Ray-spårning är en algoritm för återgivning av scener som har använts i stor utsträckning i offline-animationsvärlden men som i realtidsmiljöer som videospel är nu när det börjar dyka upp. I den här artikeln kommer vi att prata om tidigare, nuvarande och framtida utveckling av hårdvara om strålningspåverkan så att du kan få en uppfattning om vad vi kan förvänta oss.
Som med rasterisering, där det ursprungligen bara var möjligt på superdatorer, sedan på arbetsstationer och senare på hemdatorer med 3D-kort, har raytracing eller känt under sitt engelska namn "Ray Tracing" haft samma utveckling och vad år sedan bara var möjligt med mycket kraftfulla och dyra system blir alltmer tillgängliga för alla.

Utvecklingen av hårdvara med avseende på Ray Tracing

Det är därför vi har beslutat att göra ett retrospektiv för att visa utvecklingen av hårdvaran vad gäller Ray Tracing; Vi har delat upp denna utveckling i fem olika stadier, och i dem kommer vi inte bara att prata om de förflutna metoderna utan också om de metoder som vi kommer att se inom en snar framtid och som därför kommer att implementeras i framtida generationer av GPU: erna. som kommer att utrusta våra datorer.
Steg 1: Rendering via CPU

Det måste tas med i beräkningen att grafikprocessorer under lång tid var knutna till rasteriseringsalgoritmen, så de var inte lämpliga för att rendera scener baserat på Ray Tracing, som använder en annan algoritm.
Lösningen som fanns för när du ville återge en scen via strålspårning? Att dra flera kärnprocessorer och även om detta redan är en del av historien var det tillvägagångssättet Intel ville köra med sin avbrutna och misslyckade Larrabee för drygt ett decennium sedan, vilket inte var mer än flera x86-kärnor i en konfiguration som mycket liknade en GPU.

Denna lösning visar sig vara den mest ineffektiva eftersom processorer är skalära system som är utformade för att fungera med en enda uppgift per körningstråd och jämfört med en GPU har de väldigt få trådar som körs samtidigt, vilket tvingar det att vara nödvändigt att skapa superdatorer på dussintals om inte hundratals processorer för rendering.
Steg 2: Ray Tracing på GPU genom Compute Shaders
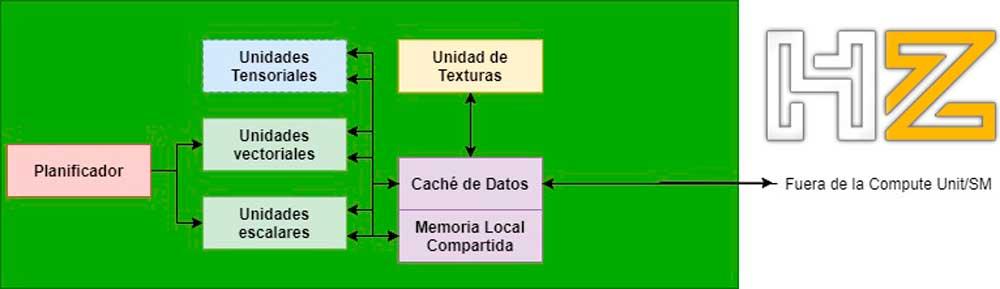
Från och med DirectX i version 11 och OpenGL i version 4 dök upp en ny typ av skuggprogram för GPU: er som heter Compute Shaders, som inte är associerade med ett steg i den grafiska pipelinen.
Tack vare dem kunde GPU: erna helt eller delvis fokusera sin kraft på att lösa problem utöver rasterisering och bland dem var det möjligt att implementera strålspårning i GPU: n, inte i tillräcklig hastighet för att möjliggöra realtidsåtergivning, men ja för att implementera en pipeline av successiva etapper via Compute Shaders.
Men det var inte förrän DirectX 12 att det började vara möjligt att föreslå en komplett rendering pipeline för Ray Tracing där vart och ett av de specifika stadierna är en Compute Shader som utför ett av dessa steg i synnerhet.
