När vi har en server med Linux eller en NAS-server (som också har ett Linux-baserat operativsystem) med mycket information inuti, både själva operativsystemet och personliga eller arbetsfiler och mappar, är det viktigt att kontrollera att hårddiskarna och SSD enheter är vid god hälsa och kommer inte att gå sönder när som helst utan förvarning. Av denna anledning är det mycket viktigt att kontinuerligt övervaka hårddisken eller SSD på vår server, för att undvika dataförlust på grund av att den går sönder. Idag i den här artikeln kommer vi att visa dig allt du bör kontrollera på din Linux-server för att kontrollera tillståndet på dina diskar.

Vad är skivornas SMART
Alla hårddiskar och SSD-enheter har en teknik som kallas SMART, eller även känd som SMART som står för "Self Monitoring Analysis and Reporting Technology". Denna teknik som är inbyggd i hårddiskarnas och SSD:s firmware består av att upptäcka eventuella fel i hårddisken, i syfte att förutse fysiska fel i hårddisken eller oväntade fel i SSD-enheter på grund av skrivning till internt flashminne. . Målet med SMART är att varna användare så att de kan säkerhetskopiera och byta ut enheten utan att förlora data. Om vi ignorerar SMART kommer det att komma en tid då hårddisken kommer att gå sönder och vi kommer att förlora data, så det är viktigt att alltid vara uppmärksam på SMART-data på diskarna.
För att kunna använda SMART är det absolut nödvändigt att BIOS eller UEFI på servern är kompatibel med denna teknik och att den är aktiverad, dessutom är det också absolut nödvändigt att diskarna innehåller det. Idag använder alla servrar, operativsystem och diskar denna teknik för att upptäcka problem på hårddisken, vi kan säga att den är "universell" och att den alltid används.
Denna teknik är ansvarig för att övervaka olika parametrar på hårddisken, såsom hastigheten på skivplattorna, dåliga sektorer, kalibreringsfel, cyklisk redundanskontroll (de typiska CRC-felen), disktemperatur, dataläshastighet, starttid (spin- upp), räknare för omfördelade sektorer, sökhastighet (söktid) och andra mycket avancerade parametrar som låter dig veta vad som är viktigt: om hårddisken snart kommer att gå sönder.
Internt har SMART en rad värden som vi kan betrakta som "normala", och när en parameter går utanför dessa värden, det vill säga när larmet går, kommer BIOS/UEFI att upptäcka det och meddela operativsystemet att det finns ett fel i systemet. skiva och det kan vara allvarligt. I Linux operativsystem har vi möjlighet att utföra SMART-tester för att kontrollera om disken fungerar korrekt, dessutom har vi möjlighet att programmera dessa tester för att minimera påverkan på prestanda.
Hur man visar diskens hälsa
I de flesta Linux-baserade distributioner har vi ett paket som heter smartmontools. Ibland är det här paketet förinstallerat i vår distribution, och andra gånger måste vi installera det själva. Detta paket har två olika program:
- smartctl : är kommandoradsprogrammet som låter oss verifiera hårddiskar och SSD:er på begäran, eller så kan vi programmera dess funktion genom den typiska cronen i operativsystemet.
- smartd : är en demon eller process som verifierar att hårddiskar eller SSD:er i ett specificerat intervall inte har haft några fel. Det är kapabelt att registrera alla typer av varningar eller diskfel till serverns huvudsyslog, det tillåter också att skicka samma varningar och fel via e-post till administratören så att han kan verifiera att allt är korrekt.
Smartmontools-paketet ansvarar för övervakning av hårddiskar och SSD-enheter, oavsett om de använder SATA-, SCSI-, SAS- eller NVME-gränssnitt, det stöder alla typer av datagränssnitt. Naturligtvis är detta program helt gratis.
Installation
Installation av detta program, om det inte är installerat som standard på din Linux-distribution, sker genom att använda din distributions pakethanterare. Till exempel, på Debians operativsystem med apt skulle det vara som följer:
sudo apt install smartmontools
Beroende på pakethanteraren för din distribution måste du använda ett eller annat kommando, det viktiga är att detta paket är tillgängligt för alla Unix-baserade distributioner och även Linux, så du kan även installera det på FreeBSD utan problem.
Använder smartctl
För att kunna använda det här programmet och kontrollera vår hårddisks hälsa är det första vi måste göra att veta hur många hårddiskar vi har, och vad som är vägen för att undersöka de aktuella hårddiskarna eller SSD:erna. För att veta var diskarna är måste vi köra följande kommando:
df -h
Vi kan också använda fdisk för att få listan över diskar som vi har på vår server:
sudo fdisk -l
Dessa kommandon visar oss en lista över enheterna och även över partitionerna. Vi måste använda det här programmet på hårddisk- eller SSD-nivå, inte på partitionsnivå. Vanligtvis i Linux-system hittar vi diskarna i /dev/sdX-sökvägen.
När vi väl vet vilken enhet vi ska analysera för att kontrollera dess hälsa genom SMART, måste vi veta att det finns totalt två olika tester som vi kan utföra:
- Kort test – Det här testet används oftast för att upptäcka diskproblem. När du utför detta test kommer det att visa oss de viktigaste felen och varningarna, utan att behöva analysera hela disken i detalj. Vi kan schemalägga det här korta testet genom cron att vara veckovis, på detta sätt kommer det att utföra denna analys en gång i veckan och meddela oss om det har upptäckt några fel. Det är tillrådligt att göra detta test vid en tidpunkt då det är liten eller ingen användning, det rekommenderas inte att göra det under arbetstid, bättre i gryningen.
- Långt test – Detta test kan ta ganska lång tid, beroende på enheten och dess kapacitet. Genom att utföra detta omfattande test kommer den att visa oss alla varningar eller fel som den hittar på hela disken. Vi kan schemalägga detta långa test med cron att göras månadsvis, det vill säga en gång i månaden kommer vi att utföra detta test för att kontrollera diskens hälsa. Det är tillrådligt att göra det här testet vid en tidpunkt då det är lite användning av disken, till exempel i gryningen, eftersom läs- och skrivprestandan samt latensen för dataåtkomst kommer att öka avsevärt.
När vi väl känner till de två typerna av tester som vi kan använda, är det första vi behöver veta om hårddisken eller SSD har SMART aktiverat:
sudo smartctl -i /dev/sda
I händelse av att disken stöder SMART men inte är aktiverad, kan vi aktivera den genom att utföra följande kommando:
sudo smartctl -s on /dev/sda
För att se alla SMART-attribut för tillverkaren av skivan i fråga kan vi köra följande kommando:
sudo smartctl -a /dev/sda
För att utföra ett kort test utför vi följande:
sudo smartctl -t short /dev/sda
För att utföra ett långt test utför vi följande:
sudo smartctl -t long /dev/sda
När vi har utfört det korta eller långa testet kan vi utföra följande kommando för att se alla resultat:
sudo smartctl -H /dev/sda

