Dagens samhälle behöver ett stort informationsutbyte för att utveckla de flesta aktiviteter eller jobb. Till exempel, företag, särskilt multinationella företag, distribuerar sina projekt mellan de många huvudkontor de har runt om i världen; Detta innebär att det måste finnas kommunikation och informationsutbyte mellan de olika platserna för att deras projekt ska kunna utvecklas korrekt. Ett annat exempel är universitet som behöver ett system för att utbyta information med studenter, förse dem med anteckningar, tentor etc.
Det var därför som den första P1996P-applikationen framkom från händerna på Adam Hinkley, Hotline Connect, som var tänkt att vara ett verktyg för universitet och företag för distribution av filer. Denna applikation använde en decentraliserad struktur och det tog inte lång tid att bli föråldrad (eftersom den berodde på en enda server); och eftersom det var designat för Mac OS, det gav inte mycket intresse från användarna.

Det är med Napster, 1999, då användningen av P2P-nätverk väckte nyfikenhet bland användarna. Detta musikutbytessystem använde en hybrid P2P-nätverksmodell, förutom kommunikation mellan kamrater inkluderade den en central server för att organisera dessa par. Deras största problem var att servern introducerade brytpunkter och en stor risk för flaskhalsar.
Det är därför nya topologier som decentraliserade växer fram, vars huvudegenskap är att den inte behöver en central server för att organisera nätverket; ett exempel på denna topologi är Gnutella. En annan typ är strukturerade P2P-nätverk, som fokuserar på att organisera innehåll snarare än att organisera användare; som ett exempel markerar vi JXTA. Vi har också nätverken med Distribuerade Hashes Table (DHT), som Chord.
Därefter kommer vi att utveckla de typer av P2P-nätverk som nämns ovan.
Första P2P-systemen: en hybridstrategi
De första P2P-systemen, som Napster eller SETI @ home, var de första som flyttade de tyngsta uppgifterna från servrar till användarnas datorer. Med hjälp av Internet, som gör det möjligt att kombinera alla resurser som användarna tillhandahåller, lyckades de få dessa system att nå en större lagringskapacitet och större datorkraft än servrar. Men problemet var att utan en infrastruktur för att fungera som en mellanhand mellan peer-enheterna skulle systemet bli kaos, eftersom varje peer skulle hamna oberoende.
Lösningen på problemet med oordning är att införa en central server, som kommer att ha ansvaret för att samordna paren (samordningen mellan par kan variera mycket från ett system till ett annat). Dessa typer av system kallas hybridsystem, eftersom de kombinerar klientservermodellen med modellen för P2P-nätverk. Många tycker att detta tillvägagångssätt inte ska beskrivas som ett riktigt P2P-system, eftersom det introducerar en centraliserad komponent (server), men trots detta har detta tillvägagångssätt varit och fortsätter att vara mycket framgångsrikt.
I denna typ av system, när en enhet ansluter till nätverket (med hjälp av en P2P-applikation), registreras den på servern, så att servern alltid har kontrollerat antalet par som är registrerade på den servern, så att de kan erbjuda tjänster till andra kamrater. Normalt är peer-to-peer-kommunikation punkt-till-punkt, eftersom kamraterna inte bildar något större nätverk.
Huvudproblemet med denna design är att den introducerar en systembrytpunkt och stor sannolikhet för att en så kallad "flaskhals" inträffar (vid dataöverföring, när bearbetningskapaciteten för en enhet är större än den kapacitet som enheten är ansluten till ). Om nätverket växer kommer serverbelastningen också att växa och om systemet inte kan skala nätverket kommer nätverket att kollapsa. Och om servern misslyckas skulle nätverket inte kunna omorganisera sig själv.
Men trots allt finns det fortfarande många system som använder den här modellen. Detta tillvägagångssätt är användbart för system som inte tål inkonsekvenser och inte kräver stora mängder resurser för samordningsuppgifter. Så här fungerar Napster så här. Napster uppstod i slutet av 1999, av Shawn Fanning och Sean Parke, med tanken att dela musikfiler mellan användare.

Såsom Napster fungerar är att användare måste ansluta till en central server, som ansvarar för att hålla en lista över anslutna användare och de filer som är tillgängliga för dessa användare. När en användare vill få en fil söker de på servern och servern ger dem en lista över alla par som har filen de letar efter. Den intresserade parten letar således efter användaren som bäst kan tillhandahålla det han behöver (till exempel välja de med bästa överföringshastighet) och får sin fil direkt från honom utan mellanhänder. Napster blev snart ett mycket populärt system bland användare och nådde 26 miljoner användare 2001 och orsakade obehag bland skivbolag och musiker.
