
Superopløsningsalgoritmer udført fra Gaming GPU'er er blevet spydspidsen for forskellige spil GPU producenter. Med indtastningen af Intel til dette marked har de ikke ønsket at blive efterladt og har udviklet deres egen pendant til NVIDIA DLSS og AMD FSR under navnet Intel Xe Super Sampling. Hvordan fungerer Intel XeSS, og hvordan adskiller den sig fra sine konkurrenter?
Sammen med den endelige præsentation af det, der tidligere var kendt som Xe-HPG, og som er blevet omdøbt til ARC Alchemist. Intel fortalte os ikke kun om den nye generation af grafikarkitekturer, men om engagementet i kunstig intelligens for fremtiden, både i CPU og GPU. I deres specifikke tilfælde har de udviklet en algoritme kaldet Intel XeSS, som kommer til at konkurrere mod AMDs FSR og NVIDIAs DLSS. Hvor de falder sammen i mål, men ikke måden at arbejde mellem de tre algoritmer på.
Hvorfor har vi brug for algoritmer med superopløsning?

Ved behandling af grafik tildeles hvert toppunkt, fragment eller pixel mindst én eksekveringstråd på GPU'en, og det skal tages i betragtning, at antallet af pixels er meget større end antallet af hjørner i scenen. Det betyder, at når opløsningen øges, sker det, at vi ender med at øge mængden af instruktioner, der skal udføres i GPU'en, såvel som dens data, og derfor øges båndbredden også.
Problemet er, at dette indebærer at have en meget større GPU i størrelse, ikke kun på grund af stigningen i de forskellige enheder, men også på grund af det faktum, at det ved at kræve en højere båndbredde også kræver mere komplekse hukommelsescontrollere. Lad os ikke glemme, at disse er placeret på den ydre omkreds af enhver processor og derfor har at gøre med dens størrelse. Og især kan vi ikke glemme det høje forbrug af de minder, der bruges til gaming -grafikkort.
Superopløsningsalgoritmer som AMD FSR, Intel Xess og NVIDIA DLSS søger at løse dette problem. De stoler på at øge hardware med en lille procentdel, mindre end 10%, for at opnå ydeevne, der ellers traditionelt ville kræve en fordobling af størrelsen på en GPU. Til alt dette kan vi ikke glemme Ray Tracing, hvis algoritme selv gør brug af accelerationsstrukturer som BVH fungerer på pixelniveau, og derfor er superopløsningsalgoritmer blevet vedtaget som en væsentlig del af grafik i realtid.
Hvad er Intel XeSS?

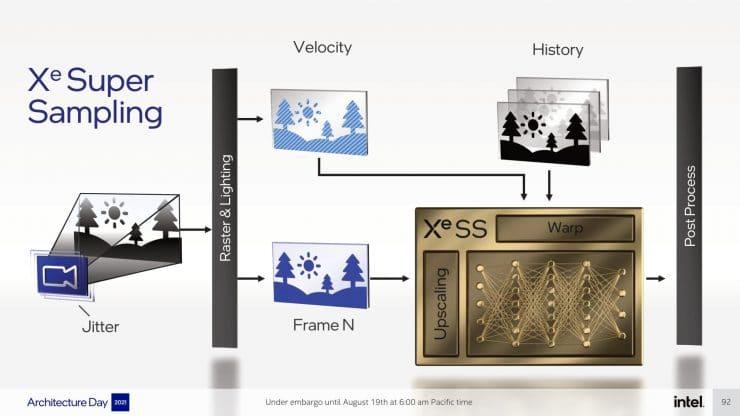
Intel vil tilbyde to versioner af Intel XeSS og derfor to forskellige algoritmer. I begge tilfælde taler vi om en algoritme, der er baseret på Deep Learning og computer vision, og derfor bruges et inferens neuralt netværk, der forudsiger billedet ved en højere opløsning, med flere pixels, fra en lavere opløsning. og derfor færre pixels.
