
En av de viktigaste delarna av vilken arkitektur som helst är Load-Store-enheterna, som ansvarar för att utföra de minnesrelaterade instruktionerna på båda CPU och GPU. Om du vill veta vad funktionen är och hur dessa enheter fungerar på ett enkelt och tillgängligt sätt, fortsätt läsa.
Kommunikationen av CPU: n med minnet är viktig, här på HardZone har vi gjort flera artiklar för att förklara de olika elementen och nu är det Load-Store-enheternas tur, som är väsentliga och därför väsentliga i alla arkitekturer både CPU och GPU .
Vad är Load-Store-enheter?
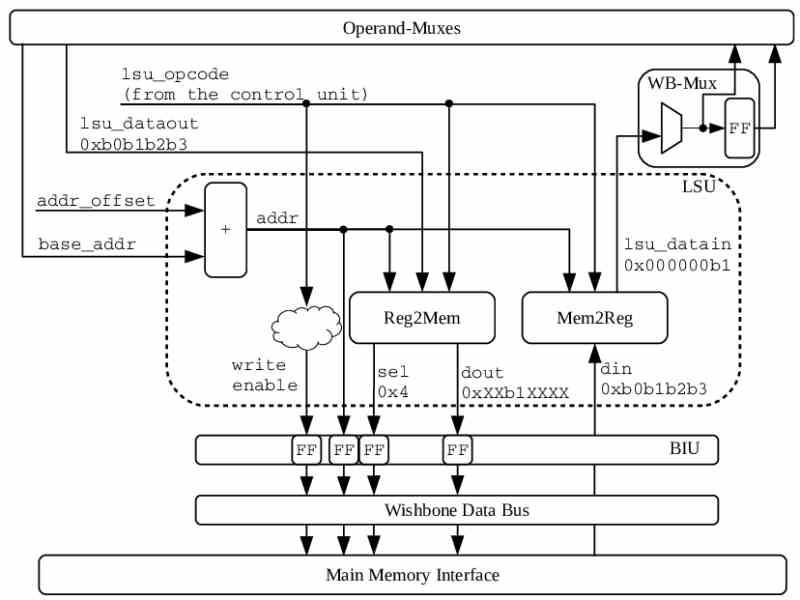
Det är en exekveringsenhet i en CPU, exekveringsenheter är de som används för att lösa en instruktion när den har avkodats. Låt oss komma ihåg att det finns andra typer av exekveringsenheter:
- ALU: er är olika typer av enheter som är ansvariga för att utföra olika typer av aritmetiska operationer. De kan arbeta med ett enda nummer, en rad med siffror eller till och med i en matris.
- Hoppsenhet: dessa enheter tar hoppinstruktionerna i koden, vilket innebär att körning flyttar till en annan del av minnet.
Load / Store-enheterna å andra sidan har ansvaret för att utföra instruktionerna relaterade till åtkomst till RAM systemets minne, oavsett om du läser eller skriver. Det finns ingen L / S-enhet, men det finns två typer av enheter som fungerar parallellt och som hanterar åtkomst till data.
Den enklaste beskrivningen av dess funktion är som följer: en laddningsenhet ansvarar för att lagra information från RAM-minne till registren och en lagringsenhet gör det i motsatt riktning. För att fungera har de sitt eget minne för denna typ av enhet, där de lagrar minnesförfrågningarna för varje instruktion.
Var finns Load-Store-enheterna?
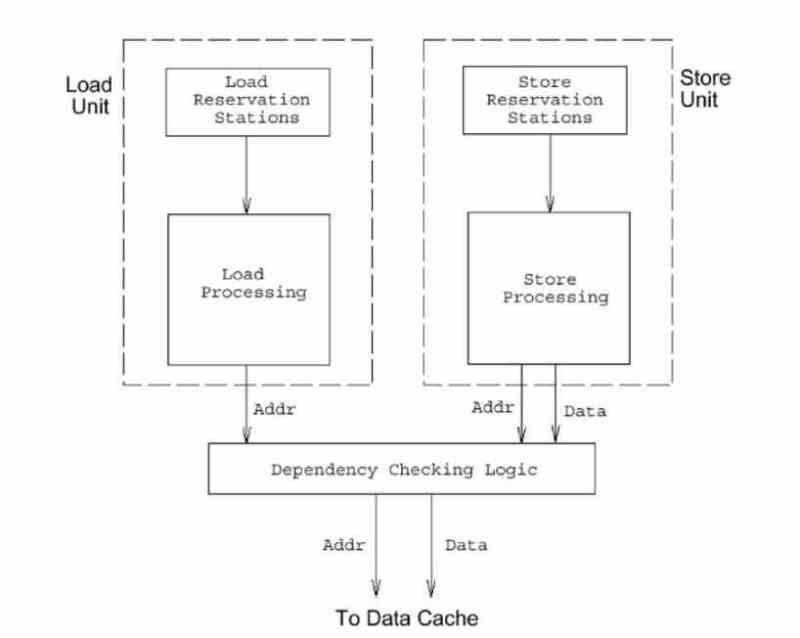
Det första vi kan tänka oss är att Load / Store-enheterna ligger så nära processorn som möjligt, men trots att deras uppgift är att flytta data från RAM till register har de inte direkt tillgång till RAM , utan snarare att En annan mekanism som vi redan pratat om i: ” Så här kommer åt CPU: n RAM-minnet så snabbt ”Är ansvarig, där vi pratar om kommunikationen mellan processorns minnesgränssnitt och RAM-minnet.