Det var därför RIAA (Recording Industry Association of America) och flera skivbolag, i ett försök att få slut på det, lämnade in en stämningsansökan mot företaget, vilket orsakade stängningen av dess servrar. Detta orsakade en nätverkskrasch eftersom användare inte kunde ladda ner sina musikfiler. Som en konsekvens migrerade en stor del av användarna till andra utbytessystem som Gnutella, Kazaa, etc.
Senare, runt 2008, blev Napster ett MP3-försäljningsföretag med ett stort antal låtar att ladda ner: free.napster.com.
Ostrukturerade P2P-nätverk
Ett annat sätt att dela filer är att använda ett icke-centraliserat nätverk, det vill säga ett nätverk där någon typ av mellanhand mellan användare elimineras så att nätverket själv ansvarar för att organisera kommunikation mellan kamrater.
I detta tillvägagångssätt, om en användare är känd, upprättas en "union" mellan dem, så att de bildar ett "nätverk" som kan anslutas av fler användare. För att hitta en fil, utfärdar en användare en fråga som översvämmer hela nätverket för att hitta det maximala antalet användare som har den informationen.
Till exempel, för att utföra en sökning i Gnutella, utfärdar den intresserade användaren en sökbegäran till sina grannar, och dessa till deras. Men för att undvika att kollapsa nätverket med en liten fråga är sändningshorisonten begränsad till ett visst avstånd från den ursprungliga värden och även förfrågningens livstid, eftersom varje gång meddelandet vidarebefordras till en annan användare minskar dess livstid.
Huvudproblemet med den här modellen är att om nätverket växer, kommer frågemeddelandet bara att nå ett fåtal användare. Om det vi letar efter är något välkänt, kommer säkert någon värd inom vår diffusionshorisont att ha det, men å andra sidan, om det vi letar efter är något mycket speciellt, kanske vi inte hittar det för genom att ha diffusionshorisonten begränsad, kommer vi att ha lämnat ut till värdar som kanske innehöll den information vi letade efter.
Hittills har rena icke-centraliserade P2P-nätverk ersatts med ny teknik, t.ex. Supernoder .
SUPERNODOS, en hierarki i ostrukturerade nätverk
De största problemen med ostrukturerade nätverk var diffusionshorisonten och nätets storlek. Vi har två möjliga lösningar: antingen ökar vi sändningshorisonten eller så minskar vi nätverkets storlek. Om vi väljer att öka sändningshorisonten ökar vi antalet värdar som vi måste skicka frågemeddelandet exponentiellt till. Detta skulle orsaka, som vi redan har sett, problem i nätverket, till exempel kollaps av det. Tvärtom, om vi väljer att minska storleken på nätverket kan systemen skala mycket bättre över nätverket med hjälp av supernoderna.
Huvudidén med detta system är att nätverket är uppdelat mellan många terminalnoder och en liten grupp supernoder som är väl anslutna mellan dem, till vilka terminalnoder är anslutna. För att vara en supernod är det nödvändigt att kunna erbjuda tillräckligt med resurser till andra användare, särskilt bandbredd. Detta nätverk av supernoder, till vilka endast ett fåtal kan bli en del, ansvarar för att hålla nätverksstorleken tillräckligt liten för att inte tappa effektiviteten i sökningar.
Dess funktion liknar den för hybridmodellen, eftersom terminalnoderna är anslutna till supernoderna, som tar rollen som servrar, så att användarna bara ansluter till andra användare för att uteslutande utföra nedladdningar. Supernoder lagrar information om vad varje användare har, så att det kan minska tiden för en sökning och skicka informationen till terminalnoderna som har det vi letar efter.
Denna typ av struktur används fortfarande mycket idag, främst för att den är mycket användbar för att utbyta information om populärt innehåll eller för sökning efter nyckelord. Eftersom nätverket av supernoder reduceras, skala dessa system mycket bra över nätverket och erbjuder inte brytpunkter som hybridmodellen. Å andra sidan minskar de robustheten mot attacker och nätverksfall och förlorar precision i sökandet efter resultat på grund av replikering genom supernoderna. Om ett litet antal supernoder misslyckas är nätverket uppdelat i små partitioner.
