Att öka IPC eller instruktioner per cykel är en av utmaningarna för alla CPU tillverkare när man utformar allt mer kraftfulla arkitekturer. I den här artikeln kommer vi att berätta vad den senaste tekniken används av ingenjörer som arbetar med att utveckla de senaste processorerna för att öka IPC och därmed processorns prestanda.
I processorarkitekturernas historia har vi sett hur olika koncept har implementerats för att öka deras prestanda. Tillvägagångssätt som segmentering, superscalar-processorer, exekvering utan order etc. Alla har tjänat till att få allt snabbare processorer och med högre prestanda per klockcykel.

Begreppet hybridkärnor är ytterligare ett steg för att uppnå högre prestanda, det bygger på kombinationen i en enda kärna av två typer av kärnor, en optimerad för komplexa instruktioner och den andra för enklare instruktioner, men på ett sådant sätt att de delar gemensam hårdvara och arbeta tillsammans som om de vore en enda CPU-kärna.
Begreppet hybridkärnor för att öka KPI

I en CPU är inte alla instruktioner lika komplexa, vissa av dem kräver ett större antal klockcykler för att slutföra, medan andra kräver mycket få klockcykler för att slutföra eftersom de är mycket enklare. Vid utformningen av nya processorer var trenden hittills att optimera de mest komplexa instruktionerna när det gäller antalet cykler.
Men oavsett vilken typ av instruktion som utförs av kärnorna i vår CPU, använder de alla samma komponenter under instruktionscykeln, vilket innebär att de enklaste instruktionerna inte kan optimeras på energiförbrukningsnivån. som inte skulle ha lägre prestanda i en binär kompatibel CPU utan med lägre förbrukning.
Idén reduceras till det faktum att en processor har två typer av exekveringsenheter, vissa optimerade för att utföra de mest komplexa instruktionerna och den andra för det enklaste, detta möjliggör optimering av förbrukningen av de olika instruktionerna.
En idé från världen av GPU: er
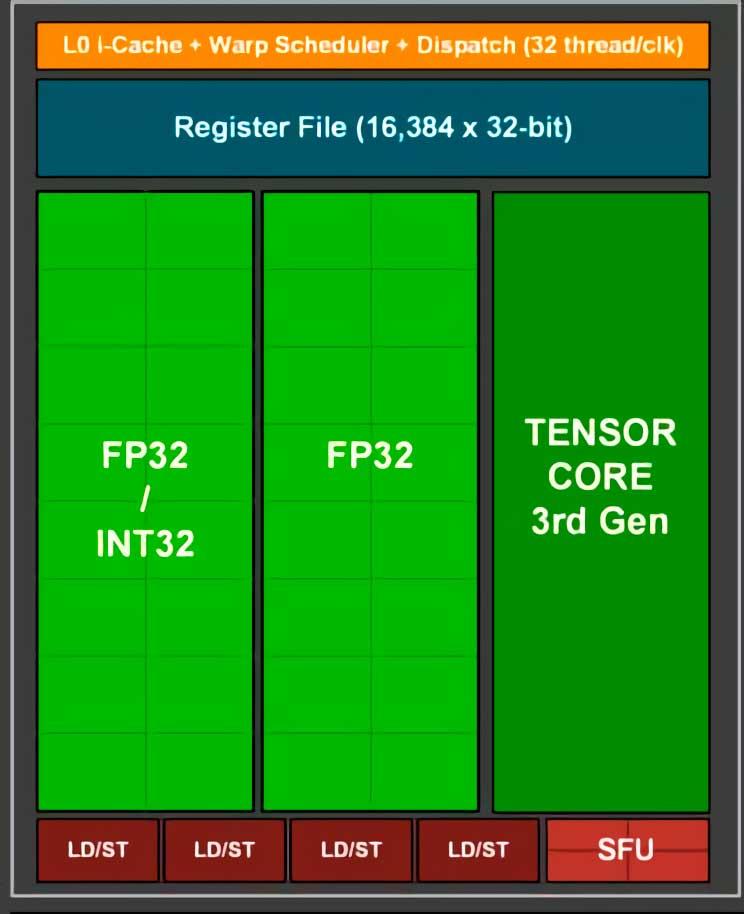
RTX 3000 SM Subcore
I GPU: erna har vi två olika typer av ALU: er, å ena sidan har vi SIMD-enheterna, till exempel CUDA-kärnorna, vilka tillverkare vanligtvis främjar för att prata om TFLOPS-hastigheten, dessa enheter är ansvariga för utförandet av extremt enkla instruktioner , men å andra sidan har vi SFU: er som är ALU: er med en lägre beräkningshastighet, eftersom de är optimerade för mer komplexa instruktioner
Tja, SFU skulle förbruka mycket mer kraft för att utföra en enkel instruktion än SIMD-enheter, därav separationen som gjordes för flera år sedan i båda NVIDIA och AMD GPU: er. När styrenheten eller schemaläggaren för C0mpute-enheten upptäcker en instruktion som SFU: erna kan utföra, kopierar den helt enkelt instruktionsraden och skickar den direkt till en av SFU: erna som är fria för körning.
Implementering av hybridkärnor för att öka IPC

