OCR-teknik har funnits länge och har varit nyckeln till att underlätta för många människor eftersom det är förmågan att konvertera karaktärerna som är en integrerad del av en bild till karaktärer som kan manipuleras, vilket undviker den tråkiga uppgiften att transkribera texten . Men vad ligger bakom allt?
OCR används dygnet runt idag och inte bara för att digitalisera texter utan också för saker som realtidsöversättningar av text skriven på andra språk, och vi kan till och med konvertera vår handskrivna text till tryckt text.

OCR och mönsterigenkänning
Vi förstår som ett mönster en modell som tjänar till att få något annat liknande; Medan våra ögon och hjärna identifierar vad varje bokstav är genom stavningen, har en dator inte den förmågan för abstraktion och behöver kunna göra en jämförelse, vilket alltid är resultatet av en subtraktion mellan två element: om subtraktionen ger 0 så det betyder att jämförelsen är positiv.
1960 skapade Lawrence (Larry) Roberts, en MIT-forskare som paradoxalt nog senare var en av uppfinnarna av vad som så småningom skulle bli Internet, ett teckenigenkänningssystem och en tillhörande typsnitt, utformad för att kunna digitalisera bankcheckar och så vidare. på. känslig information som behövde lagras av tidiga datorer. Denna källa kallades OCR-A.

Om vi tänker på det, för en dator är en bokstav som alla andra typer av data inget annat än en uppsättning bitar, så allt vi behöver är att ha den lagrad i systemet som ansvarar för att jämföra vad typsnittet har i olika storlekar som ett jämförande teckensnitt.
Teckenigenkänning via OCR
Det första OCR-systemet kommer att göra är att läsa dokumentet för att lokalisera texten och eliminera, för senare analys, allt som inte är användbart för optisk teckenigenkänning.
När du bara har karaktärerna går det att gå igenom det som är kvar av bilden och ta block av den och digitalisera dem för en senare jämförelse med informationen i minnet. Med andra ord, vad karaktärsavkänningssystemet gör är att korsa bilden genom att läsa den i block med ett regelbundet antal pixlar och göra kontinuerliga jämförelser med de former som den har lagrat i sitt minne.

Om den hittar en matchning, markerar den den i en fil som den sedan visar och / eller lagrar som en slutsats. nämnda fil kommer att vara en textfil med själva texten extraherad genom igenkänningsprocessen.
Detta innebär att vårt karaktärsigenkänningssystem måste ha i minnet teckensnittet där texten har skrivits på papper eller i bilden som vi vill extrahera den från så länge den kan göra jämförelsen. Men vad händer i speciella fall som handskrift eller specialteckensnitt?
Curling curl, bortom OCR
När vi går tillbaka till hur vår hjärna fungerar identifierar den saker eftersom den har lärt sig ett mönster som gör att den kan identifiera dem. Vår hjärna vet mycket väl genom ett inlärt mönster att alla bokstäver i följande bild är bokstaven A.

Men en dator, i allmänhet, känner inte till den direkt och behöver det referenssystem som vi har kommenterat ovan för att veta om jämförelsen är positiv eller inte, vilket har lett till att när man läser handskriften - som är annorlunda för varje person - har var tvungen att gå igenom en lång satsning på flera år.
Som en historisk nyfikenhet, när Apple lanserade vad som kunde betraktas som världens första "handhållna" dator, Apple Newton, lovade de att det skulle ha ett handskriftsigenkänningssystem som skulle konvertera användartypade texter för att skrivas ut i tid. verklig.

Resultatet? En katastrof, eftersom jag inte kände igen hur de flesta skriver och enheten var ett fullständigt misslyckande.
Anledningen till detta var inte att Newton och senare system var dåliga utan för att det krävdes mycket datorkraft för att utföra mönsterigenkänning, vilket inte fanns tillgängligt och inte har varit tillgängligt på länge. Även handskriftsigenkänningssystem stöder enorma data- och behandlingscentra som de kommunicerar med via Internet.
Artificiell intelligens för att rädda karaktärsigenkänning
System för artificiell intelligens är faktiskt system som tränas för att känna igen specifika mönster och kan tränas för att lära sig känna igen karaktärer, inte från ett jämförande element utan genom att tillämpa mönster. Till exempel kan vi identifiera bokstaven A med ett enkelt mönster som följande:
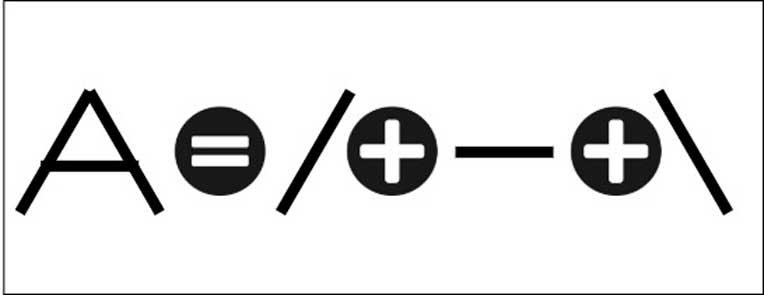
Men tanken är att träna maskinen så att den vet hur man känner igen mönstret utan att behöva göra jämförelsen och det är vid denna punkt där artificiell intelligens kommer in. På samma sätt som vi kan träna en artificiell intelligens för att känna igen trafikskyltar så att den kan köra i automatiskt läge kan vi också lära den att lära sig att identifiera karaktärer. På vilket sätt? Tja, genom ett neuralt nätverk som tidigare har utbildats för det.
Det mest använda i dessa fall är de så kallade fällningsneurala nätverken, som är en typ av konstgjord neuron som har en liknande struktur som neuronerna i den primära visuella cortexen i en biologisk hjärna och är utmärkta för klassificering och segmentering av bilder. och andra applikationer för datorsyn.
Vad dessa neurala nätverk gör är att kopiera funktionen hos de biologiska systemen som ansvarar för att upptäcka de mönster som gör att vi kan identifiera vad varje bokstav är.
Samtidigt sparas det exemplet i databasen varje gång en identifiering är positiv och bekräftas flera gånger för att användas som ett mönster senare. I själva verket fungerar systemen i det fallet först om det finns en korrespondens i databasen som har skapats och bara när den inte hittar det är när mekanismerna för att identifiera mönster via artificiell intelligens aktiveras.