En av begränsningarna som grafiska kort på stationära och bärbara datorer har är oförmågan att köra flera operativsystem samtidigt eller virtuella maskiner. Denna differentiering som vissa GPU: er har kallas virtualisering och i den här artikeln ska vi förklara vad det är och vilka förändringar det kräver i hårdvaran.
Innan persondatorn anlände arbetade människor i terminaler anslutna till en central minidator, som hade ansvaret för att utföra alla uppgifter. Med tillkomsten av molnbearbetning som kör olika operativsystem i virtuella maskiner är virtualisering inte bara nödvändig på processorer utan också på GPU: er.

Varför är virtualisering nödvändig på GPU: er?
Virtualisering är maskinvarans förmåga att skapa flera versioner av sig själv så att den kan användas av flera virtuella maskiner. Till exempel en del av en CPU som har virtualiserats kommer att ses av ett operativsystem som körs i en virtuell maskin, medan andra virtuella maskiner kommer att se andra delar av CPU: n som en enda och distinkt CPU. I så fall har vi virtualiserat CPU: n, eftersom vi har skapat en virtuell version av varje operativsystem som körs på systemet.
När det gäller grafikprocessorer skrivs kommandolistorna för grafik och datorer i vissa delar av minnet i synnerhet och i allmänhet är de grafikprocessorer som vi monterar i våra datorer utformade för att fungera i ett enda operativsystem utan någon virtuell maskin däremellan. .
Detta är inte fallet med grafikkort för datacenter, där flera olika instanser, virtuella maskiner, i ett operativsystem vanligtvis körs och det är nödvändigt för varje klient att komma åt GPU. Det är i detta fall där virtualisering i GPU: er är nödvändig
Virtualisering från GPU-sidan

GPU: er behöver också ändringar på hårdvarunivå för att stödja virtualisering. På grund av detta säljs vanligtvis endast grafikkort med denna kapacitet till marknader långt från stationära datorer och har därför ett mycket högre pris än stationära GPU: er. Idag kan du hyra kraften i en GPU i molnet för att påskynda vissa vetenskapliga verk, återge en scen på distans för en film eller en serie, och så vidare.
SR-IOV
Varje PCI Express-kringutrustning har en unik minnesadress på varje dators minneskarta. Vad betyder att om vi använder en virtualiserad miljö kan vi inte komma åt hårdvaran som är ansluten till dessa portar, t.ex. grafikkort många gånger. Vanligtvis har de virtuella maskinerna som vi kör på stationära datorer inte förmågan att använda grafikkortet, vilket bara är tillgängligt för gästoperativsystemet.
Lösningen på detta är SR-IOV, som virtualiserar PCI Express-porten och låter flera virtuella maskiner få åtkomst till dessa minnesadresser samtidigt. I PC: n görs perifer kommunikation via samtal till vissa minnesadresser. Även om dessa samtal idag inte motsvarar fysiska minnesadresser, utan virtuella, är den okränkbara regeln att innehållet i en minnesadress inte kan manipuleras av två klienter samtidigt, eftersom det då finns konflikter om innehållet i data.
SR-IOV för att fungera behöver en nätverkskontroll integrerad i PCI Express-enheten, om vi har att göra med grafikkortet, som tar emot förfrågningar från olika virtuella maskiner som behöver tillgång till sina resurser.
Ändringar av DMA-enheter för GPU-virtualisering
Den första ändringen sker i DMA-enheterna, dessa enheter kommer vanligtvis i par i GPU: erna som vi använder på datorer och ger tillgång till RAM av systemet, inte att förväxla med VRAM, genom en alternativ kanal. Vid varje ram måste GPU: n ha åtkomst för att läsa skärmlistan i en del av RAM-minnet eller så måste den kopiera data från RAM-minnet till VRAM om det behövs data senare. Detta använder en DMA-enhet i varje riktning. När det gäller GPU: er med virtualisering? De använder flera DMA-enheter parallellt eller en DMA-enhet med flera samtidiga åtkomstkanaler .