Konceptet i en CPU är inte annorlunda, instruktionshämtningsfasen skulle vara nästan densamma i båda processorerna, så båda processorerna skulle dela programräknaren som pekar på nästa instruktion, det skulle vara i slutet av hämtningsfasen där läsningen i instruktionsregistret där instruktionen skulle skickas till en eller annan typ av kärna för körning.
Detta innebär att båda kärnorna faktiskt skulle vara som siamesiska tvillingar som delar en del av hårdvaran genom att dela ett av steget i instruktionscykeln, men eftersom instruktionerna skulle avkodas och köras i den separata delen av båda kärnorna gör inte bara IPC ökning av betydelsen av antalet samtidiga instruktioner per klockcykel, men det förhindrar också att vissa instruktioner strider mot användningen av resurser.
En annan av de saker som denna ändring tillåter att göra har att göra med hanteringen av instruktioner som når processorn, vilket är förfrågningar från kringutrustning som stoppar exekveringen av koden. Du kan göra kärnan optimerad för enkla instruktioner hantera dem utan att den andra behöver sluta.
Dess effekter på CPU-rörledningen
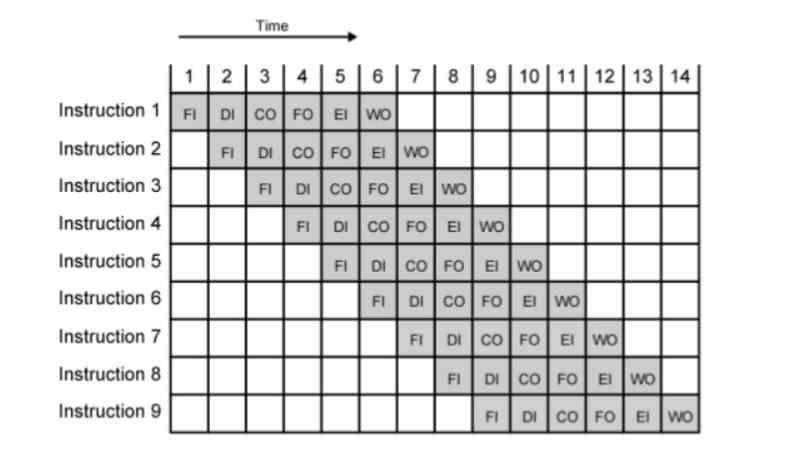
Vi måste förstå att numera är alla processorer segmenterade i flera steg, på ett sådant sätt att om vi har n-instruktionen i ett specifikt steg, så kommer n + 1-instruktionen att vara i föregående steg och n-1 i nästa .
Den inversa av tiden är alltid frekvensen (1 / tid = frekvens), så tricket att öka klockhastigheten är att få vart och ett av stegen att vara mindre, så vanligtvis är det du gör att öka antalet steg, med målet att varje nytt steg varar mindre och frekvensen eller klockcyklerna är högre.
Uppenbarligen är det perfekt att uppdela en komplex instruktion i ett större antal instruktionscykler för att uppnå höga klockhastigheter. Men hur är det med samma enkla? Det är en huvudvärk för arkitekter att bryta upp ännu enklare instruktioner än de redan är idag.
Skillnader i hybridkärnor med big.LITTLE

