
Vilken CPU gör är att utföra instruktionerna för ett program som finns i minnet. Men visste du att de alla följer samma allmänna regler? De följer alla samma instruktionscykel, som är uppdelad i tre distinkta steg som kallas Fetch, Decode and Execute, som översätts som hämtning, avkodning och exekvering. Vi förklarar hur dessa steg fungerar och hur de är organiserade.
För att förenkla och göra begreppen förklarade i den här artikeln mer begripliga har vi beslutat att beskriva en extremt enkel processor för nuvarande tider, så i den här artikeln kommer du att se en förklaring av vilka instruktionscykler som är allmänt tillgängliga. från de första 8-bitarsprocessorerna till de mest komplexa som finns idag
Visualisering av instruktionscykeln
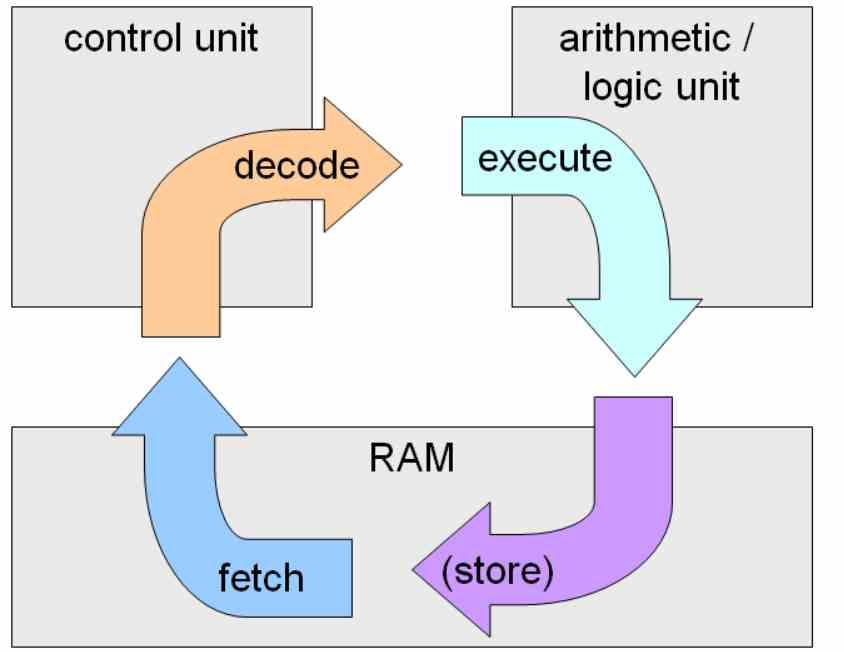
Processorer skiljer sig inte från en viss synpunkt till en förbränningsmotor, som alltid utför en kontinuerlig process för bränsleexplosion i olika steg, oavsett om de är tvåtakts eller 2-takts. Anledningen till detta är att processorerna arbetar i tre olika steg i sin enklaste version, vilka är följande:
- Hämta eller fånga: I vilken instruktionen fångas från RAM och kopieras till processorn.
- Avkoda eller avkoda: I vilken den tidigare fångade instruktionen avkodas och skickas till exekveringsenheterna
- Kör: Där instruktionen löses och resultatet skrivs i processorns interna register eller i en minnesadress på RAM
Dessa tre steg uppfylls i varje processor. Det finns ett fjärde steg, det vill säga återskrivning, det vill säga när exekveringsenheterna skriver resultatet, men detta räknas vanligtvis inom körningsstadiet för instruktionscykeln.
