
VLIW znamená Very Long Instruction Word, což znamená velmi dlouhou slovní instrukci. Ve světě procesorové architektury se používá k definování typu procesor nebo procesor, který dosahuje paralelismu instrukcí nebo ILP, ale s odlišnou metodikou, než jakou používají superskalární procesory, která se běžně používá v CPU.
CPU typu VLIW mají ve srovnání s jinými procesory řadu výhod a nevýhod a byly použity nejen v CPU, ale také jako shaderové jednotky pro GPU a také v DSP.
Dnes se zdá, že návrhy VLIW z hardwaru PC zmizely, nicméně i přes jejich nepoužívání zůstávají platnou možností při navrhování nových procesorů pro různé oblasti trhu s hardwarem.
Jak funguje procesor VLIW?
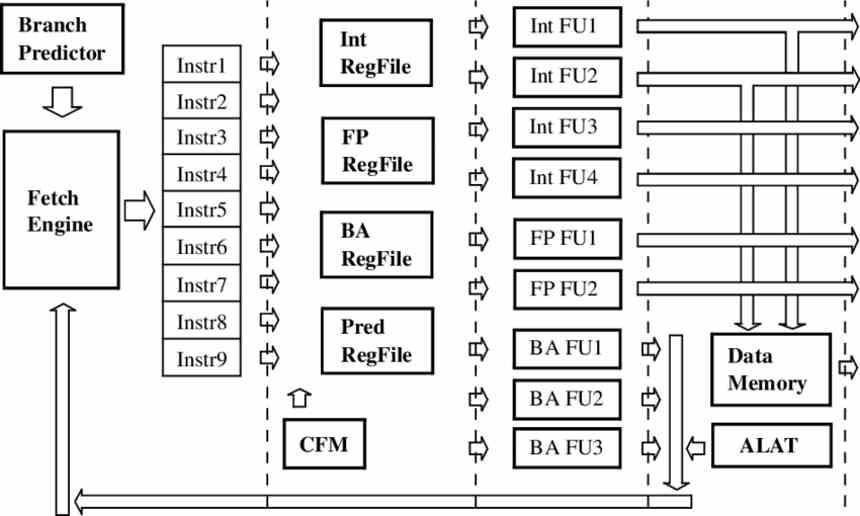
V superskalárním procesoru nebo konvenčním ILP jsou instrukce zachyceny a zpracovány jednotlivě během instruktážního cyklu každé z nich. Ať už mluvíme o provedení v pořadí nebo mimo pořadí. V případě procesoru VLIW se provede seskupení několika instrukcí do jedné a jejich odeslání společně do různých jednotek, které jsou v procesoru k dispozici.
Dosáhnout toho, procesory VLIW silně závisí na kompilátoru při generování binárního kódu , který seskupí různé instrukce do jedné instrukce, vždy s přihlédnutím k úrovni obsazení každé z prováděcích jednotek v každém okamžiku operace. provedení, které bude záviset na počtu hodinových cyklů požadovaných každou z instrukcí.
Vzhledem k tomu, že instrukce mohou mít různé stupně trvání, pokud jde o hodinové cykly, jedná se o problém s výkonem, protože během několika hodinových cyklů budeme mít prováděcí jednotky, které nebudou dělat nic a budou provádět instrukci NOP, což znamená, že během těchto hodin cyklus uvedená jednotka neprovádí žádnou operaci. Díky tomu jsou procesory VLIW vysoce závislé na kompilátoru pro maximální efektivitu.
Výhody a nevýhody konstrukce VLIW