I sin enklaste uppfattning kommunicerar Load / Store-enheterna med gränssnitten som kommunicerar processorn med RAM-minnet, specifikt med MAR- och MDR-registren, och är de enda enheterna med tillstånd att manipulera nämnda register, samt att överföra data till de olika registren för utförande av vissa instruktioner.
Därför är Load / Store-enheterna inte belägna i den del som ligger närmast minnet, utan är placerade halvvägs mellan register över register för olika exekveringsenheter och minnesgränssnittet som används i varje processor. finns i omkretsen.
Lägga till en cachehierarki
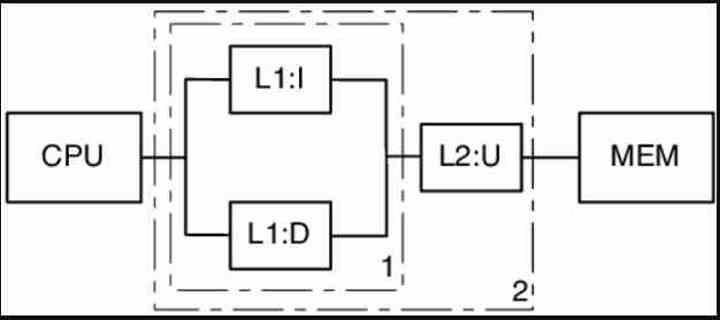
Cachen är inget annat än internminnet till processorn som kopierar data närmast där kodkörningen är just nu. Varje ny nivå i hierarkin har större lagringskapacitet, men samtidigt är den långsammare och har högre latens. Istället på motsatt sätt innehåller varje cache-nivå endast en del av den tidigare, men den är snabbare och med lägre latens.
I nuvarande processorer innehåller alla nivåer information om instruktioner och data i samma minne förutom en nivå, vilket är den lägsta nivån cache. Där det finns en cache för instruktioner och en annan för data. Load / Store-enheter interagerar aldrig med instruktionscachen, utan med datacachen.
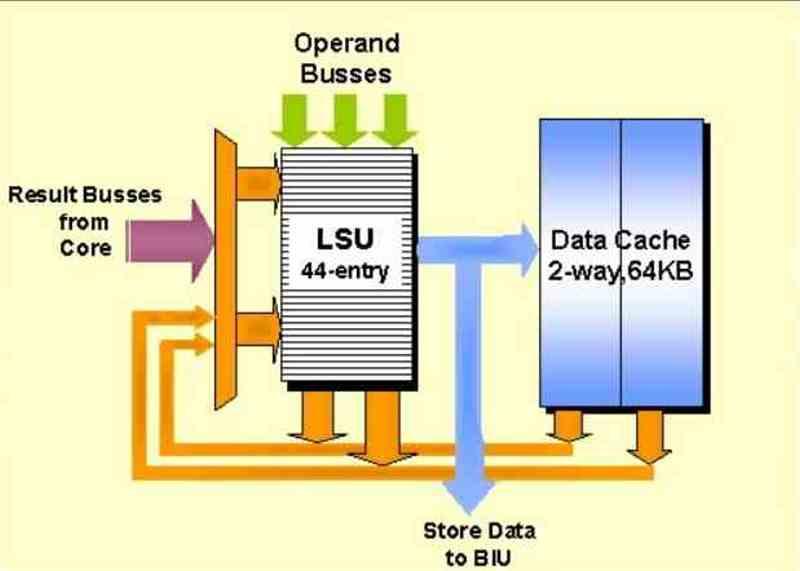
När laddningsenheterna i varje kärna behöver data är det första de "frågar" datacachen om de innehåller informationen för en viss minnesadress. Operationen är skrivskyddad, så om de hittar den kommer de att kopiera den från cachen till motsvarande register. Om den inte hittar den i en cache-nivå kommer den att gå ner nivå för nivå. Tänk på det som någon som letar efter ett dokument i en pyramidal kontorsbyggnad, där varje nivå har fler filer att söka efter.