Strukturerade P2P-nätverk
Detta tillvägagångssätt utvecklas parallellt med supernodetillvägagångssättet som beskrivs ovan. Dess huvudsakliga kännetecken är att det istället för att ta hand om att organisera noderna fokuserar på organisering av innehåll, gruppering av liknande innehåll i nätverket och skapande av en infrastruktur som möjliggör effektiv sökning bland annat.
Kollegorna organiserar inbördes ett nytt virtuellt nätverkslager, ”ett overlay-nätverk”, som ligger ovanpå det grundläggande P2P-nätverket. I detta överläggsnätverk ges närheten mellan värdar som en funktion av innehållet de delar: de kommer närmare varandra ju fler resurser de tillhandahåller gemensamt. På detta sätt garanterar vi att sökningen utförs effektivt inom en inte alltför avlägsen horisont och utan att nätets storlek minskar. Som ett exempel, JXTA, där kamrater agerar i ett virtuellt nätverk och är fria att bilda och lämna grupper av kamrater. Således förblir sökmeddelanden normalt inom det virtuella nätverket och gruppen fungerar som en grupperingsmekanism som kombinerar par med samma eller liknande intressen.
Detta tillvägagångssätt erbjuder högpresterande och exakta sökningar, om det virtuella nätverket korrekt återspeglar likheten mellan noder med avseende på sökningar. Men det har också en rad nackdelar: det har höga kostnader för att etablera och underhålla det virtuella nätverket i system där värdar går in och går mycket snabbt; de är inte särskilt lämpliga för sökningar som inkluderar booleska operatörer, eftersom noder som kan söka med mer än en term skulle behövas.
En underklass inom denna typ av P2P-nätverk distribueras hashtabeller.
Distribuerade hashtabeller (DHT)
Det huvudsakliga kännetecknet för DHT är att de inte organiserar överläggsnätverket efter dess innehåll eller dess tjänster. Dessa system delar upp hela arbetsytan med hjälp av identifierare, som tilldelas de kamrater som använder detta nätverk, vilket gör dem ansvariga för en liten del av den totala arbetsytan. Dessa identifierare kan till exempel vara heltal i intervallet [0, 2n-1], där n är ett fast antal.
Varje par som deltar i detta nätverk fungerar som en liten databas (uppsättningen av alla par skulle bilda en distribuerad databas). Denna databas organiserar din information parvis (nyckel, värde). Men för att veta vilket par som ansvarar för att spara det paret (nyckel, värde) behöver vi att nyckeln är ett heltal inom samma intervall som de deltagande paren i nätverket är numrerade med. Eftersom nyckeln kanske inte representeras i heltal behöver vi en funktion som omvandlar nycklarna till heltal inom samma intervall som paren är numrerade med. Denna funktion är hash-funktionen. Denna funktion har den egenskapen att när den står inför olika ingångar kan den ge samma utgångsvärde, men med mycket låg sannolikhet. Det är därför vi istället för att prata om en ”distribuerad databas”, om Distribuerad Hashes-tabell (DHT), för vad varje par i paret (nyckel, värde) faktiskt lagrar är inte nyckeln som sådan utan hash för nyckel.