Hlavní výhody, které přináší, jsou následující:
- Hardware odpovědný za dekódování instrukcí je mnohem jednodušší než procesor ILP nebo TLP, což umožňuje ponechat více volného místa na čipu pro prováděcí jednotky, a proto je schopen provádět více instrukcí současně.
- Mít více místa vám také umožňuje umístit větší počet registrů, což je ideální pro usnadnění spekulativního provádění typického pro procesory mimo pořadí bez nutnosti vyrovnávací paměti.
Pokud jde o jeho nevýhody, první z nich spočívá ve skutečnosti, že je vyžadován mnohem složitější překladač, druhý je ten, který jsme zmínili dříve, a který je založen na skutečnosti, že dochází k většímu plýtvání různými prováděcími jednotkami, protože většina z nich bude trávit dobrý čas neobsazený.
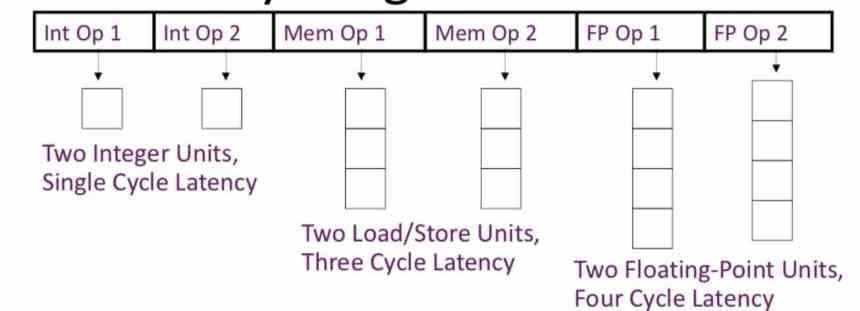
Abychom tomu lépe porozuměli, představte si, že jste seskupili pokyny VLIW 3, které vyžadují provedení prvních 4 cyklů, druhého 7 cyklů a třetího 10 cyklů. Prováděcí jednotka odpovědná za provádění první instrukce bude 6 hodinových cyklů, aniž by něco dělala, druhá 3 a to vše, protože třetí bude potřebovat 10 cyklů, aby fungovala.
Na druhou stranu musíme přidat skutečnost, že ačkoliv se na úrovni instrukcí binární soubory nemění, při vývoji nového CPU je možné, že instrukce již existuje, zvyšuje nebo snižuje počet cyklů. Díky tomu je odlišný kompilátor nezbytný i pro nové iterace nového procesoru, což ztěžuje spuštění pokročilejších verzí procesoru a v mnoha případech vyžaduje vytvoření kompilátoru binární na binární, který změní pořadí pokynů pro nový procesor.
Generování pokynů kompilátorem

Abychom tomu lépe porozuměli, připravili jsme několik seznamů, první je provedení v superskalárním procesoru nebo známé jako ILP, druhým je procesor typu VLIW.
Počínaje procesorem typu ILP by byl seznam jeho pokynů následující:
- Vložte A1
- Načíst B1
- Vložte A2
- Poplatek B2
- Vynásobte hodnoty A1 a B1
- Přidejte hodnoty A2 a B2
- Přidejte A1 a A2
- Náklad A3
- Zatížení B3
- Vynásobte A3 B3
- Přidejte B1 a B2.
Na druhou stranu procesor VLIW seskupí několik pokynů do jedné:
- A2 a B2 jsou účtovány současně
- Načtěte A2 a B2, vynásobte A1 a B1, přidejte A2 a B2.
- Načtěte A3, B3, vynásobte A3 B3 a přidejte B1 a B2.
Skutečnost, že se nám podařilo seskupit 11 instrukcí do pouze 3 velmi velkých instrukcí, znamená, že doba, kterou bude každá z instrukcí VLIW vyžadovat, bude maximálně čas potřebný pro nejsložitější instrukci ve skupině instrukcí.
Přístup do paměti tohoto typu procesorů

Jak jsme již diskutovali dříve, procesory VLIW závisí na kompilátoru a mnohokrát přidávají příkazy NOP do kódu během kompilace. Důvodem je to, že vytvoření VLIW CPU s instrukcemi proměnné velikosti je extrémně složité, takže se to dělá tak, že se vytvoří pevná velikost bitů, při které CPU čte instrukce a načte to množství dat z paměti v každém cyklu . a pokyny.
To znamená, že procesory VLIW vyžadují mnohem širší datové sběrnice než konvenční procesory, protože seskupují velké množství bitů pokaždé, když zachytí nové instrukce, které mají být provedeny. To je jeho skvělá Achillova pata, protože v procesorech ILP, běžných v procesorech PC, se používají užší šířky dat, a proto se používají jednodušší řadiče paměti.
Normální věcí v procesorech VLIW je, že zachycují následující instrukce, které mají být provedeny, zatímco je prováděna aktuální instrukce VLIW. Vzhledem k tomu, že seskupením několika instrukcí do jedné se sníží doba zachycení každé z nich zvlášť.
