
Grafikprocessorer som processorer är en typ av processor, men de är optimerade för parallell databehandling och generering av grafik i realtid. Trots det faktum att vi har olika typer av arkitekturer, har var och en av GPU: erna en organisation i och därför delar de. Vilket vi kommer att förklara i den här artikeln på ett detaljerat och detaljerat sätt.
I den här artikeln kommer vi inte att ta itu med en specifik GPU arkitektur, men det för dem alla i allmänhet och därför när du ser diagrammet som tillverkare brukar lansera om organisationen av deras nästa GPU kan du förstå det utan problem. Oavsett om det här är en integrerad eller dedikerad GPU och graden av kraft de har.
Organisation av en samtida GPU

För att förstå hur en GPU är organiserad måste vi tänka på en rysk docka eller matrioshka, som består av flera dockor inuti. Som vi också kan tala om en uppsättning som lagrar en serie undergrupper successivt. Med andra ord är GPU: er organiserade på ett sådant sätt att de olika uppsättningarna som komponerar dem i många fall är varandra.
Tack vare denna uppdelning kommer vi att förstå något så komplicerat som en GPU mycket bättre, eftersom vi enkelt kan bygga komplexet. Med det sagt, låt oss börja med den första komponenten.
Ställ in A i organisationen av en GPU: skuggningsenheterna
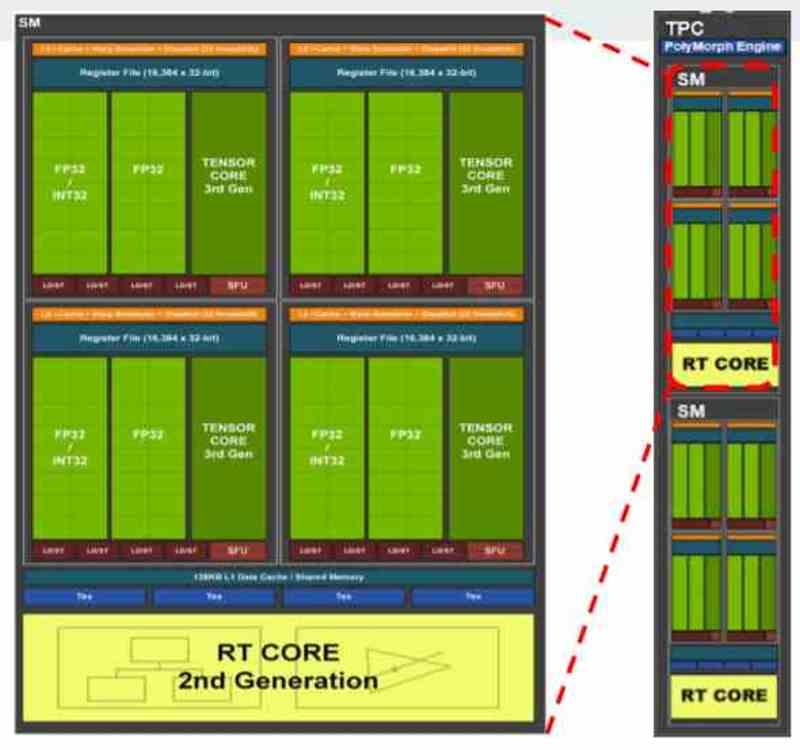
Den första av uppsättningarna är skuggningsenheter. De är i sig själva processorer, men till skillnad från processorer är de inte utformade för parallellitet från instruktioner, ILP, utan från exekveringstrådar, TLP. Oavsett om vi pratar om GPU: er från AMD, NVIDIA, Intel eller något annat märke, alla samtida grafikprocessorer består av:
- SIMD-enheter och deras register
- Scalar Units och deras register.
- Planerare
- Delat lokalt minne
- Texturfiltreringsenhet
- Toppdata och / eller texturcache
- Ladda / lagra enheter för att flytta data till och från cache och delat minne.
- Blixtkorsningsenhet.
- Systoliska matriser eller tensorenheter
- Exportera buss som exporterar data från uppsättning A och till de olika komponenterna i uppsättning B.
Ställ B i organisationen av en GPU : Shader Array / Shader Engine / GPC
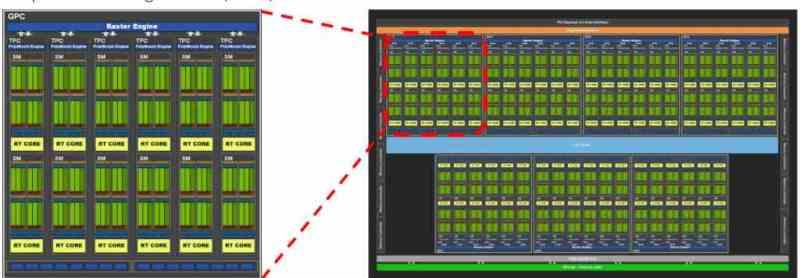
Uppsättning B innehåller uppsättning A i dess inre, men lägger initialt till instruktionen och konstanta cacheminnet. I GPU: er, såväl som CPU: er, delas cache på första nivå upp i två delar, en för data och den andra för instruktioner. Skillnaden är att för GPU: er finns instruktionscachen utanför skuggsenheterna och därför är de i uppsättning B.
Uppsättning B i organisationen av en GPU innehåller därför en serie skuggningsenheter, som kommunicerar med varandra genom det gemensamma kommunikationsgränssnittet mellan dem, så att de kan kommunicera med varandra. Å andra sidan är de olika skuggningsenheterna inte ensamma i uppsättning B, eftersom det är här det finns flera fasta funktionsenheter för rendering av grafik, som nu.