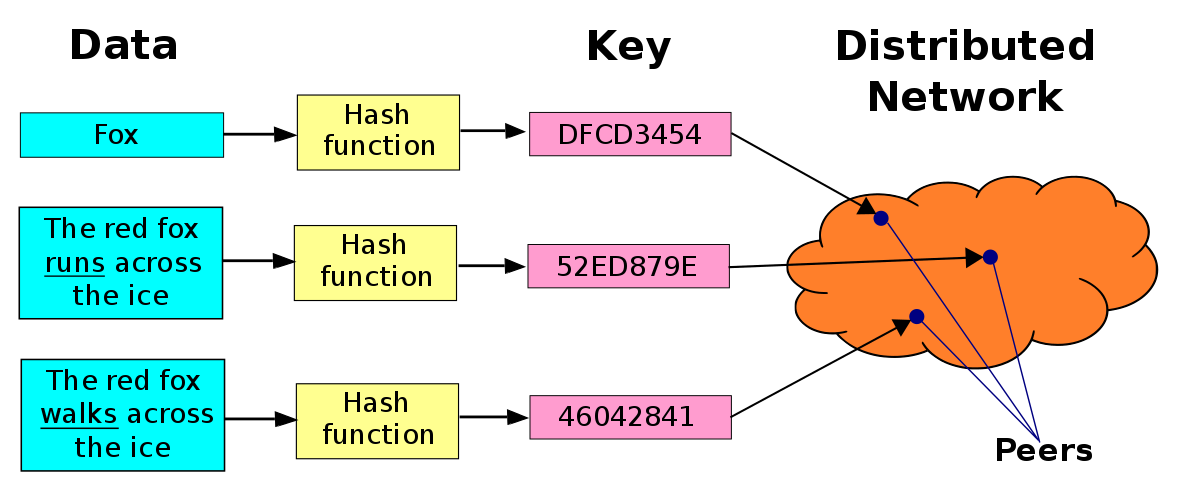
Vi har redan diskuterat att varje par ansvarar för en del av nätverksarbetsytan. Men hur mappar du paret (nyckel, värde) till rätt par? För detta följs en regel: när nyckeln till nyckeln har beräknats tilldelas paret (nyckel, värde) till paret vars identifierare är närmast (den omedelbara efterföljaren) till den beräknade hashen. I det fall den beräknade hashen är större än parens identifierare används modulo 2n-konventionen.
När vi väl har pratat lite om DHT: s grundläggande funktion kommer vi att se ett exempel på dess implementering genom CHORD-protokollet.
Distribuerat sökprotokoll i P2P-nätverk: CHORD
Chord är ett av de mest populära distribuerade sökprotokollen på P2P-nätverk. Detta protokoll använder SHA-1-hashfunktionen för att tilldela, både till paren och till den lagrade informationen, deras identifierare. Dessa identifierare är ordnade i en cirkel (tar alla värden modulo 2m), så att varje nod vet vem dess förfader och dess mest omedelbara efterträdare är.
För att upprätthålla skalbarheten i nätverket, när en nod lämnar nätverket, överförs alla dess nycklar till dess omedelbara efterträdare, på ett sådant sätt att nätverket alltid hålls uppdaterat, vilket undviker att sökningar kan vara felaktiga.
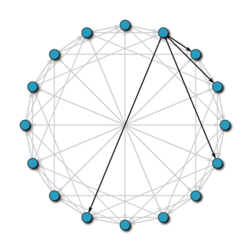
För att hitta den ansvariga som lagrar en nyckel skickar noderna meddelanden till varandra tills de hittar den. Men på grund av nätets cirkulära arrangemang kan en fråga i värsta fall täcka hälften av noderna, vilket gör det mycket dyrt att underhålla det. För att undvika detta och därmed minska kostnaderna har varje nod en routingtabell lagrad, där adressen till noder som ligger ett visst avstånd från den lagras. På det här sättet, när vi vill veta vem som ansvarar för nyckeln k, söker noden i dess dirigeringstabell för att se om den har adressen till den person som ansvarar för k; om den gör det skickar den begäran direkt. om den inte har den skickar den frågan till närmaste nod av k, vars identifierare är mindre än k.
Med denna förbättring har vi lyckats sänka kostnaden för sökningar från N / 2 till log N, där N är numret på nätverksnoden.
Slutsatser.
Som vi har sett finns det många typer av P2P-nätverk, alla med sina styrkor och svagheter. Ingen sticker ut över den andra, vilket gör det möjligt att, när man till exempel programmerar en P2P-applikation, ha flera alternativ, var och en med sina egna egenskaper.
En sak att tänka på är hur sättet att dela information utvecklas. I slutet av det senaste årtusendet var användningen av P2P-nätverk riklig och för de flesta var det det enda kända sättet att dela information. Idag har trenden förändrats. Människor föredrar nu att utbyta filer via stora servrar där de i vissa fall betalar användare för att vara värd för dem.
Några frågor som kan komma att tänka på är: Vad är framtiden för P2P-nätverk? Mot vilka former av organisering av information har vi utvecklats?
En av de möjliga utvecklingen är hoppet från P2P till p4p. Vad är P4P? Som en sammanfattning kommer vi att säga att P4P, även känd som hybrid P2P, är en liten utveckling av P2P vars huvudsakliga kännetecken är att tjänsteleverantörer, ISP: er, utgör en viktig roll inom nätverket, eftersom när det gäller att göra En sökning kommer först att söka bland de deltagande noder som tillhör samma ISP.