Datorer är inte längre som deras början att köra en process och tack, de har nu möjlighet att köra ett enormt antal program parallellt. Några av dem ser vi i våra spel, andra är osynliga, men där är de, som utförs av CPU. Finns det ett samband mellan processerna i programvaran och körningstrådar med maskinvarans?
Vi hör ofta eller läser tråden om körning när vi hör om nya processorer, men också i programvaruvärlden. Det är därför vi har beslutat att förklara skillnaderna mellan vilka processer eller trådar för körning i programvaran och deras betydande ekvivalenter i hårdvaran.
Processer i programvaran

I sin enklaste definition är ett program inget annat än en serie instruktioner som ordnas sekventiellt i minnet, som behandlas av CPU: n, men verkligheten är mer komplex. Alla med lite kunskap om programmering kommer att veta att denna definition motsvarar de olika processer som körs i ett program, där varje process interkommunicerar med de andra och finns i en del av minnet.
Idag har vi ett stort antal program som körs på vår dator och därför ett mycket större antal processer, som kämpar för att komma åt CPU -resurserna som ska köras. Med så många processer samtidigt behövs en ledare för att hantera dem. Detta arbete ligger i händerna på operativsystemet, som, som om det vore ett trafikkontrollsystem i en storstad, ansvarar för att hantera och planera de olika processerna som kommer att utföras.
Emellertid kallas programvaruprocesser ofta som exekveringstrådar, och det är ingen dålig definition om vi tar hänsyn till deras karaktär, men definitionen sammanfaller inte i båda världarna, så de är ofta förvirrade och detta leder till flera missförstånd om hur multithreaded hårdvara och programvara fungerar. Det är därför som vi i denna artikel har beslutat att ringa trådarna i programvaruprocesserna för att skilja dem från hårdvarans.
Begreppet bubbla eller stopp i en CPU
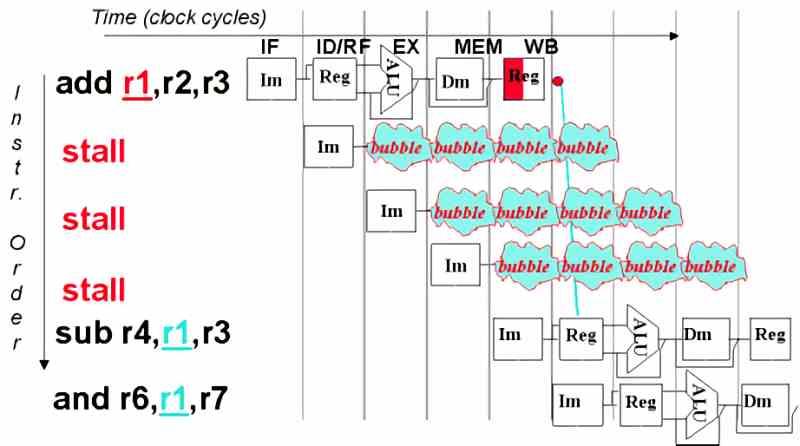
En bubbla eller stopp i körningen uppstår när en process som kör CPU: n av någon anledning inte kan fortsätta, men inte heller har avslutats i operativsystemet. Av denna anledning har operativsystem möjlighet att avbryta en körningstråd när CPU: n inte kan fortsätta och tilldela arbetet till en annan kärna som är tillgänglig.
I hårdvaruvärlden dök det upp i början av 2000 -talet vad vi kallar multithreading med Hyperthreading of Pentium IV. Tricket var att duplicera CPU: s styrenhet som är ansvarig för att fånga och avkoda. Med detta uppnåddes att operativsystemet kommer att se CPU: n som om de var två olika CPU: er och tilldelade uppgiften till den andra styrenheten. Detta fördubblar inte effekten, men när själva CPU: n fastnade i en körningstråd gick den omedelbart över till den andra för att dra nytta av stilleståndet som inträffade och få mer prestanda från processorerna.
Multitrådning på hårdvarunivå genom att duplicera styrenheten, som är den mest komplexa delen av en modern CPU, ökar strömförbrukningen helt. Därför har processorerna för smartphones och surfplattor inte maskinvarutrådning i sina processorer.
Prestanda beror på operativsystem
Även om CPU: er kan köra två körningstrådar per kärna, är det operativsystemet som ansvarar för att hantera de olika processerna. Och idag är antalet processer som körs på ett operativsystem större än antalet kärnor en CPU kan köra samtidigt.
Eftersom operativsystemet har ansvaret för att hantera de olika processerna är det därför också den som ansvarar för att tilldela dem. Detta är en mycket enkel uppgift om vi talar om ett homogent system där varje kärna har samma kraft. Men i ett totalt heterogent system med kärnor med olika krafter är detta en komplikation för operativsystemet. Anledningen till detta är att den behöver ett sätt att mäta vilken beräkningsvikt varje process har, och detta mäts inte bara av vad den upptar i minnet, utan av komplexiteten i instruktionerna och algoritmerna.
Hoppet till hybridkärnor har redan skett i världen av ARM processorer där operativsystem som t.ex. iOS och Android har behövt anpassa sig till användningen av kärnor av olika föreställningar som fungerar samtidigt. Samtidigt har styrenheten för framtida konstruktioner behövt kompliceras ytterligare i x86. Målet? Att varje process i programvaran körs i lämplig tråd i hårdvaran och att själva CPU: n har mer oberoende i utförandet av processerna.
Hur är utförandet av processer på GPU: erna?

GPU: erna i deras shader -enheter kör också program, men deras program är inte sekventiella, utan varje exekveringstråd består snarare av en instruktion och dess data, som har tre olika villkor:
- Data finns bredvid instruktionen och kan köras direkt.
- Instruktionen hittar dataens minnesadress och måste vänta på att data kommer från minnet till shader -enhetens register.
- Data beror på utförandet av en tidigare körningstråd.
Men a GPU kör inte ett operativsystem som kan hantera de olika trådarna. Lösningen? Alla GPU: er använder en algoritm i schemaläggaren för varje shader -enhet, motsvarande kontrollenheten. Denna algoritm kallas Round-Robin och består av att ge en exekveringstid i klockcykler till varje körning / instruktionstråd. Om detta inte har lösts under den tiden går det till kön och nästa instruktion i listan körs.
Shader -programmen är inte sammanställda i koden, på grund av det faktum att det finns väsentliga skillnader i den interna ISA för varje GPU, styrenheten ansvarar för att sammanställa och paketera de olika exekveringstrådarna, men programkoden ansvarar för hanteringen dem. . Så det är ett annat paradigm än hur CPU: n utför de olika processerna.