
VLIW stands for Very Long Instruction Word, which translates to very long word instruction. In the world of processor architecture, it is used to define a type of CPU or processor that achieves instruction parallelism or ILP, but with a different methodology from that used in superscalar processors, which is the one commonly used in CPUs.
VLIW-type CPUs have a number of advantages and disadvantages compared to other processors and have not only been used in CPUs, but also as shader units for GPUs and also in DSPs.
Today, VLIW designs seem to have disappeared from PC hardware, however they remain a valid option in the design of new processors for different areas of the hardware market despite their disuse.
How does a VLIW processor work?
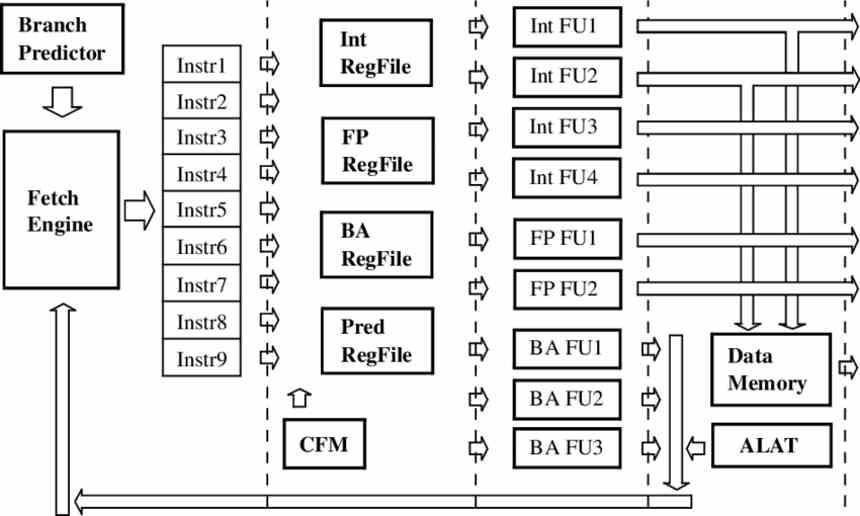
In a superscalar processor or conventional ILP, the instructions are captured and processed individually during the instruction cycle of each one. Whether we are talking about an in-order or an out-of-order execution. In the case of a VLIW processor, what is done is to group several instructions into one and send them together to the different units that are available in the processor.
To achieve this, the VLIW processors depend heavily on the compiler when generating the binary code , which will group the different instructions into a single instruction, always taking into account the level of occupation of each of the execution units at each moment of operation. execution, which will depend on the number of clock cycles required by each of the instructions.
Since the instructions can have different degrees of duration in terms of clock cycles, this is a performance problem, since during several clock cycles we will have execution units that will do nothing and that will be executing a NOP instruction, which means that during that clock cycle said unit does not perform any operation. This makes VLIW processors highly dependent on the compiler for maximum efficiency.
Advantages and disadvantages of a VLIW design

Mainly the advantages it brings are the following:
- The hardware in charge of decoding the instructions is much simpler than an ILP or TLP CPU, this allows leaving more free space on the chip for execution units and therefore being able to execute more instructions at the same time.
- Having more space also allows you to place a larger number of registers, which is ideal for facilitating speculative execution typical of out-of-order processors without the need for a sort buffer.
Regarding its disadvantages, the first of them is in the fact that a much more complex compiler is required, the second being the one that we have mentioned before and that is based on the fact that there is a greater waste of the different execution units, since that most of them are going to spend a good time unoccupied.
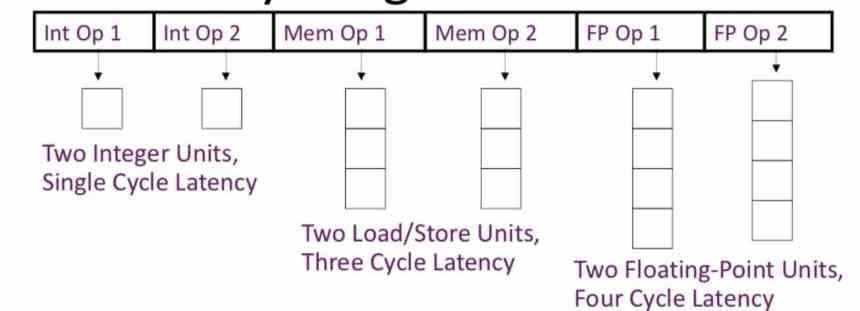
To understand it better, imagine that you have grouped in a VLIW 3 instructions that need the first 4 cycles to be executed, the second 7 cycles and the third 10 cycles. The execution unit in charge of carrying out the first instruction will be 6 clock cycles without doing anything, the second 3 and all this because the third will need 10 cycles to function.
On the other hand, we have to add the fact that although at the instruction level the binaries do not change, when developing a new CPU it is possible that an instruction already exists increases or decreases the number of cycles. This makes a different compiler necessary even for new iterations of a new processor, which makes it difficult to launch more advanced versions of a processor and requires in many cases the creation of a binary to binary compiler, which reorders the instructions for the new CPU.
Generation of instructions by the compiler

So that you can understand it better, we have prepared a couple of lists, the first is the execution in a superscalar processor or known as ILP, the second is a VLIW type CPU.
Starting with an ILP-type processor, a list of its instructions would be the following:
- Load A1
- Load B1
- Load A2
- Charge B2
- Multiply the values of A1 and B1
- Add the values of A2 and B2
- Add A1 and A2
- Cargo A3
- B3 load
- Multiply A3 by B3
- Add B1 and B2.
On the other hand, a VLIW processor will group several of the instructions into one:
- The A2 and B2 are charged simultaneously
- Load A2 and B2, multiply A1 and B1, add A2 and B2.
- Load A3, B3, multiply A3 by B3 and add B1 and B2.
The fact that we have managed to group the 11 instructions into only 3 very large instructions means that the amount of time that each of the VLIW instructions will require will at most be the time it takes for the most complex instruction in the group of instructions.
Memory access of this type of processors

As we discussed earlier, VLIW processors depend on the compiler and many times they add NOP statements to the code during compilation. The reason for doing this is because creating a VLIW CPU with instructions of variable size is extremely complex, so it is done is to create a fixed size of bits at which the CPU reads the instructions and fetch that amount of data from memory in each cycle. and instructions.
This means that VLIW processors require much wider data buses than conventional CPUs due to the fact that they group a large number of bits each time they capture new instructions to be executed. This being its great Achilles heel, since in ILP processors, common in PC CPUs, narrower data widths and therefore simpler memory controllers are used.
The normal thing in VLIW processors is that they are capturing the following instructions to be executed while the current VLIW instruction is being executed. Since by grouping several instructions into one, the capture time of each one of them separately is reduced.