AMDRadeon-grafikarkitekturer har sett liten förändring de senaste åren jämfört med tävlingen, eftersom GCN lanserades 2012 flyttade vi till RDNA 2019, som nyligen har fått en ombyggnad med RDNA. Men vad har egentligen varit utvecklingen av AMD GPU: er? Läs vidare för att lära dig mer om arkitekturförändringarna från GCN till RDNA 2.
Medan NVIDIA har haft många olika GPU arkitekturer under de senaste åren, är AMD traditionellt mer konservativ och upprätthåller samma GPU-arkitektur med mindre justeringar i flera år. Vi såg det med GCN, som var AMD GPU-arkitekturen i flera generationer och vi ser det med RDNA, där färdplanerna redan indikerar att det finns en framtida RDNA 3 med färre förändringar än de som vi ska se i NVIDIA Lovelace. och Hopper.


Men vi ska inte se på framtiden som Prometheus, utan att vara mer av Epimetheus och se både till det förflutna och nuet och vi kommer att göra det i fallet AMD för att verkligen veta hur AMDs olika arkitekturer har utvecklats. Jämförelsen sker därför inte på generationsnivå eller mellan grafikkort emellan, utan för att förstå hur utvecklingen från GCN till RDNA 2 har gått.
Utvecklingen från GCN till RDNA
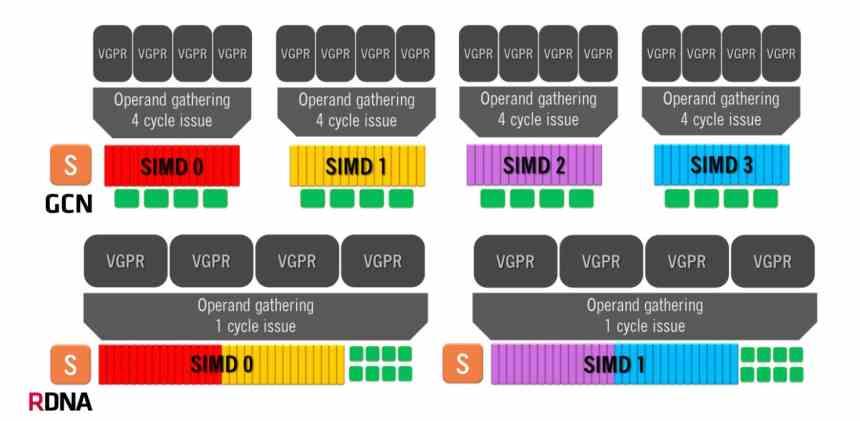
Graphics Compute Next-arkitekturen använder en Compute Unit som består av fyra SIMD-grupper om 4 ALU vardera, som hanterar vågor med 16 element. Detta innebär att i bästa fall, där en instruktion löses per cykel, kommer GCN-arkitekturen att ta fyra klockcykler per 64-elementvåg.
Å andra sidan har RDNA-arkitekturer en annan funktion, eftersom vi har två grupper på 32 ALU och vågarnas storlek har gått från 64 element till 32 element. Samma storlek som NVIDIA använder i sina GPU: er, så nu är den minsta tiden per våg en enda cykel eftersom vi har alla 1 exekveringsenheter som körs parallellt. Även om det genomsnittliga antalet instruktioner som lösts fortfarande är 32 är det en mycket effektivare organisation.
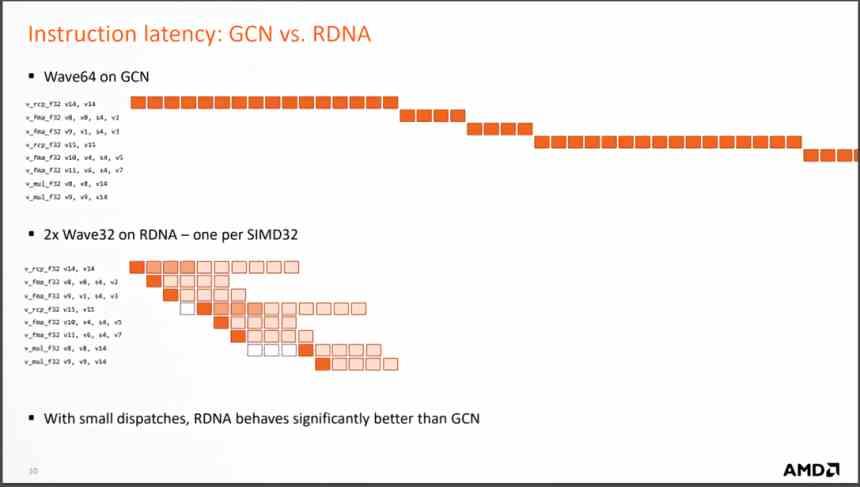
Men den viktigaste förändringen är förändringen när man utför instruktionerna som kommer från varje våg, eftersom RDNA löser dem på mycket färre cykler, vilket innebär att det genomsnittliga antalet instruktioner per cykel som löses är mycket större. och med det ökar den genomsnittliga KPI.
Vad översätter detta till? Eftersom mycket färre beräkningsenheter krävs för att uppnå samma prestanda, betyder färre beräkningsenheter en mindre GPU för att uppnå samma prestanda. Egentligen började AMD göra RDNA-designen så snart de såg en GTX 1080 med "bara" 40 SM som svepte golvet med AMD Vega 64 Compute Units. Det var då de såg hur GCN-arkitekturen inte gav mer av sig själv.
Cache-systemets utveckling

