
Det råder ingen tvekan om att det som kallas specialiserade enheter för artificiell intelligens har blivit en av de viktigaste hårdvarubitarna, speciellt om vi pratar om marknaden för PostPC-enheter där alla deras SoC har en enhet av denna typ, men det är inte fall av PC men saken kan helt förändra denna situation tack vare Intel AMX-tillägg.
För närvarande, om vi har en dator, är det enda sättet att ha en specialiserad enhet för AI genom att köpa separat hårdvara, antingen genom att köpa en GPU från NVIDIA RTX-familjen eller genom att köpa en FPGA monterad på en PCI Express-port.
Intel GNA, ett prejudikat
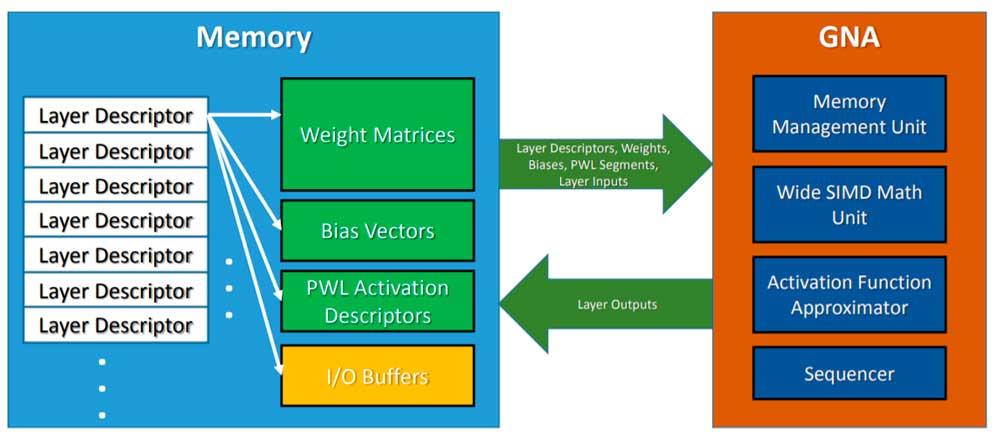
Intel har för närvarande en inbyggd enhet som heter GNA som kan köra vissa AI-baserade algoritmer men inte på samma sätt som en systolisk array eftersom GNA är en samprocessor med SIMD-konfiguration. Å andra sidan säljer Intel också lösningar baserade på FPGA: er och med sina Intel Xe GPU: er lovar HP att integrera enheter i Tensor Core-stil.
Men vad vi pratar om är just att integrera denna typ av enhet i en CPU, på ett sådant sätt att ett större antal applikationer kan dra nytta av denna typ av enhet.
Ett svar på Apples M1

En av fördelarna med AppleM1 är inte det ARM uppsättning register och instruktioner är mer energieffektiv, men det för vissa applikationer och funktioner Neural Engine är extremt effektiv .
Dessa typer av enheter har blivit viktiga på marknaden för smartphones och surfplattor eftersom de gör det möjligt att utföra mycket komplexa uppgifter på kort tid och med mycket få resurser, vilket har gjort att PC-processorer ligger efter i detta avseende.
Intel AMX
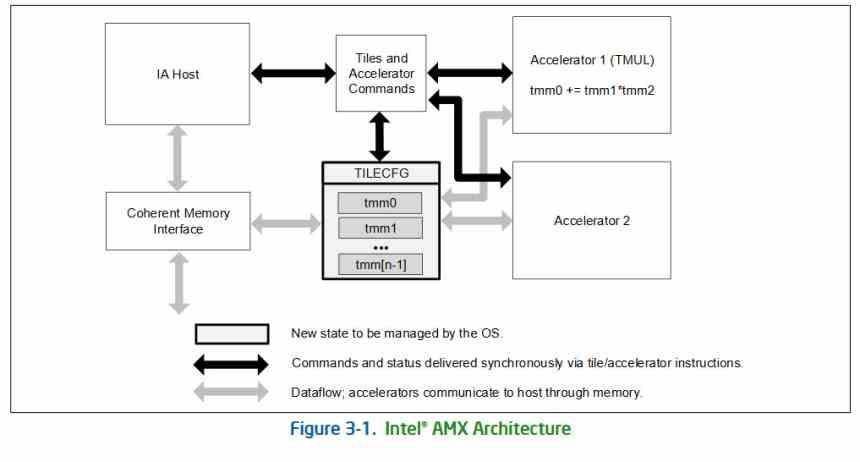
Som när SIMD-enheterna medförde implementeringen av nya x86-instruktioner, medför implementeringen av matris- eller tensorenheter en ny typ av instruktion, kallad AMX eller Advanced Matrix Extensions, som kommer att implementeras för första gången med Intel Xeon-arkitektur . Sapphire Rapids.