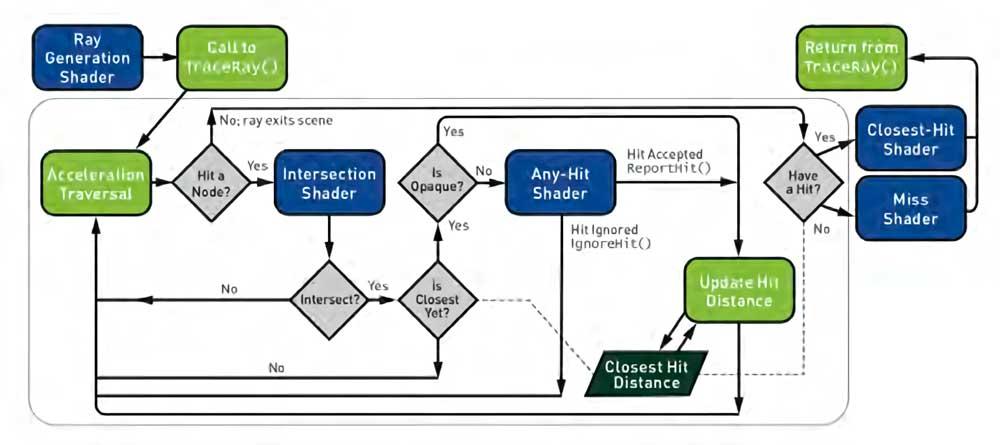
Den här rörledningen är den som slutligen standardiserades från och med 2018 som en förberedelse för DirectX Ray Tracing och senare antogs också av Vulkan; denna tidiga GPU-implementering för strålspårning i realtid var dock inte tillräckligt bra när det gäller prestanda och ändringar krävdes för den klassiska Compute Unit / SM.
Steg 3: korsningsenheter
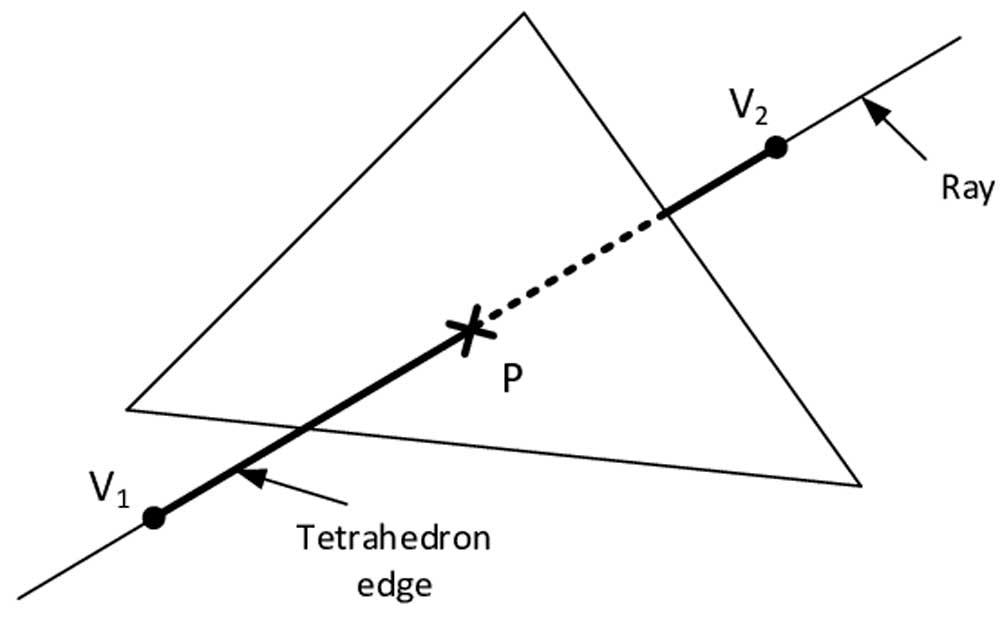
Något som är vanligt i hårdvarudesign är att skapa acceleratorer för att utföra repetitiva och repetitiva uppgifter till en kostnad i området och energi mycket lägre än en hel processor, idén är att ladda ner dessa uppgifter på dessa specialiserade processorer.