Användningen av de olika kanalerna av de virtuella GPU: erna hanteras av den integrerade nätverkskontrollen, som ansvarar för att hantera förfrågningar till RAM, antingen fysiskt eller till en annan kringutrustning som också är ansluten till PCI Express-porten. Så om de olika virtuella GPU: erna måste ha åtkomst till exempel en SSD disk, gör de det via DMA-enheterna.
GPU-kommandoprocessorändringar
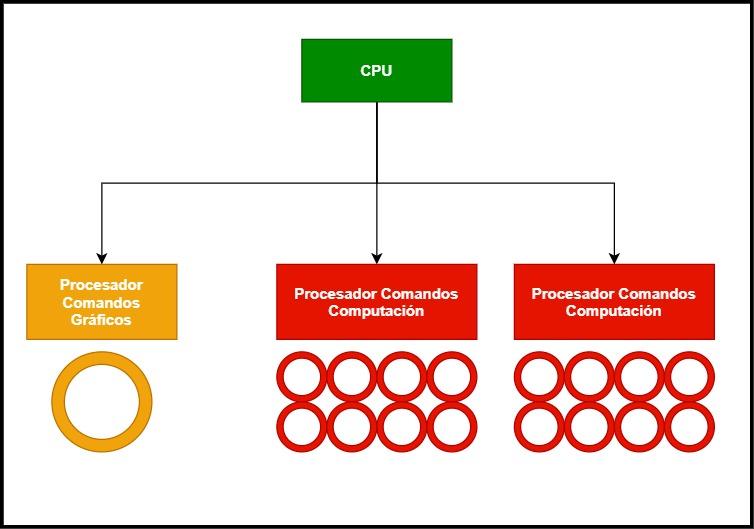
Den andra ändringen är i kommandoprocessorn. Alla grafikprocessorer för beräkning utan grafik i mitten är vana vid att arbeta i flera sammanhang samtidigt, detta beror på att de är väldigt små kommandolistor som löses på kort tid, å andra sidan om vi pratar om grafik det som det är ändras helt, eftersom en enda lista med kommandon vanligtvis används.
Vad sägs om icke-virtualiserade GPU: er som använder flera skärmar? Det är inte detsamma som att använda flera operativsystem i virtuella maskiner, eftersom skärmlistan i dessa fall kommer från ett enda operativsystem som till GPU: n visar videoutgången genom vilken varje bild måste sändas.
Därför är det nödvändigt att implementera en speciell grafisk kommandoprocessor, som fungerar tillsammans med DMA-enheterna och den integrerade nätverkskontrollen för att fungera inte som en GPU utan som flera olika och virtuella.