I en big.LITTLE-processor är de "stora" kärnorna separerade från "LITTLE" -kärnorna i den meningen att de fungerar på ett omkopplat sätt i förhållande till varandra, så det är applikationen som gör en begäran till operativsystemet till det en grupp kärnor eller en annan är påslagen.
Operationen för denna typ av kärna är att när de får ett specifikt avbrott så avslutar de den nuvarande och vittnar om den andra typen. Detta inträffar när arbetsbelastningen på systemet är mycket hög eller vissa villkor är uppfyllda. I vilket fall som helst måste det tas med i beräkningen att i den stora LITTLE-metoden är varje uppsättning kärnor komplett och helt oberoende.
I begreppet hybrid ALU: er har vi inte helt separata kärnor utan de delar fångningsfasen såväl som tillgång till både cachehierarkin och minnet. Dessutom inaktiverar den ena inte när den andra arbetar just för att de delar hårdvaran för minnesåtkomst och vi kan inte glömma heller det stora.LITTLE ökar inte kärnans IPC.
Varför ökar hybridkärnor IPC: n för processorer?

Anledningen är enkel, faktumet att ha ett större antal exekveringsenheter, liksom att hårdvaran i avkodningssteget inte delas, orsakar att det inte finns något som kallas strid, detta inträffar när två eller flera instruktioner de kämpar över en enda resurs, på ett sådant sätt att den ena måste vänta tills den andra är klar.
Varför är inte processorer utformade utan det problemet? Design kan utformas, men budgeten för transistorer är begränsad och det är därför arkitekter fuskar genom att sätta gemensamma punkter längs vägen. Många av de mindre uppdateringarna av en arkitektur är vanligtvis baserade på att undvika denna typ av strid genom att lägga till fler interna banor så att det inte finns någon strid.
IPC som en marknadsföringsperiod är inte längre den mängd samtidiga instruktioner som kärnan i en CPU kan lösa samtidigt under de bästa förhållandena, termen baseras nu på att ta ett riktmärke och titta på genomsnittet av instruktionerna per cykel som det matar ut processorn. Det är därför det är så viktigt att undvika strid mellan instruktionerna och det är därför hybridkärnor med avkodnings- och exekveringssteg separerade efter kärntyp är idealiska för att öka IPC.
Vilken nuvarande CPU använder hybridkärnor för att öka IPC?

Det direkta svaret är ett rungande NEJ, ingen av processorerna som för närvarande finns på marknaden eller som kommer att komma ut på kort sikt kommer att använda hybridkärnor, men de kommer att baseras mer på det stora.LITTLE-konceptet där kärnorna som används kommer att vara den ena eller den andra beroende på situationen, vilket kommer att hända särskilt i IntelGen 12 som släpps om några månader.
Den som vi vet, genom ledtrådar i olika patent som publicerades under det senaste året, att den kommer att välja en hybridkärnans strategi är AMD, vi vet inte om vi står inför Zen 4 eller Zen 5. Vilket betyder inte att Intel och till och med andra CPU-designers gillar Apple inte redan implementerar dessa lösningar.
Orsaken till det? Att höja KPI kan inte göras för alltid och det blir mer och mer komplicerat att genomföra, därav behovet av att använda tekniker som hybridkärnor för att öka det.