Tillägget lägger till ytterligare två element, å ena sidan, en tvådimensionell skivuppsättning som består av skivor som kallas "brickor" och en serie acceleratorer som kan fungera på dessa brickor. Dessa acceleratorer delar åtkomst till minne på ett konsekvent sätt med resten av CPU-elementen och kan fungera sammanflätade med och parallellt med andra x86-exekveringsenheter.
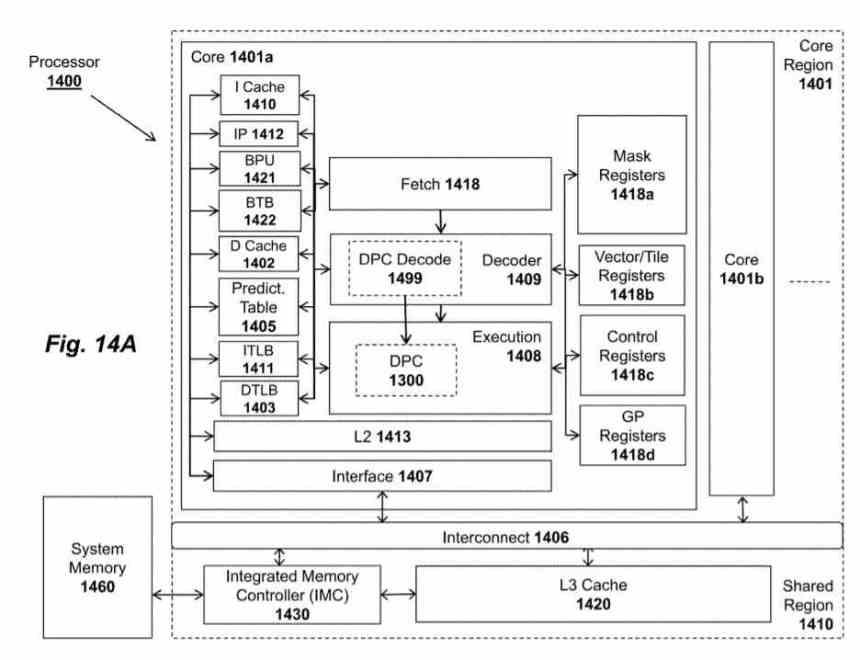
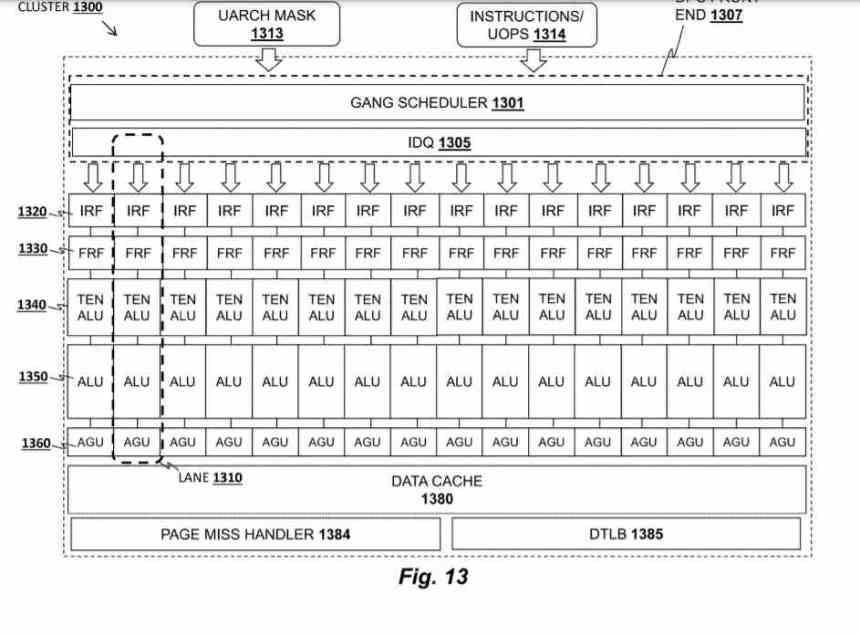
Acceleratorn heter Tile Matrix Multiply eller TMUL, det är en systolisk matris i form av ett nät av ALU som kan utföra FMA-instruktionen (Addition and Multiplication) i en enda cykel, som använder som poster de brickor som du har från talade om i föregående stycke.
In AMD patent kallas TMUL-enheten Data Parallel Cluster och det är en enhet som finns i var och en av processorkärnorna, även om Intel kommer att implementera den för första gången i Sapphire Rapids, det råder ingen tvekan om att vi kommer att se det implementeras i resten av Intel-processorer i framtiden.