Dessa typer av enheter är vanliga i GPU: er. Till exempel, när det gäller rasterisering, hittar vi enheter med en fast funktion som utför operationer som rasteriserande trianglar, filtreringsstrukturer etc. Dessa enheter är anslutna och utför alltid funktionen från de ingångsdata som ges till den och det är varför de kallas fast funktion, eftersom vi inte kan ändra deras funktion, det vill säga de är inte programmerbara. Fördelen med denna typ av enhet är att den gör det möjligt för oss att utföra dessa specifika beräkningar med mycket små enheter, med mycket liten förbrukning och som fungerar helt parallellt.
I strålspårning kommer var och en av strålarna som genereras under scenen att träffa ett eller flera objekt i scenen, så det är nödvändigt att utföra denna beräkning kontinuerligt och upprepade gånger som vi kallar korsning, så det är den typ ideala processen som slutar i form av en specialiserad enhet som arbetar parallellt.
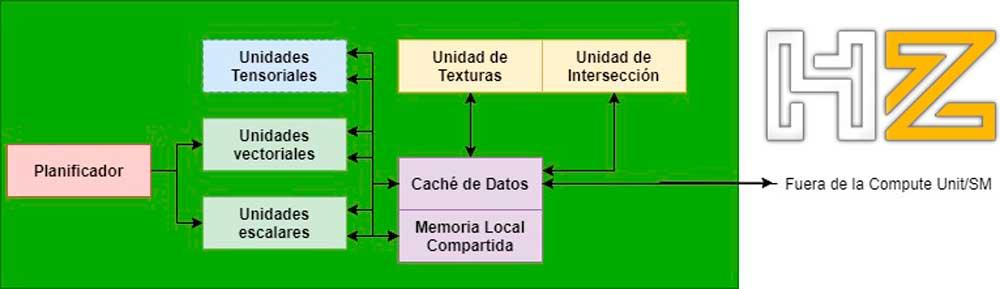
När det gäller korsningsenheterna finns de i GPU: n i beräkningsenheterna / SM: erna i AMD / NVIDIA grafiska enheter (i alla fall pratar vi om samma typ av enhet i båda fallen, men med ett annat namn) och de kommunicerar med ALU: erna som ansvarar för att utföra skuggorna genom datacachen inom samma enhet.
Steg 4: BVH-trädresenheter
BVH är en rumslig datastruktur som lagrar scenens geometri på ett ordnat sätt. För att påskynda processen för beräkning av korsningen är vad som görs att utföra detta på BVH-trädet istället för att göra det pixel för pixel.
Utan de enheter som ansvarar för att korsa BVH-trädet är det nödvändigt att göra det med Compute Shader-programmet, men med dessa enheter implementerade på hårdvarunivå glömmer vi bort att behöva genomföra denna process.
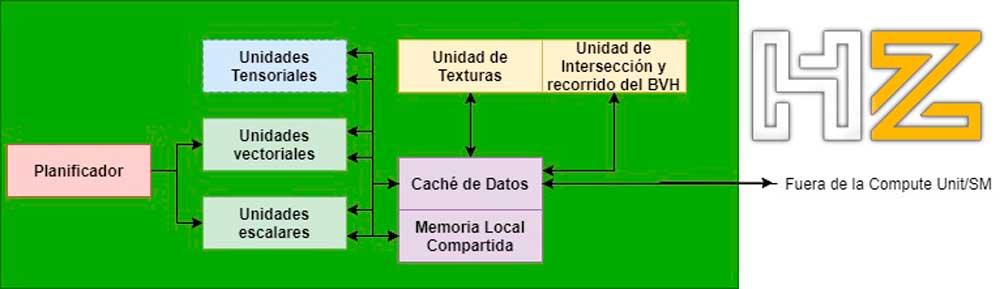
Med andra ord genererar en banenhet alla strålar och deras väg genom BVH-trädet automatiskt utan deltagande av ett skuggprogram och kommer att interagera med korsningsenheten. Båda i slutet av processen skickar tillbaka resultaten.