GPU-resurser distribueras i virtualisering
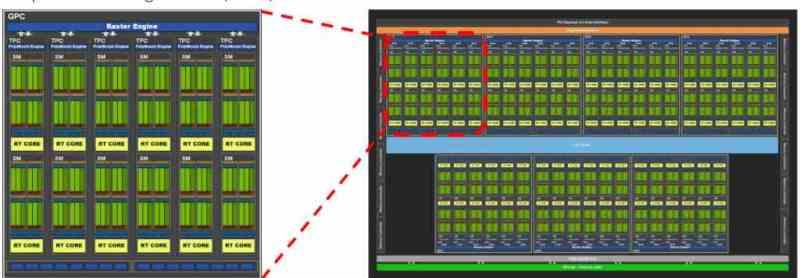
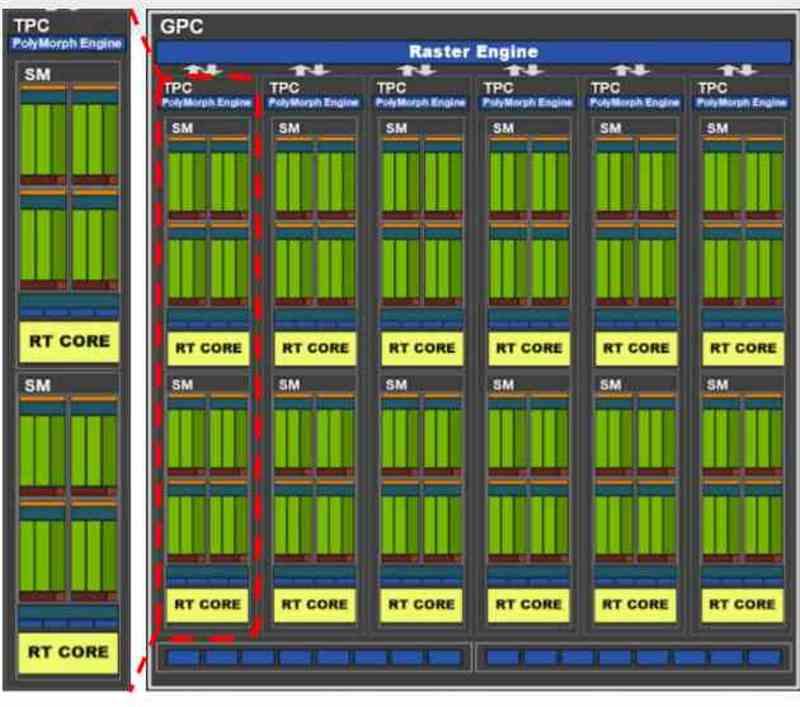
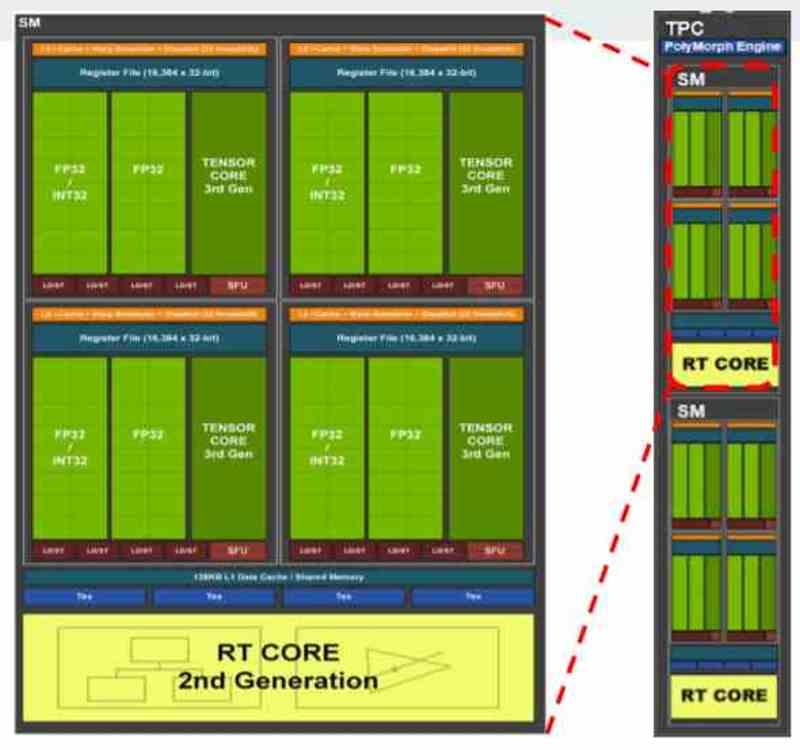
Alla samtida grafikkort är vanligtvis uppdelade i flera block inom andra block, till exempel om vi tar GA102 från NVIDIA RTX 3080 eller 3090 ser vi att den ursprungligen består av flera GPC: er, inom vilka det finns flera TPC: er och i varje TPC har vi 2 SM.
Beroende på hur fördelningen av resurser har föreslagits av tillverkaren kan vi hitta en distribution där varje virtuell maskin motsvarar en GPC, så när det gäller GA102 skulle vi prata om en virtualisering av GPU i 7 olika. Även om det också skulle vara möjligt att göra det på TPC-nivå kan i så fall upp till 36 virtuella maskiner skapas, men som vi förstår skulle kraften för var och en vara väldigt annorlunda.
I GPU: erna är det som tilldelats i NVIDIA en komplett GPC eller vad i AMD är känd som Shader Engine, eftersom var och en av dessa delar har alla nödvändiga komponenter för att fungera som en GPU i sig. I de fall där den virtualiserade GPU inte används för rendering utan för datorer, är distributionen på TPC-nivå eller motsvarande i AMD RDNA, WGP.