Den første variant gør brug af SIMD over register eller SWAR, som nogle GPU'er har, denne mekanisme består i, at 32-bit ALU kan opdeles i to 16-bit ALU'er, der udfører den samme instruktion eller 4 af 8 bits. Nå, DP4A-formatet består af at gruppere 4 8-bit operander i et 32-bit register. Så en af XeSS -varianterne vil kunne køre på Intels integrerede GPU'er samt enhver GPU, der understøtter dette format, da Intel vil gøre det til open source.
Den anden variant af Intel XeSS er på den anden side mere kompleks, da den fungerer ved hjælp af Tensor -enhederne i Intel Arc kaldet XMX, men den fungerer ikke i NVIDIA GPU'er med Tensor Cores. Intels forklaring er ingen ringere end, at NVIDIA holder lås og nøgle den måde, dens GPUs Tensor Cores fungerer, brugen af XMX -enheder og evnen til at udføre ekstremt hurtige matrixberegninger, der kræves af konvolutionsnetværk. Da det ikke fungerer på AMD GPU'er og AMD's GPU'er i øjeblikket mangler sådanne enheder, ville den anden variant udelukkende være til Intel GPU'er.
Hvordan adskiller Intel XeSS sig fra løsninger fra AMD og NVIDIA?
Faktisk ville det være mellem de to verdener, da på trods af at det er en løsning baseret på Deep Learning ligesom NVIDIAs, fra Intel har de bekræftet, at de er vil offentliggøre koden for dens implementering som AMD har gjort med sin FidelityFX Super Resolution. Så udviklere kan lettere anvende det i deres spil og applikationer. Det er en strategi, der i tilfælde af AMD -algoritmen har tilladt dens implementering ud over det forventede, såsom emulatorer af gamle konsoller, Linux applikationer og endda spil, der ikke ville have modtaget en patch af denne type.
Ligesom NVIDIA DLSS tager det også højde for temporalitetsdataene, som er hentet fra oplysningerne fra de tidligere rammer, dette er noget, som AMD FSR ikke gør, da den røde løsning kun tager informationen fra den aktuelle ramme. Lad os heller ikke glemme, at AMD -algoritmen ikke er baseret på kunstig intelligens og derfor ikke kræver træning, mens NVIDIA gør det. Intel har påstået, at XeSS heller ikke gør det, og det er her tingene bliver interessante.
Hvorfor har XeSS ikke brug for træning?

En af de ting, der adskiller XeSS fra NVIDIA DLSS, er, at den tidligere kræver ingen uddannelse . I træningsprocessen har vi to elementer, der arbejder på samme tid, den første er ansvarlig for forudsigelse og den anden for at føre tilsyn. Når en forudsigelse fra det konvolutionelle neurale netværk er forkert, returnerer den overvågende hardware det negative svar, og det neurale netværk forfines mere og mere, indtil det lærer at lave de korrekte forudsigelser.
I et videospil, hvor ikke en enkelt ramme gentages, er det meget vanskeligere at gøre end i en film, hvor der altid er de samme rammer. Det er derfor, hvad der normalt gøres, er at træne det neurale netværk med overvågning. Som består i at udføre spillet i høj opløsning i et system, nedskalere billedet i en proces, der tilføjer støj og fra disse data oprette et neuralt netværk i systemet, der bliver nødt til at foretage slutningen, så det kan generere billedet til højere løsning.
Intel siger, at med XeSS er ingen uddannelse nødvendig og derfor ingen overvågning fra et eksternt system er nødvendig. Virkeligheden af denne erklæring er ingen ringere end uddannelsesprocessen udføres inden for GPU'ens egen hardware i stedet for at blive udført på fjernhardware. Til dette, hvad GPU gør, er at køre spillet i to samtidige forekomster på samme tid, den ene fungerer som en supervisor og i den anden er det neurale netværk indstillet. Dette giver dem, der implementerer Intel Xess i deres spil og applikationer, mulighed for at finjustere algoritmen og ikke være afhængige af eksterne servere.