Första steget i instruktionscykeln: Hämta
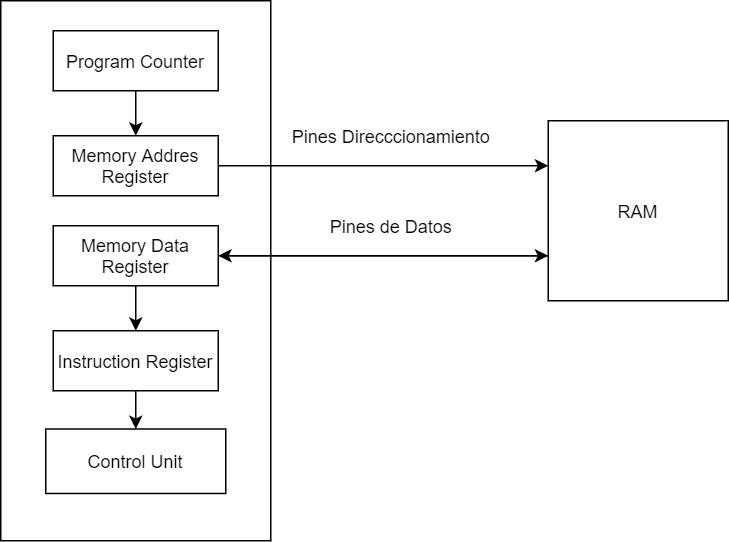
Det första steget i instruktionscykeln ansvarar för att fånga instruktionerna i RAM minne som tilldelats processorn genom en serie enheter och register som är följande:
- Programräknare eller programräknare: Som pekar på nästa minnesrad där nästa processorinstruktion finns. Dess värde ökas med 1 varje gång en fullständig instruktionscykel avslutas eller när en hoppinstruktion ändrar värdet på programräknaren.
- Minnesadressregister: MAR kopierar PC: ns innehåll och skickar det till RAM-minnet via CPU: ns adressnålar, som är kopplade till adressminnet på själva RAM-minnet.
- Memory Data Register eller minnesregister : I händelse av att processorn måste utföra en minnesavläsning, är vad MDR gör att kopiera innehållet i minnesadressen till ett internt register i CPU: n, vilket är ett tillfälligt passregister innan dess innehåll kopieras till instruktionsregistret. MDR, till skillnad från MAR, är ansluten till datapinnarna på RAM-minnet och inte till adresspinnarna och i fallet med en skrivinstruktion skrivs även innehållet i vad du vill skriva i RAM-minnet i MDR
- Instruktionsregister: Den sista delen av hämtningssteget är skrivningen av instruktionen i instruktionsregistret, från vilken processorstyrenheten kommer att kopiera sitt innehåll under det andra steget i instruktionscykeln.
Dessa fyra delsteg förekommer i alla processorer oavsett deras nytta, arkitektur och binära kompatibilitet eller vad vi kallar ISA.
Styrenhet
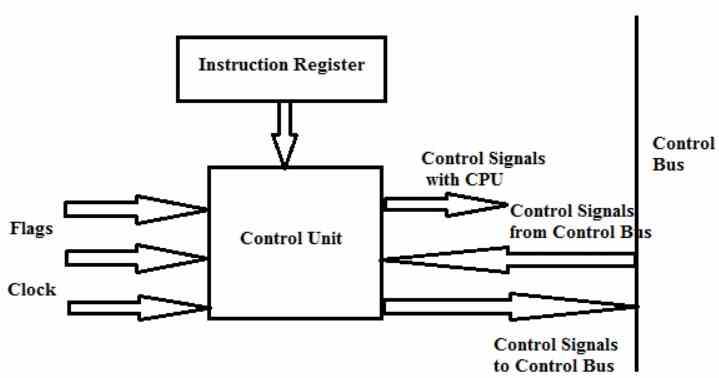
Styrenheten är den mest komplexa delen som finns i en processor och dess uppgifter är följande:
- De ansvarar för att samordna rörelsen och ordningen i vilken data som rör sig inuti och utanför processorn, liksom de olika underenheter som ansvarar för den.
- I allmänhet anses det att enheterna i fångsteget eller Fetch är en del av hårdvaran som vi kallar styrenheten och den här hårdvaran kallas också Front-End för en processor.
- Den tolkar instruktionerna och skickar dem till de olika exekveringsenheterna som den är ansluten till.
- Den kommuniceras till de olika ALU: erna och exekveringsenheterna hos processorn som agerar
- Det är ansvarigt för att fånga och avkoda instruktionerna, men också för att skriva resultaten i registren, cacheminnet eller i motsvarande adress på RAM-minnet.