- Primitiv enhet: Detta åberopas under World Space Pipeline eller Geometric Pipeline, det ansvarar för tessellering av scenens geometri.
- Rasteriseringsenhet: Det utför rasterisering av primitiven, omvandlar trianglarna till pixelfragment och dess scen är den som börjar den så kallade Screen Space Pipeline eller Rasterization Phase.
- ROPS: Enheter som skriver bildbuffertarna agerar under två steg. I rasterfasen före textureringsfasen genererar de djupbufferten (Z-buffert) medan de i fasen efter textureringsfasen får resultatet av detta steg för att generera färgbufferten eller de olika renderingsmålen (fördröjd rendering) .
Ställ C i en GPU: s arkitektur :
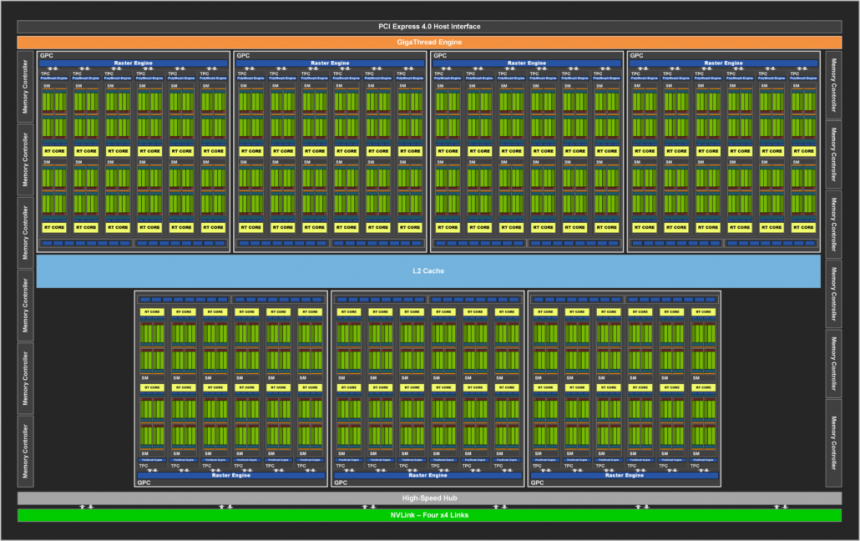
Vi har redan nästan hela GPU eller GPU utan acceleratorer, den består av följande komponenter:
- Flera B-uppsättningar inuti.
- Delat globalt minne : En skraplatta och därför utanför cache-hierarkin för att kommunicera B-uppsättningar med varandra.
- Geometrisk enhet: Den har förmågan att läsa pekarna till RAM-minnet som pekar på scenens geometri, med detta är det möjligt att eliminera icke-synlig eller överflödig geometri så att den inte återges värdelöst i ramen.
- Kommandoprocessorer (grafik och dator)
- Senaste cache: Alla element i GPU: n är klienter för denna cache så den måste ha en enorm kommunikationsring, alla komponenter i Set B har direktkontakt med L2-cachen liksom alla komponenter i Set C själv.
Last Level Cache (LLC) är viktigt eftersom det är cachen som ger oss enhetlighet mellan alla element i Set C med varandra, uppenbarligen inklusive uppsättningar B i den. Inte bara det, men det tillåter inte att övermätta den externa minneskontrollern eftersom det med detta är LLC själv, tillsammans med MMU-enheten (erna) i GPU: n, som ansvarar för att fånga instruktioner och data från RAM. Tänk på Cache på sista nivån som ett slags logistiklager där alla element i Set C skickar och / eller tar emot sina paket och deras logistik kontrolleras av MMU, som är enheten som ansvarar för att göra det.
Slutuppsättning, full GPU

Med allt detta har vi redan hela GPU: n, set D innehåller huvudenheten som är GPU: n som ansvarar för att rendera grafiken för våra favoritspel, men det är inte den högsta nivån på en GPU, eftersom vi saknar en serie coprocessorer Stöd. Dessa fungerar inte för att rendera grafik direkt, men utan dem skulle GPU inte kunna fungera. Dessa element är i allmänhet:
- GFX-enheten inklusive dess cache på toppnivå
- North Bridge eller Northbridge i GPU, om detta är i en heterogen SoC (med en CPU) men med ett delat minnesbrunn så kommer de att använda en gemensam Northbridge. Alla element i Set D är anslutna till Northbridge
- Acceleratorer: Videokodare, skärmadaptrar, är anslutna till Northbridge. När det gäller skärmadaptern är det den som skickar videosignalen till DisplayPort- eller HDMI-porten
- DMA-enheter: Om det finns två RAM-adresseringsutrymmen (även med samma fysiska brunn) tillåter DMA-enheten att data överförs från ett RAM-utrymme till ett annat. När det gäller en separat GPU fungerar DMA-enheterna som kommunikation med CPU eller andra GPU: er.
- Styrenhet och minnesgränssnitt: Det gör det möjligt att kommunicera elementen i Set D med det externa RAM-minnet. De är anslutna till Northbridge och det är den enda vägen till det externa RAM-minnet.
Med allt detta har du redan en fullständig organisation av en GPU, med vilken du kan läsa diagrammet för en GPU mycket bättre och förstå hur den är organiserad internt.