När du köper en CPU eller ett GPU Vi hittar tekniska specifikationer som klockhastighet, antalet flytande punktoperationer, minnesbandbredd etc. Men ett av sätten att mäta prestanda och utforma en processor har att göra med instruktionernas latens. Vi förklarar vad det är och varför det är så viktigt att få snabbare processorer.
Prestanda för en processor över en annan mäts av den tid det tar att lösa samma program. Detta kan uppnås på många olika sätt och det finns olika sätt att öka prestanda och därmed minska den tid det tar att springa. En av dem är att minska latensen för instruktionerna som körs. Men vad exakt består det av?

Vad menar vi med instruktionsfördröjning?
Latency är den tid det tar en processor att utföra en instruktion och detta är variabelt från var data ligger, eftersom ju längre det är desto mer tid det har att resa för att dessa ska placeras i motsvarande register. Det är av den anledningen och eftersom minnet inte skalas med samma hastighet som processorerna, måste mekanismer som cache skapas och till och med integrera minneskontrollern i processorn för att minska instruktionernas latens.
Detta tas dock vanligtvis inte i beaktande när man säljer en CPU och till och med en GPU, andra prestandamått används ofta för att tala om att en arkitektur är överlägsen en annan. Men latens för instruktionerna används vanligtvis inte när du marknadsför en processor när det är ett sätt att förstå prestanda till.
Klockcykler per instruktion och latens

Det första måttet på prestanda är cykler per instruktion, eftersom det finns instruktioner som är tillräckligt komplexa för att behöva utföras i flera olika instruktionscykler. Många gånger vid utformning av nya processorer gör arkitekter ofta förändringar i sättet att lösa en instruktion med avseende på tidigare processorer med samma ISA, oavsett om vi pratar om processorer, GPU: er eller någon annan typ av processor.
Det som aldrig ändras är instruktionens form, men vad som görs är att minska antalet klockcykler som är nödvändiga för att klättra i den. Till exempel kan vi ha en instruktion som ansvarar för att beräkna medelvärdet mellan två nummer som tar fyra klockcykler i en processor med samma ISA och som förbättras med 4% till en tidigare version av samma instruktion som tar 20 cykler.
Tanken är ingen annan än att minska den tid det tar för en del av instruktionerna för att minska den tid det tar att köra ett program. På detta sätt uppnås det med små accelerationer i instruktionerna att den totala prestandan ökar.
Cache och instruktionslatens

Cacheminnet lagrar en kopia av RAM minne till vilket instruktionerna som utförs vid den tidpunkten, gör det möjligt för processorn att komma åt minnet utan att behöva komma åt RAM-minnet och eftersom cachen ligger närmare enheterna i CPU: n att minnet slutar kunna utföra instruktionen på kortare tid, eftersom det tar kortare tid att fånga instruktioner.
Det faktum att vi pratar om olika cache-nivåer betyder inte att alla cache-nivåer på första nivå, andra nivå och till och med tredje nivå har samma avstånd och därför latens, utan snarare att de varierar från en arkitektur till en annan. Till exempel i strömmen Intel Core från Intel, latensen med cacheminnet är lägre än i deras konkurrents motsvarigheter, AMDs AMD Zen.
För att förbättra en arkitektur från en version till en annan är en av de ändringar som vanligtvis höjs minskningen av latens med avseende på cachen. Speciellt när man portar samma arkitektur från en nod till en annan tack vare minskningen av processorstorleken och avståndet mellan enheterna och cachen.
Chiplet och latensdilemma

Idén med chiplets är ingen annan än att använda flera marker istället för bara en för samma funktion, detta ökar därför kommunikationsavståndet mellan de olika delarna och därmed latensen. Detta resulterar i prestandaförlust jämfört med processorns monolitiska version.
När det gäller AMD Ryzen, som är det mest kända fallet, är ett sätt att minska skillnaden mellan versionerna baserat på chiplets och de som är monolitiska processorer att klippa cache på sista nivå på några sekunder. Anledningen? Om de hade samma mängd cache skulle versionerna via chiplet endast på grund av avståndet från minneskontrollern ha lägre latens i instruktionerna och därmed högre prestanda.
Instruktionsfördröjning är nyckeln till 3DIC

Chippen integrerade i tre dimensioner är en annan av de viktigaste punkterna, särskilt de som staplar minne på en processor. Anledningen till detta är att de placerar minnet så nära processorn att det bara ökar prestanda. Avvägningen av detta är termisk kvävning mellan minnet och processorn, vilket tvingar klockhastigheten att sjunka, och i vissa utföranden kan det hända att placera processorn och minnet separat möjliggör högre klockhastigheter än i en 3DIC-design.
Om minnet är tillräckligt nära processorn kan det skapa en nyfiken effekt, där det tar mindre tid att komma åt data i det inbäddade minnet än att gå igenom de olika cache-nivåerna i arkitekturen en efter en. Vilket helt förändrar sättet som en processor är utformad på, eftersom cacheminne är ett sätt att minska latens när data som ska bearbetas ligger för långt ifrån varandra.
Avstånd och konsumtion är relaterade
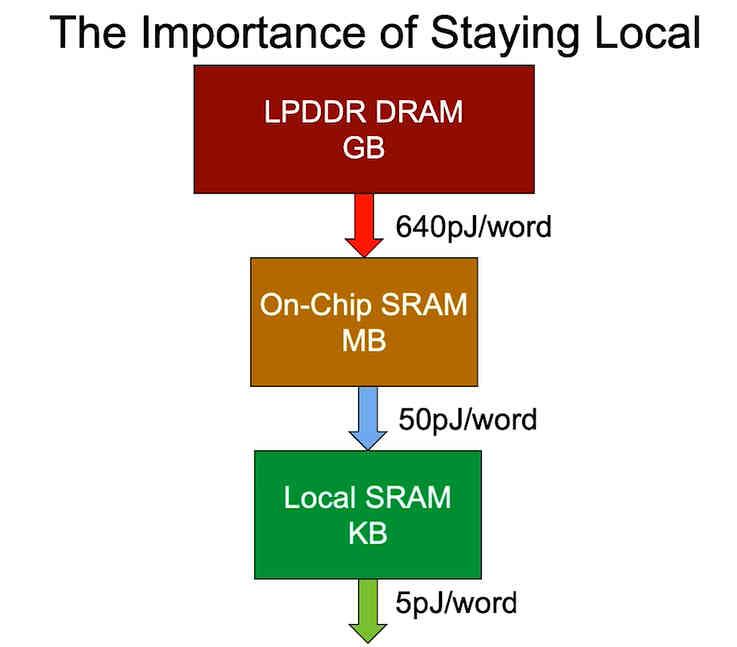
Den sista punkten är energiförbrukningen, som beror på var data ligger. Det är därför när man designar en mer optimerad version i termer av processorförbrukning, det som man söker är att minska avståndet på vilket data ligger, eftersom en processors energiförbrukning ökar med avståndet i låt data hittas och inte bara latens, tyvärr kan vi inte passa de enorma mängder data vi behöver för att köra ett program inom ett chips utrymme.
I en värld där energiförbrukning på grund av klimatförändringar har blivit en av de viktigaste punkterna och bärbarhet och låg förbrukning är en försäljningsargument och därför värdefull i många produkter, det faktum att leta efter sätt att föra minne närmare processorn och därmed minska latens för instruktionerna, något som blir extremt viktigt för att öka prestandan per watt.