Vad styrenheten gör är att avkoda instruktionerna och det gör det eftersom varje instruktion faktiskt är en slags mening där verbet går först och sedan det direkta objektet eller objektet som åtgärden görs på. Ämnet slutar elimineras i detta interna språk på datorer av det faktum att det är underförstått att det är själva datorn som kör den, så varje antal bitar är en mening där de första 1 och 0 motsvarar åtgärden och de som kommer nästa är data eller plats för de data som ska manipuleras.
Det andra steget: Avkoda
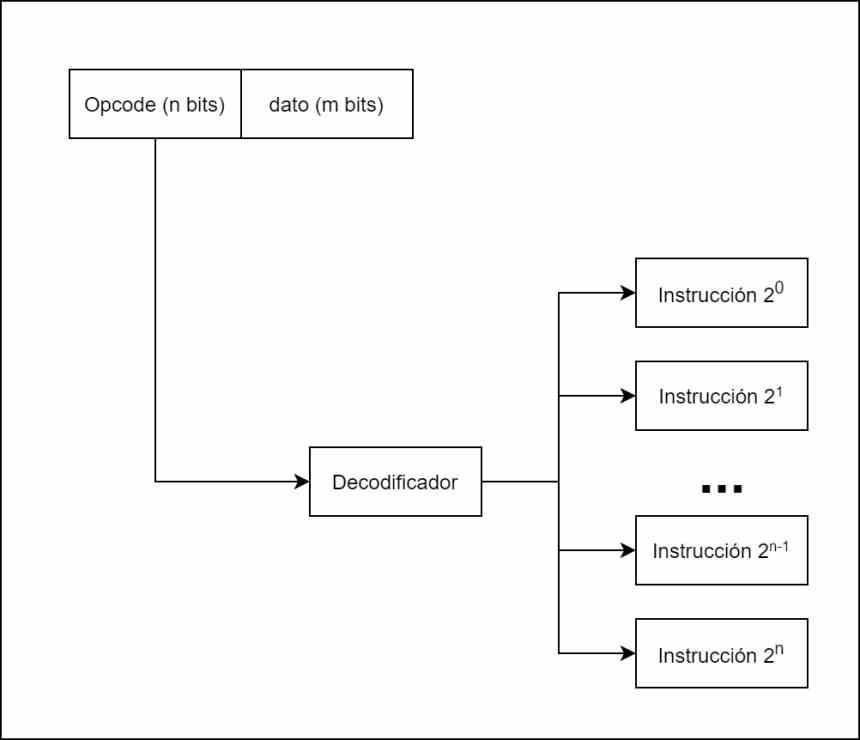
Det finns olika typer av instruktioner och inte alla gör detsamma, så beroende på vilken typ av instruktion vi behöver veta vilka exekveringsenheter som ska skickas till och det mest klassiska sättet att göra det är genom det vi kallar en avkodare , som tar varje instruktion, delar den internt enligt opkoden eller instruktionen och data- eller minnesadressen där den finns.
Till exempel i diagrammet ovan har vi diagrammet för en processor med endast 8 instruktioner, som kan kodas i endast 3 bitar. Var och en av instruktionerna, när de avkodats, skickas till de olika exekveringsenheterna som kommer att lösa dem.
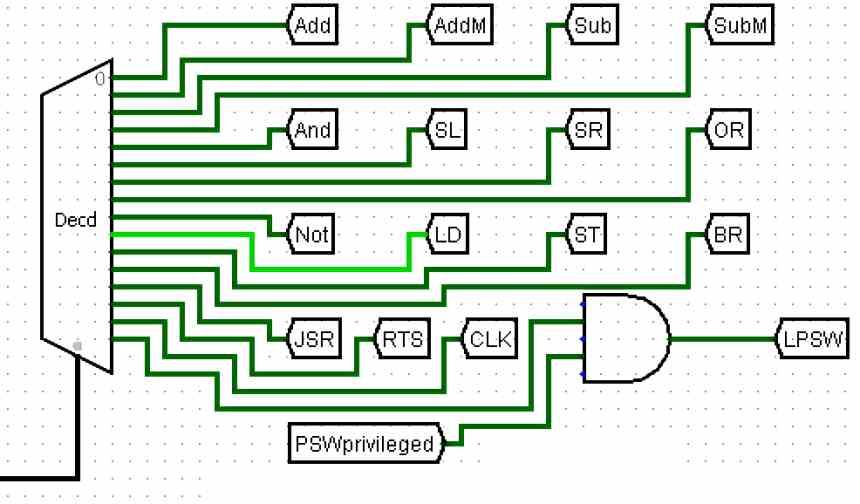

Denna instruktionscykel är den mest komplexa av alla och den som definierar typen av arkitektur. Beroende på om vi har en reducerad eller komplex instruktion kommer detta att påverka styrenhetens natur, beroende på instruktionens format eller hur många som behandlas samtidigt avkodningsfasen och därför kommer styrenheten att ha en olika natur. Övrig.