Det måste tas med i beräkningen att i den nuvarande versionen av DirectX 12 Ultimate är detta inte en del av minimispecifikationen och det är nödvändigt att styra skapandet av nya strålar från skärningspunkten mellan andra och objekt genom Ray Generation Shader. Så användningen av den här enheten är begränsad, eftersom det föredras att ge kraften till spelutvecklarna för tillfället om blixtens densitet i scenen.
Steg 5: Sammanhängande strålspårning
Nästa steg i utvecklingen av GPU: er för Ray Tracing kommer att läggas till en koherensenhet i GPU: n, men först och främst måste vi förstå vad vi menar med minneskoherens ur vilken processor som helst, eftersom detta är visionen om minnet för varje processor är densamma, speciellt för samtida GPU: er.
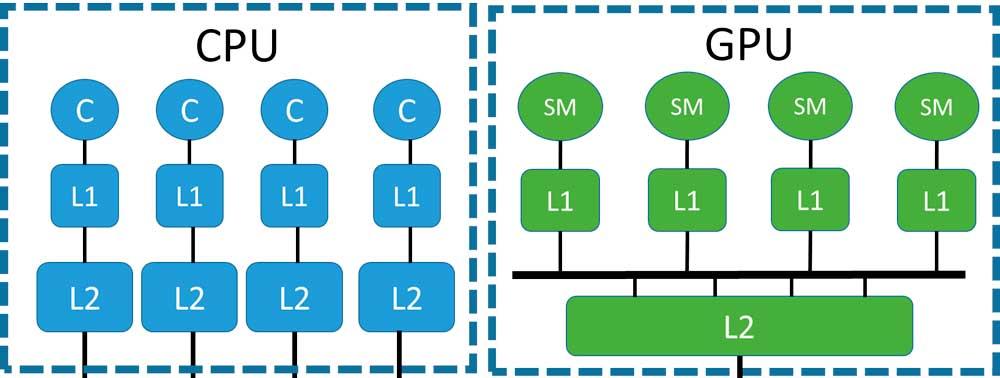
Om vi vill förstå problemet med minneskoherens, måste vi förstå hur cachemekanismen i alla flerprocessorsystem fungerar, oavsett om vi talar om en CPU eller en GPU.
- Cachar är inte RAM i sig utan lagrar snarare specifika delar av RAM eller högre cache-nivåer.
- De lägre nivåerna av cachen och närmast processorerna innehåller kopior av delar av data från de högre nivåerna.
Därför, om vi vill skapa ett sammanhängande system, måste en mekanism skapas att när en kärna eller annan enhet i GPU ändrar värdet på en data, ändras också alla kopior som hänvisar till den informationen i alla cacher i ett sätt samtidigt såväl som i VRAM.
Så vilket problem står GPU: er inför nu? Innan vi har kommenterat att korsningen och genomkörningsenheten för BVH har tillgång till datacachen för beräkningsenheten / SM, men eftersom det inte finns någon konsistensmekanism, när en ändring görs till data i en beräkningsenhet / SM, resten av enheterna är omedvetna om det, och detta leder till att en bra del av korsningen och avståndsberäkningarna upprepas även om de redan har utförts av andra enheter.