Vi rekommenderar att du läser man-sidorna för smartctl där du hittar alla kommandon som vi kommer att kunna utföra för att använda möjligheterna med SMART, men huvudkommandona är de som vi har förklarat för dig.
Vilka värden ska jag titta på?
När vi gör ett SMART-test kommer ett stort antal attribut för vår hårddisk eller SSD att dyka upp. Några av dessa värden är kritiska som vi är mycket uppmärksamma på, eftersom de kan ge oss "ledtrådar" om att disken kommer att misslyckas mycket snart:
- Reallocated_Sector_Ct: är antalet sektorer som har omfördelats till andra delar av disken eftersom det har uppstått läsfel. Detta fel är mycket typiskt när en disk är mycket gammal och närmar sig slutet av sin livslängd.
- Spin_Retry_Count: är antalet försök som har varit nödvändiga för att starta upp disken, detta indikerar att det finns ett allvarligt hårdvaruproblem på disken och att den kanske inte startar nästa gång.
- Reallocated_Event_Count – Antalet omfördelningar som har utförts, antingen framgångsrikt eller misslyckat. Ju högre siffra, desto sämre hälsa har hårddisken.
- Current_Pending_Sector: antal sektorer som väntar på att omfördela snart.
- Offline_Uncorrectable: antal okorrigerbara fel vid åtkomst, antingen läsning eller skrivning, till olika sektorer av disken.
- Multi_Zone_Error_Rate: totalt antal fel under skrivning av en sektor.
I följande bild kan du se status för en WD Red 4TB-hårddisk från vår NAS med operativsystemet XigmaNAS:

I den föregående skärmdumpen kan du se mycket information, men vi måste veta om det är ett isolerat fel eller så kan vår disk snart gå sönder.
Status för diskar i QNAP NAS
Om du har en QNAP, Synology eller ASUSTOR NAS-server kommer du även att kunna se SMART-statusen för dina hårddiskar och SSD:er genom operativsystemet med webbåtkomst, det finns inget behov av att gå in via SSH eller Telnet och utföra några kommandon . I exemplet nedan har vi använt en QNAP NAS-server, men processen med de andra tillverkarna skulle vara väldigt lika.
Det första vi måste göra är att gå till " Lagring och ögonblicksbilder ”-avsnittet, en gång här, klicka på ” Lagring / Diskar ” och vi kommer att se något sånt här:

Om vi klickar på " Skivans skick ”, måste vi välja vilken skiva av alla vi vill titta på. Vi kan välja både HDD-hårddiskar och SSD-enheter, oavsett vilken typ de är eftersom de även har intern SMART-information för att se om det finns ett diskfel.

I menyn "Sammanfattning" kan vi se den allmänna statusen för disken, om det finns någon typ av fel eller allvarlig varning kan vi också se den allmänna hälsan enkelt och snabbt, utan att behöva utföra en detaljerad analys av SMART värden . Naturligtvis kan vi också se diskåtkomsthistoriken och om det har varit några problem.

Även om QNAP ger oss mycket lättförståelig information, om vi vill se alla råvärden, kommer vi också att kunna göra det utan problem. Dessutom kommer vi att ha en extra kolumn som talar om för oss "Status" och om den är bra eller dålig.
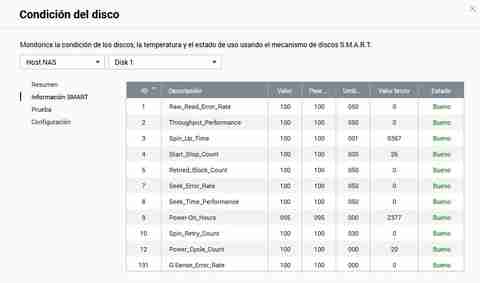
Vi kommer att kunna göra snabba eller kompletta tester här, vi måste helt enkelt välja testmetod och sedan klicka på knappen "Test".

Slutligen kan vi också programmera dessa tester på ett mycket enkelt sätt, vi måste helt enkelt välja att aktivera snabb eller komplett test, och välja frekvens: dagligen, veckovis eller månadsvis, dessutom kan vi definiera starttiden för detta test.

Som du kan se är det verkligen viktigt att kontrollera och verifiera hälsostatusen för hårddiskar och SSD:er på en server för att undvika dataförlust. När någon form av fel uppstår är det mycket viktigt att köpa en ny enhet och göra en säkerhetskopia för att undvika dataförlust. Dessutom bör vi också kontrollera statusen för RAID eftersom vi kan orsaka förlust av hela lagringspoolen, speciellt om vi har konfigurerat en ZFS RAID 0 eller Stripe.