Det enklaste sättet att visualisera vad som händer är att tänka på instruktionerna som tåg som cirkulerar genom ett komplext järnvägsnät och styrenheten som leder dem till en terminalstation, som är den exekveringsenhet som kommer att ansvara för att lösa instruktionen.
Tredje etappen: Kör
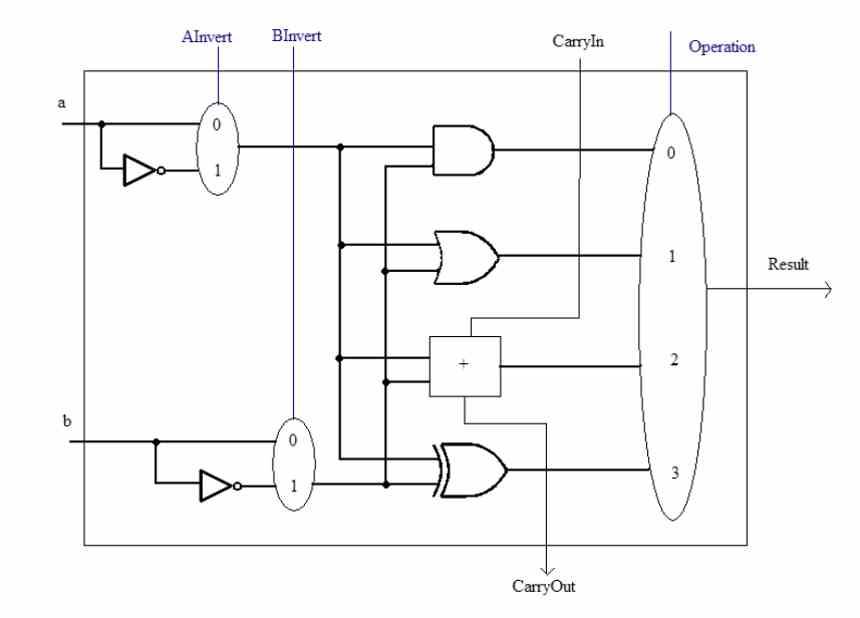
Det sista steget är utförandet av instruktionerna, i det här steget löses instruktionerna, men inte alla typer av instruktioner löses på samma sätt, eftersom sättet att använda hårdvaran beror på funktionen hos var och en av dem. dem, i allmänhet har vi fyra typer av instruktioner:
- Instruktioner för bitrörelse: I vilken ordning på bitarna som innehåller data manipuleras.
- Aritmetiska instruktioner: Där matematiska och logiska operationer utförs löses dessa i så kallade ALU eller aritmetisk-logiska enheter
- Hoppinstruktioner: I vilket nästa värde för programräknaren ändras, vilket gör att koden kan användas rekursivt.
- Instruktioner till minne: De är med vilka processorn läser och skriver information från systemminnet.
Den andra punkten är instruktionsformaten, eftersom en instruktion kan tillämpas på en data, skalar eller flera data samtidigt, vilket vi känner som SIMD. För att avsluta och beroende på dataformat finns det olika typer av ALU: er för utförande av aritmetiska instruktioner, till exempel har vi heltal och flytpunkter som differentierade enheter idag.
När instruktionen har slutförts skrivs resultatet till en specifik minnesadress och nästa körs. Vissa instruktioner manipulerar inte minnesvärden utan snarare vissa register. Således modifieras programräknarregistret av hoppinstruktionerna, om vi vill läsa eller skriva data manipuleras MAR- och MDR-registren.