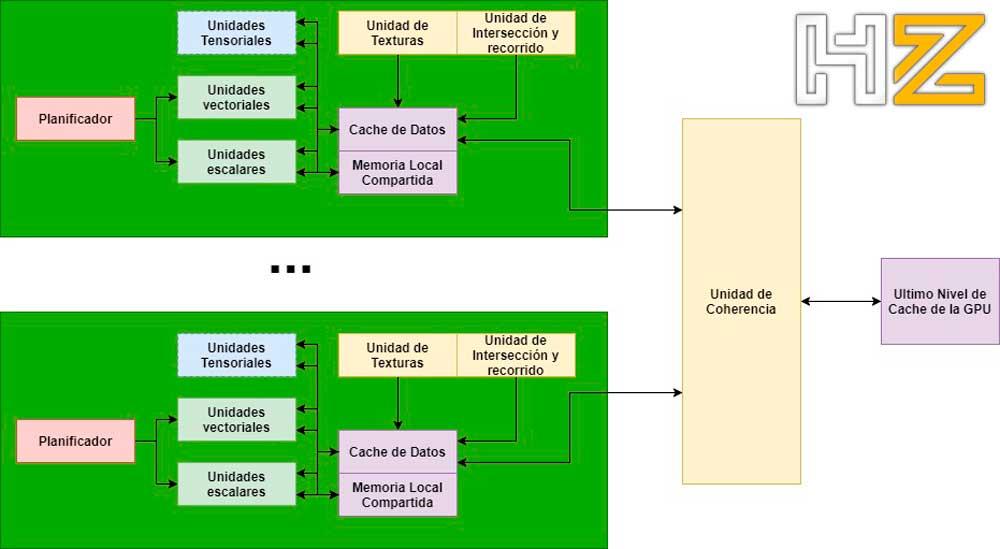
Koherensenheten är en eller flera hårdvaruenheter som ansvarar för att meddela alla beräkningsenheter / SM om förändringar i innehållet i cacheminnet, så det är svårt att implementera hårdvara på grund av mängden interkommunikation som krävs.
I en CPU kan koherens enkelt uppnås på grund av det faktum att vi har väldigt få kärnor inuti den, men i en GPU gör det större antalet kärnor koherenssystemet svårt att implementera; kom ihåg att antalet datavägar som behöver implementeras är n 2 där n är antalet element som är sammankopplade med varandra.
Eftersom grafikprocessorer är på väg att delas in i chipletter är det mycket möjligt att denna koherensenhet blir ett chiplet i sig eller är i den centrala delen som ansvarar för att kommunicera de olika delarna med varandra. I vilket fall som helst har vi ännu inte nått denna punkt och med tanke på att förändringarna på arkitekturnivå sker under perioder på 2 till 5 år, måste vi fortfarande vänta lite.
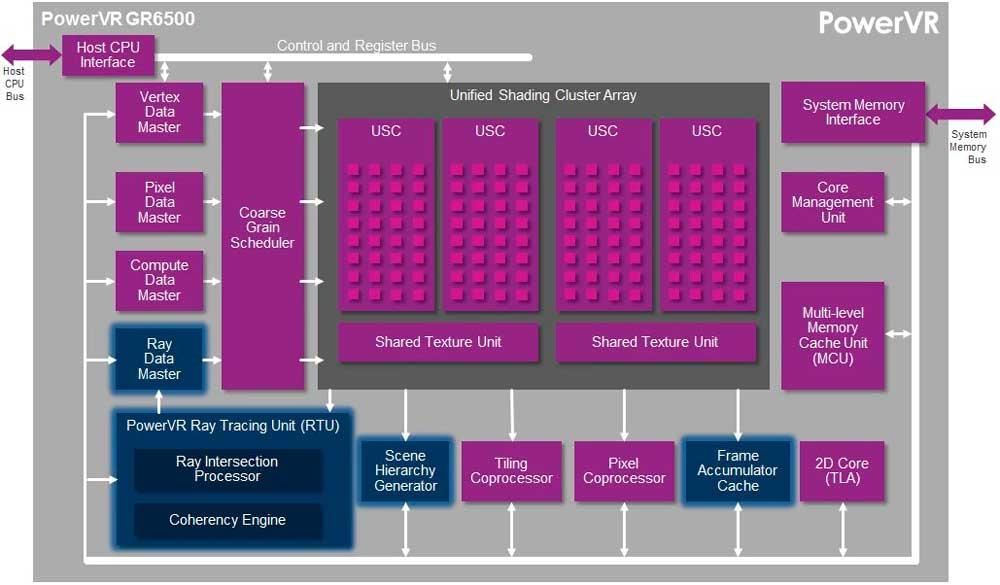
Där koherensmotorn implementeras finns i Imaginationens PowerVR Wizard-arkitektur, eftersom den har implementerats i den hårdvaran i flera år, men NVIDIA och AMD har ännu inte implementerat den i sina grafikprocessorer och det måste tas i beaktande att de har närmat sig ”lite ”Annorlunda än Imagination; I vilket fall som helst är det nästa utveckling för Ray Tracing.