De hemmelige ingredienser, som Intel har integreret i sine GPU'er til XeSS
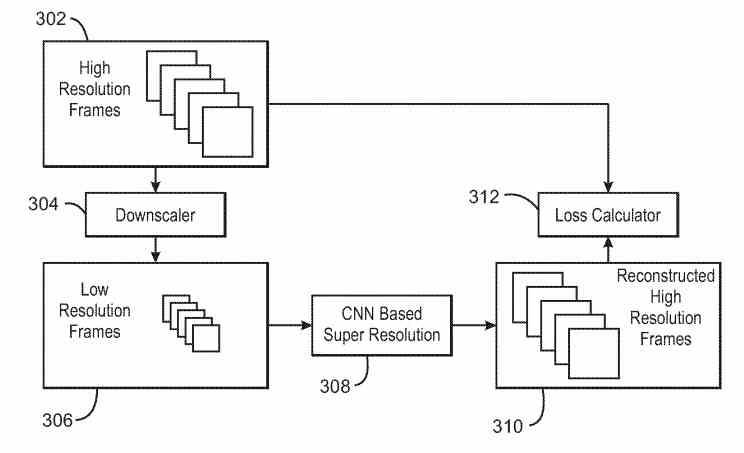
For at fremskynde uddannelsen vil Intel omfatte en række yderligere enheder i GPU'en , som f.eks Nedsampler , enheden for at opnå det samme billede ved en lavere opløsning og den, der beregner tabet af signalkvalitet. For ikke at glemme Rygpropagator , som er nøglen under selve træningsprocessen fra selve GPU'en. I øjeblikket ved vi ikke, hvor disse enheder er til træning af det konvolutive neurale netværk, men vi antager, at de er en supportenhed bortset fra det, der er gengivelsesmotoren, men inden for selve GPU'en.
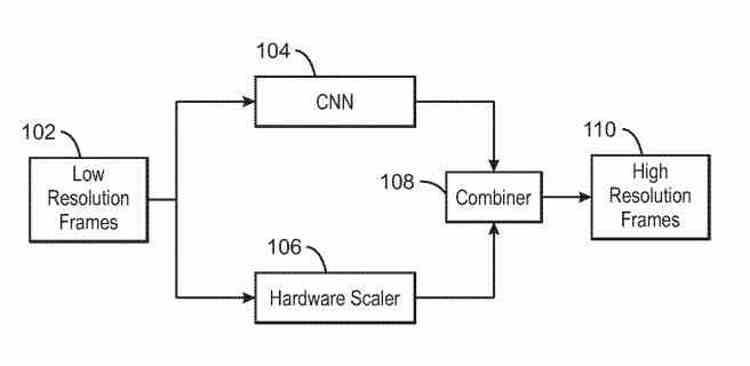
Superopløsningsalgoritmer bruger ofte supersamplingsalgoritmer i processen for at få billedet i højere opløsning. Nogle gør brug af bikubisk interpolation, mens andre som FSR bruger en Lanczos -variant, selvom de alle kører på Shader -enhederne i GPU'en og derfor ender der. Intel ville have inkluderet skaleringsenheder , som ville være i stand til at udføre en eller flere supersamplingsalgoritmer automatisk og ville befri Xe Core SIMD -enhederne fra denne opgave, så de kunne bruges andre steder, hvor de også er nødvendige.
Så afslutningsvis tilføjer Intel XeSS en række ekstra hardware det indtil nu var uden fortilfælde i GPU'er. Ikke kun for at fremskynde disse algoritmer, men også for at øge kompatibiliteten og lette deres implementering i de forskellige spil på markedet. Det være sig de seneste nyheder eller spil med et par år bag sig. Så det kan siges, at Intel med XeSS har taget godt hensyn til sine rivalers mangler og begrænsninger.