Under sin presentation 2019 om framtiden för Intel Xe-arkitektur, Raja Koduri nämnde en typ av minne som Intel har döpt "Rambo Cache" och det är en av de viktigaste delarna för Intel Xe. Men vad är egentligen Rambo Cache och vad är dess användning? Vi förklarar det för dig.
Hur gör vi ett stort antal GPU chiplets kommunicerar effektivt med varandra? Vi behöver ett minne för att göra intercomarbetet och det är där Rambo Cache kommer in. Vi förklarar hur den fungerar och vilken funktion den har.

Rambo Cache som skillnad mellan Xe-HP och Xe-HPC

Som man kan se i Intel-bilden är Rambo Cache i sig ett chip som innehåller ett minne inuti, som exklusivt kommer att användas i Intel Xe-HPC för kommunikation mellan de olika brickorna / chipletterna. . Medan Intel Xe-HP stöder upp till fyra olika brickor, hanterar Intel Xe-HPC en mycket högre mängd data, vilket gör detta ytterligare minneschip nödvändigt som en kommunikationsbro för extremt komplexa konfigurationer när det gäller datamängden. GPU-chiplets eller brickor som Intel kallar dem.

Rambo Cache kommer att placeras mellan flera Intel Xe-HPC Compute Tiles för att underlätta kommunikationen mellan dem. Compute Tiles är inget annat än Intel Xe GPU: er men specialiserade för högpresterande datorer, så de klassiska fasta funktionsenheterna i GPU: er kommer inte att finnas i Intel Xe-HPC eftersom de inte används i högpresterande datoranvändning.
Rambo Cache kommer dock att vara oöverträffad i resten av Intel Xe, speciellt de som inte kommer att baseras på flera marker som Intel Xe-LP och Intel Xe-HPG. I det specifika fallet med Intel Xe-HP verkar det som om med 4 chipletter Rambo Cache inte är nödvändig på grund av det faktum att Interposer ger tillräckligt med bandbredd för att kommunicera de olika chiplets som är monterade ovanpå den.
Målet är att nå ExaFLOP

Vi vet att gränsen för antalet chiplets på en interposer är 4 GPU: er, men från ett högre tal är det när sammankopplingen baserad på en EMIB-interposer inte längre ger tillräcklig bandbredd för kommunikation, vilket gör att ett element är nödvändigt som förenar tillgång till minnet och det är där Rambo Cache skulle komma in, eftersom det skulle göra det möjligt för Intel att göra en mer komplex GPU än de maximalt fyra chipletter som den kan bygga med EMIB.
Målet? Att kunna skapa en hårdvara som på ett kombinerat sätt kan nå 1 PetaFLOP våld eller med andra ord 1000 TFLOPS. En prestanda som är mycket högre än de grafikprocessorer som vi har på PC, men vi talar inte om en GPU för PC utan om en hårdvara avsedd för superdatorer, med målet att nå ExaFLOP-milstolpen, som är 1000 PetaFLOPS och därmed 1 miljon TeraFLOPS.
Hårdvaruarkitekternas stora intresse för att uppnå detta är energiförbrukningen, särskilt vid dataöverföring, fler beräkningar mer data och mer data flyttar mer energi. Det är därför det är viktigt att hålla data så nära processorerna som möjligt och det är här Rambo Cache kommer in.
Rambo-cachen som en toppcache
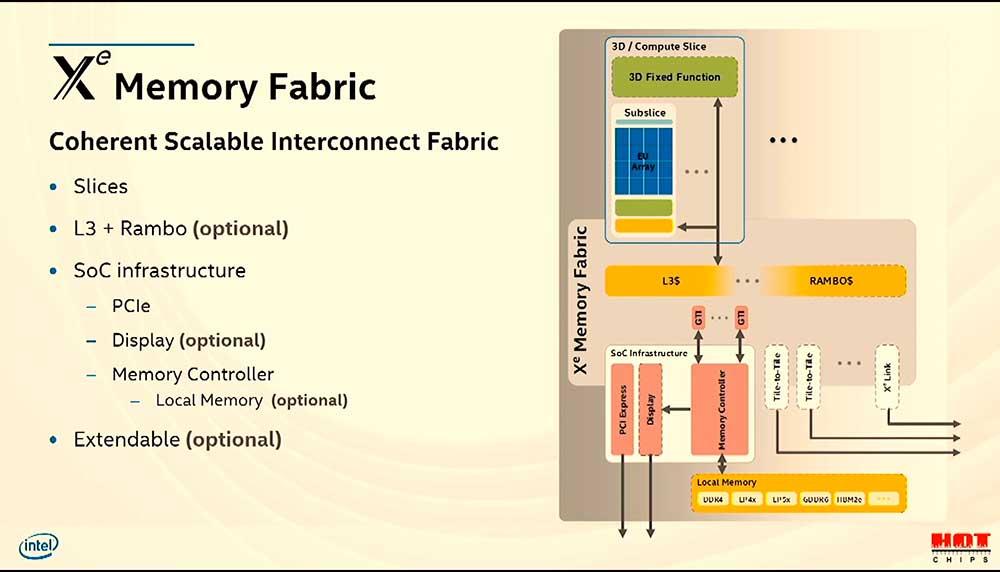
När vi har flera kärnor, oavsett om vi pratar om a CPU eller en GPU, och vi vill att alla ska få åtkomst till samma minne både på adresserings- och fysisk nivå, då behövs en cache på sista nivå. Dess "geografiska" plats i GPU: n ligger precis före minneskontrollen men efter varje kärnas privata cacheminnet.
GPU: er har idag minst två nivåer av cache, den första nivån berövas från skuggningsenheter och är vanligtvis ansluten till texturenheter. Den andra nivån delas istället av alla element i en GPU. I det här fallet är de din samtrafikväg för att kommunicera, få tillgång till de senaste uppgifterna och allt detta för att inte mätta VRAM-styrenheten med förfrågningar till den.
Men det finns en extra nivå, när vi har flera kompletta GPU: er sammankopplade med varandra under samma minne, behövs en extra nivå av cache som grupperar åtkomst till alla minnen. Intels Rambo Cache är Intels lösning för att förena tillgången till alla GPU: er som tillsammans utgör Ponte Vecchio.