SWAR-konceptet vil virke underligt for mange, men hvad sker der, hvis vi fortæller dig, at SIMD-enhederne til dine CPU'er, GPU'er i dine systemer for det meste er af SWAR-typen? Disse typer enheder adskiller sig fra konventionelle SIMD-enheder og har deres oprindelse i multimedieudvidelserne i slutningen af 90'erne. Hvad er de, og hvad bruger de i dag?
En processors ydeevne kan måles på to måder, på den ene side, hvor hurtigt den udfører instruktionerne i serie, og at de derfor ikke kan paralleliseres, da de kun påvirker enhedsdata. På den anden side dem, der arbejder med flere data og kan paralleliseres. Den traditionelle måde at gøre det på CPU'er og GPU'er på? SIMD-enhederne, hvoraf der er en undertype, der er meget brugt i CPU'er og GPU'er, SWAR-enhederne.

ALU'er og deres kompleksitet
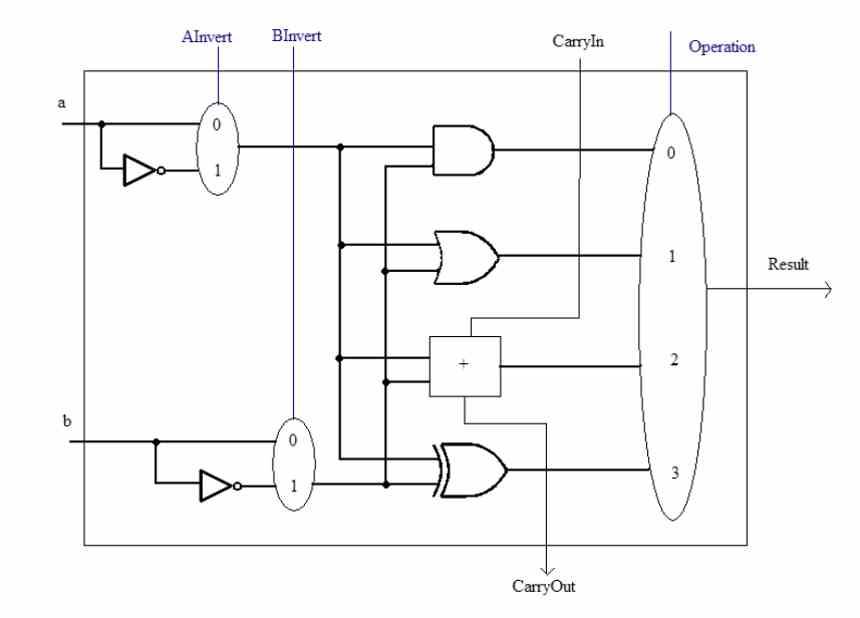
Før vi taler om SWAR-konceptet, skal vi huske, at ALU'er er enhederne i a CPU der er ansvarlige for at udføre aritmetiske og logiske beregninger med de forskellige tal. Disse kan vokse i kompleksitet på to måder, en fra kompleksiteten af den instruktion, de skal udføre. Det interne kredsløb i en ALU, der f.eks. Kan udføre beregningen af en kvadratrode, er ikke den samme som en simpel sum.
Den anden er præcisionen, som de arbejder med, det vil sige antallet af bits, som de manipulerer samtidigt hver gang. En ALU kan altid håndtere data, der er lig med eller mindre end antallet af bits, den er designet til. For eksempel kan vi ikke få et 32-bit tal beregnet af en 16-bit ALU, men vi kan gøre det modsatte.
Men hvad sker der, når vi har flere data med lavere præcision? Normalt vil de køre med samme hastighed som fuld præcision, men der er en måde at fremskynde dem på, og det er det overregistrerede SIMD. Hvilket også er en måde at gemme transistorer i en processor.
Hvad er SWAR-konceptet?
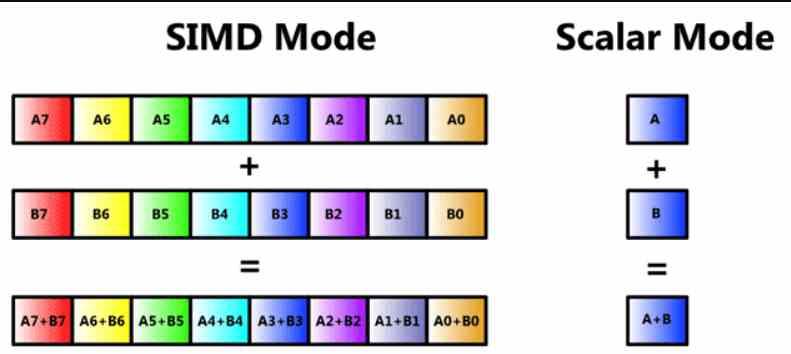
Nu vil mange af læserne vide, at det er en SIMD-enhed, men vi vil gennemgå den, så ingen mister tråden i denne artikel fra starten. En SIMD-enhed er en type ALU, hvor flere data manipuleres gennem en enkelt instruktion på samme tid, og derfor er der flere ALU'er, der deler afvandingsdelen af, hvad selve instruktionen er, og dens afkodning, men hvor i hver en anden stykke information behandles.
