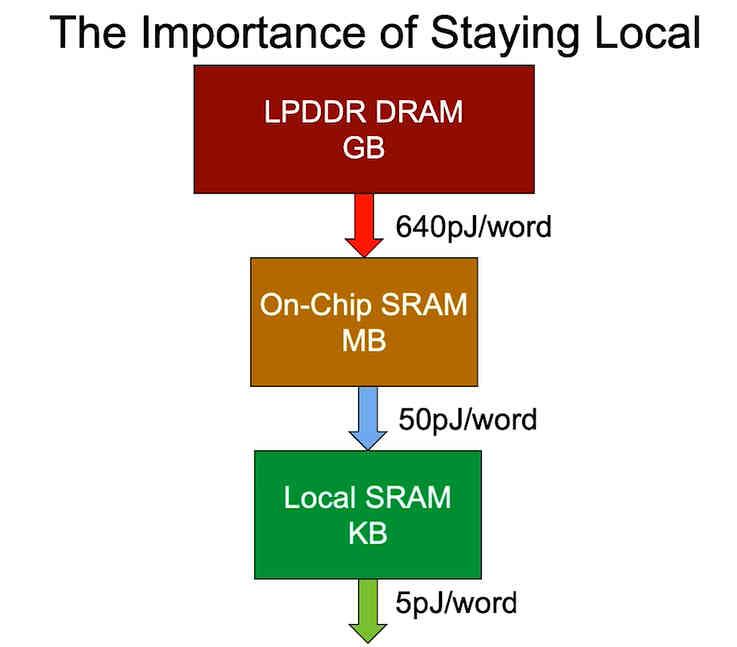
Der letzte Punkt ist der Energieverbrauch, der davon abhängt, wo sich die Daten befinden. Aus diesem Grund wird beim Entwurf einer im Hinblick auf den Prozessorverbrauch optimierten Version versucht, die Entfernung zu verringern, in der sich die Daten befinden, da der Energieverbrauch eines Prozessors mit der Entfernung zunimmt, in der die Daten gefunden werden sollen, und nicht Nur Latenz, leider können wir nicht die riesigen Datenmengen anpassen, die wir benötigen, um ein Programm im Raum eines Chips auszuführen.
In einer Welt, in der der Energieverbrauch aufgrund des Klimawandels zu einem der wichtigsten Punkte geworden ist und Portabilität und niedriger Verbrauch ein Verkaufsargument und daher für viele Produkte von Wert sind, ist die Tatsache, nach Wegen zu suchen, um den Speicher näher an den Prozessor und damit näher zu bringen Verringern Sie die Latenz der Anweisungen, was äußerst wichtig wird, um die Leistung pro Watt zu erhöhen.