För att förstå utvecklingen från en grafisk arkitektur till en annan är det viktigt att känna till cachesystemet och hur det har utvecklats från en generation till en annan.
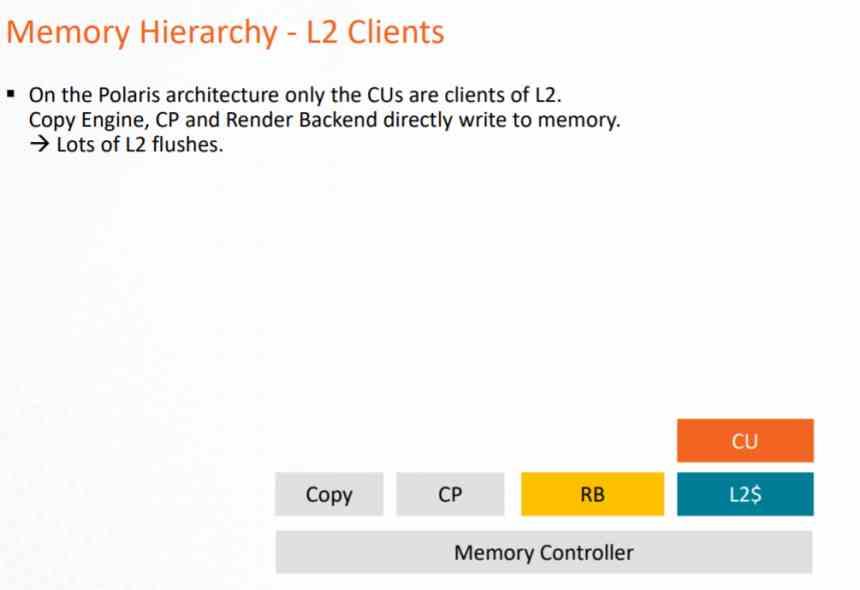
I GCN-arkitekturen kunde cachesystemet endast användas av datorrörledningen, eftersom Pixel Shaders när de körs exporterar till ROPS och dessa direkt på VRAM, vilket förutsätter en mycket stor belastning på VRAM och en förbrukning av mycket stor energi .

Detta problem löstes i slutet av arkitekturen med AMD Vega, där både ROPS och rasterenheten kommunicerade till L2-cachen för att minska belastningen på databussen mot VRAM. Men speciellt för att tillämpa DSBR eller Tiled Caching, som består av att anta Tile Rendering, men delvis och som NVIDIA redan hade antagit i Maxwell.