SIMD-enheder består normalt af flere ALU'er, men der er tilfælde, hvor ALU'erne er opdelt i enklere, såvel som akkumuleringsregistret, hvor de midlertidigt gemmer deres data for at beregne dem. Dette kaldes SIMD i et register eller ved dets akronym på engelsk SWAR, hvilket betyder SIMD inden for et register eller SIMD i et register.
Denne type SIMD-enhed er meget brugt og giver en n-bit ALU-præcision mulighed for at udføre den samme instruktion, men bruger data med mindre præcision. Normalt med en halv eller en kvart præcision. For eksempel kan vi få en 64-bit ALU til at fungere som to 32-bit ALU'er ved at udføre instruktionen parallelt eller fire 16-bit.
Går du dybere ned i SWAR-konceptet?
Dette koncept er allerede flere årtier gammelt, men første gang de dukkede op på pc var i slutningen af 90'erne med udseendet af SIMD-enheder i de forskellige typer processorer, der eksisterede. Stedets veteraner vil huske begreber som MMX, AMD 3D Now!, SSE og lignende var SIMD-enheder bygget under SWAR-konceptet.
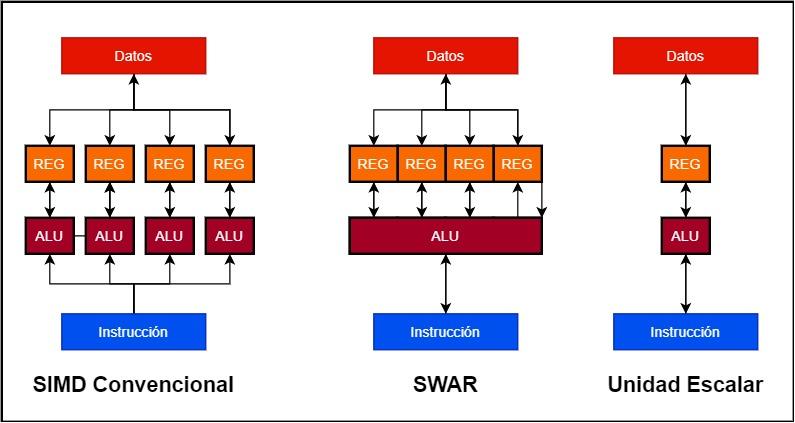
Antag, at vi vil bygge en 128 bit SIMD-enhed
- I konventionelle SIMD-enheder har vi flere ALU'er, der arbejder parallelt, og hver af dem har sit eget dataregister eller akkumulator. Således kan en 128-bit SIMD-enhed bestå af 4 32-bit ALU'er og 4 32-bit-registre.
- I stedet er en SWAR-enhed en enkelt ALU, der kan arbejde i meget høj præcision såvel som dens akkumulatorregister. Dette giver os mulighed for at opbygge SIMD-enheden ved hjælp af en enkelt 128-bit ALU med SWAR-understøttelse.
Fordelen ved, at implementeringen af en SWAR-enhed har en skalær, er let at forstå, hvis en ALU ikke indeholder SWAR-mekanismen, der gør det muligt at fungere som en SIMD-enhed med mindre præcisionsdata, vil den udføre dem på samme tid fart. data med den højeste præcision. Hvad betyder det? En 32-bit enhed uden SWAR-understøttelse, hvis den skal betjene den samme instruktion på 16-bit data, vil gøre det med samme hastighed som en 32-bit en. På den anden side, hvis ALU understøtter SWAR, vil den være i stand til at udføre to 16-bit instruktioner i samme cyklus, i tilfælde af at begge kommer successivt.
SWAR som en patch til AI

Algoritmer for kunstig intelligens har en specificitet, de har tendens til at arbejde med data med meget lav præcision, og i dag fungerer de fleste ALU'er med 32-bit præcision. Dette betyder at tilføje præcision 16-, 8- og endda 4-bit ALU'er til en processor for at fremskynde disse algoritmer. Hvilket er at komplicere processoren, men ingeniørerne faldt ikke ind i den fejl og begyndte at trække SIMD over registeret på en bestemt måde, især på GPU'er.
Er det muligt at kombinere en konventionel ALU SIMD med et SWAR-design? Nå ja, og dette er hvad AMD for eksempel gør i sine GPU'er, hvor hver af de 32-bit ALU'er, der udgør SIMD-enhederne i dens RDNA GPU'er, understøtter SIMD over register og derfor kan opdeles i to 16-bits, 4 på 8 bit eller 8 på 4 bit.
I tilfælde af NVIDIA, de har lagt byrden ved at fremskynde algoritmerne for AI til Tensor Cores, disse er systoliske arrays sammensat af 16-bit ALU'er med flydende punkt, der er forbundet med hinanden i en tre-akset matrix, deraf enhedsnavnet. Tensor. De er ikke SIMD-enheder, men hver af deres ALU'er understøtter SIMD over register ved at være i stand til at udføre dobbelt så mange operationer med 8-bit præcision og fire gange med 4-bit præcision. Under alle omstændigheder er Tensorenheder vigtige, fordi de er designet til at fremskynde matrix-til-matrix-operationer med en meget højere hastighed end med en SIMD-enhed.