Å andra sidan är butikenheter lite mer komplexa, de söker också efter en minnesadress i cachen, men från det ögonblick som vi pratar om att ändra de data som finns inuti är det nödvändigt att det finns ett system av koherens som förändrar referens till den minnesadressen genom hela cachehierarkin och i RAM-minnet.
RISC = Load-Store?

När vi väl har lärt oss vad Load / Store-enheter gör måste vi ge dem historiskt sammanhang och det är att de inte är det enda sättet på vilket en CPU kan komma åt systemets RAM för att ladda och lagra data.
Load-Store-konceptet är relaterat till uppsättningar av register och instruktioner av RISC-typ, där instruktionsuppsättningen reduceras och ett sätt att göra det är att separera processen för åtkomst till minnet för de olika instruktionerna i en annan instruktion, såsom flera instruktioner. de kommer att ha en liknande minnesåtkomstprocess som använder Load / Store-enheter för att utföra den delen.
Konsekvenserna är redan kända för oss, den binära koden för programmen för CISC-instruktionsuppsättningar får en mer kompakt och mindre binär, medan RISC-enheterna har den större. Tänk på att RAM under de tidiga dagarna av datorer var mycket dyrt och knappt och det var viktigt att hålla den binära koden så liten som möjligt. Idag är alla x86-processorer Post-RISC, för när de avkodar x86-instruktioner gör de det i en serie mikroinstruktioner som tillåter CPU att fungera som om det vore en RISC-processor.
LSU på GPU: er

Ja, GPU: erna har också Load / Store-enheter, som finns i beräkningsenheterna och ansvarar för att leta efter de data som ALU: erna för detta måste utföra. Det måste komma ihåg att beräkningsenheterna från AMD, Underskivor från Intel eller Stream Multiprocessors från NVIDIA i bakgrunden finns olika signifikatorer för samma sak, GPU-kärnorna där deras program körs, känt i allmänhet som shaders.
De olika ALU: erna i en beräkningsenhet tenderar att arbeta på registernivå för det mesta, detta innebär att instruktionen kommer med data för att fungera direkt, men vissa instruktioner hänvisar till data som inte finns i registren, så det är nödvändigt för att söka efter dem genom cacheminnet.
Datasökningssystemet är detsamma som i processorer, först tittar det på datacache för varje beräkningsenhet och fungerar ner tills det når slutet av minneshierarkin så långt som GPU kan komma åt. Detta är viktigt vid åtkomst till stora data som texturkartor.
Fast funktion på GPU: er och Load-Store-enheter
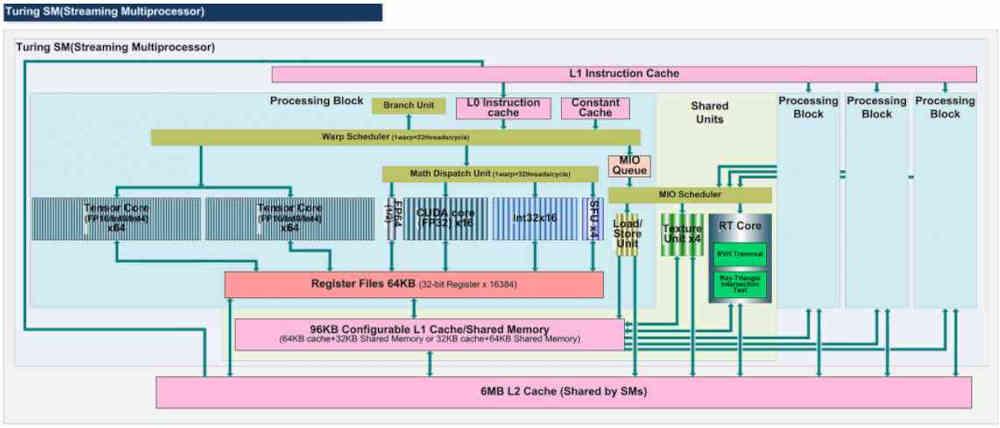
Vissa av enheterna i Compute Units använder Load-Store-enheterna för att kommunicera med GPU: n, dessa enheter är inte ALU, utan oberoende enheter med fast funktion eller acceleratorer. Idag finns det två typer av enheter som använder Load / Store-enheterna i en GPU:
- Texturfiltreringsenheter
- Enheten som ansvarar för att beräkna skärningspunkten mellan strålar i strålspårning
Eftersom dessa enheter behöver komma åt datacache för att få ditto som ingångsparametrar för att utföra deras funktion. Antalet Load / Store-enheter i en beräkningsenhet är variabelt, men det är vanligtvis lika med eller större än 16, eftersom vi har 4 strukturenheter som kräver 4 data för att utföra det bilinära filtret.
På samma sätt lagras data för noderna i BVH-träden i de olika cache-nivåerna. I vissa specifika fall, till exempel NVIDIA GPU: er, har Ray Tracing-enheter en intern LSU som läser från RT-kärnans egna L0-cache.