I RDNA var den viktigaste förändringen att få allt att bli L2-klient, men att lägga till en mellanliggande cache som är L1, på detta sätt ändrades nomenklaturen.
- L1-cache som ingår i Compute Units blir L0-cache med samma funktionalitet.
- En L1-cache läggs till, vilken är mellanliggande mellan L0-cachen och L2-cachen.
- Alla GPU-element går nu igenom L2-cachen.
Alla skrivoperationer utförs direkt på L2-cachen, medan L1-cache är skrivskyddad. Detta görs för att undvika att implementera ett mer komplext koherenssystem på GPU: n som skulle uppta ett stort antal transistorer. Eftersom tack vare den skrivskyddade L1-cachen kan du bevilja data till flera klienter inom GPU samtidigt.
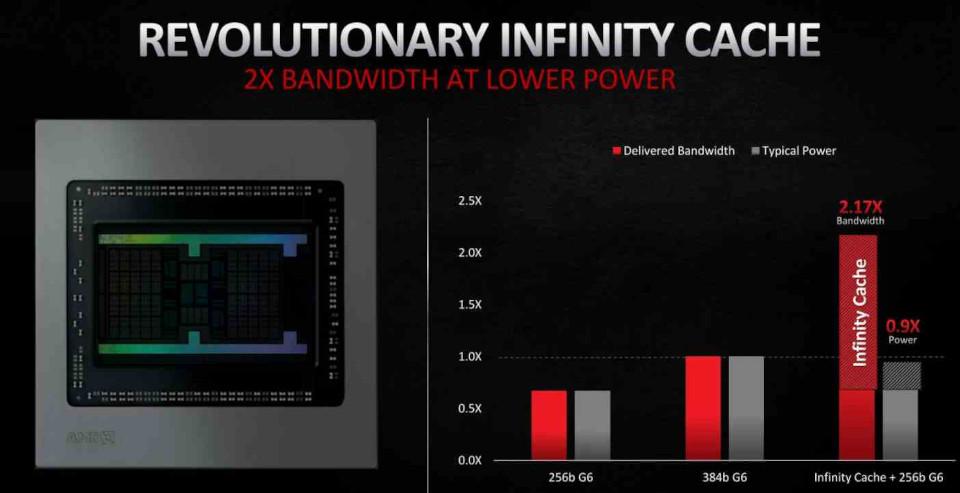
I RDNA 2 har den viktigaste inkluderingen varit i form av Infinity cache, som inte fungerar som en konventionell L3-cache utan som ett offercache, antar cachelinjer som kasseras av L2-cache, på detta sätt undviks att dessa data faller in i VRAM, vilket underlättar dess återhämtning och, som vi kommer att se senare , det minskar energikostnaden för vissa operationer, vilket gör det till ett nyckelelement för förbättringar i RDNA 2.
Placeringen av data är viktig med avseende på energiförbrukning. Eftersom ju större avstånd en datadel har att resa, desto större är energiförbrukningen. Det är där Infinity Cache kommer in, vilket gör att du kan hantera data med en mycket lägre förbrukning.
RDNA 2, en mindre utveckling

RDNA 2, å andra sidan, är en något förbättrad version av RDNA och inte en mindre radikal förändring, så AMD skulle ha återvänt till strategin att lansera kontinuerliga förbättringar av samma arkitektur. AMD sägs ha släppt RDNA under andra halvan av 2019 som en tillfällig lösning medan de avslutade poleringen av RDNA 2, som är den redan färdiga versionen av arkitekturen och helt kompatibel med DirectX 12 Ultimate.
Om vi talar i termer av beräkning har RDNA 2 ingen fördel jämfört med RDNA och förbättringarna har gjorts snarare i andra delar än den del som ansvarar för att köra skuggorna.
- Texturenheten har förbättrats och en strålkorsningsenhet har lagts till för Ray Tracing.
- ROPS och rasterenheter har förbättrats för att stödja Variable Rate Shading.
- GPU stöder nu högre klockhastigheter.
- Inkludering av Infinity Cache för att minska energiförbrukningen i vissa instruktioner.
En av nycklarna för att kunna uppnå en högre klockhastighet i en processor är att supersegmentera rörledningen, men det här är något som inte kan göras i en GPU: s skuggningsenhet på samma sätt som i en CPU. För vad AMD har gjort internt är att mäta energiförbrukningen för varje instruktion som Compute Unit kan utföra. Eftersom det finns instruktioner som förbrukar mindre energi kan de köras med högre klockhastighet, vilket gör att man når högre topphastigheter vid den tiden för att utföra dem.