
För några veckor sedan tilldelades ett patent AMD publicerades förklarar det hur deras GPU: er uppdelade i flera marker kommer att fungera, vilket kommer att vara en allmän regel inte bara för dem utan också för tävlingen. Där vi vet det NVIDIA Hopper och Intel Xe-HP är indelade i flera marker. Men AMDs lösning är något annorlunda än den som konkurrensen föreslår, vi förklarar patentet för AMD-chiplets.
Anledningen till att dubbla GPU: er har försvunnit från den inhemska miljön och är svaret på frågan om varför vi inte längre ser grafikkort som är kompatibla med NVIDIA SLI eller AMD Crossfire är detsamma, de applikationer vi använder på våra datorer är programmerade för att använda en enda GPU.

I PC-videospel, när du använder en dubbel GPU. Tekniker som alternativ bildrendering används, där varje GPU gör en alternativ ram i förhållande till den andra, eller delad bildrendering där paret av grafikprocessorer delar upp arbetet med en enda ram.
Vid beräkning via GPU inträffar detta problem inte, varför i system där grafikkort inte används för att rendera grafik, hittar vi flera av dem fungerar parallellt utan problem. Dessutom är applikationer som använder GPU: er som parallella dataprocessorer redan utformade för att dra nytta av GPU: er på det sättet.
Ökningen av storleken på GPU: er de senaste åren

Om vi tittar på utvecklingen av grafikprocessorer under de senaste åren kommer vi att se att det har skett en betydande tillväxt inom området toppmoderna grafikprocessorer från en generation till en annan.
Det värsta av det nuvarande scenariot? Det finns ingen GPU som har den perfekta prestandan för 4K-spel än. Det måste tas med i beräkningen att en inbyggd 4K-bild har fyra gånger fler pixlar än en vid 4p och därför talar vi om en datarörelse som är fyra gånger det som krävs för Full HD.
I den nuvarande situationen i VRAM har vi fallet med GDDR6, nämnda minne använder ett 32-bitars gränssnitt per chip, uppdelat i två 16-bitars kanaler, men med en klockhastighet som gör att dess energiförbrukning skjuter i höjden, vilket leder oss att leta efter andra lösningar för att utöka bandbredden.
Utöka bandbredden för VRAM

Om vi vill utöka bandbredden finns det två alternativ:
- Det första är att höja minneshastigheten, men det måste tas i beaktande att spänningen är kvadratisk när MHz för detta ökar, och därmed energiförbrukningen.
- Den andra är att öka antalet stift, vilket skulle vara att gå från 32 bitar till 64 bitar.
Vi kan inte glömma bort saker som PAM-4 som används i GDDR6X heller, men det har varit ett drag från Micron för att undvika att nå höga klockhastigheter. Så en 64-bitars buss per VRAM-chip bör förväntas för en eventuell GDDR7 ..
Vi vet inte vad VRAM-tillverkare ska göra, men att öka klockhastigheten är inte det alternativ vi tror att de kommer att sluta anta inom en begränsad energibudget.

Vi vet inte vad VRAM-tillverkare ska göra, men att öka klockhastigheten är inte det alternativ vi tror att de kommer att anta.
Gränssnitten mellan GPU och VRAM är dock placerade på utsidan av själva GPU: n. Så att öka antalet bitar av det är att expandera periferin för nämnda GPU och därför göra den större.
Vad som är ett allvarligt tillagt problem på grund av den höga storleken när det gäller kostnad, detta kommer att tvinga grafikkortstillverkare att använda flera marker istället för en, och det är vid denna punkt där vi går in i de så kallade chiplets.
Chipletbaserade GPU-typer

Det finns två sätt att dela upp en GPU i Chiplets:
- Att dela upp en enda, stor GPU i flera chipletter, är avvägningen av detta att kommunikation mellan de olika parterna kräver massiv bandbredd som kanske inte är möjlig utan användning av speciella intercoms.
- Använd flera GPUS i samma utrymme som fungerar tillsammans som en.
I HardZone-artikeln med titeln "Så här kommer GPU: erna baserade på Chiplets som vi kommer att se i framtiden bli" kan du läsa om konfigurationen av den första typen, medan AMD-patentet avseende dess GPU med chiplets hänvisar till de andra typ.
Utforska patentet för AMD-chiplets:
Den första punkten som förekommer i varje patent är nyttan med uppfinningen, som alltid kommer i dess bakgrund, som vi berörs är följande:
Konventionella monolitiska mönster som blir allt dyrare att tillverka. Chiplets har använts framgångsrikt i CPU arkitekturer för att sänka tillverkningskostnaderna och förbättra avkastningen. Eftersom dess heterogena beräkningsnatur anpassar sig mer naturligt till separata CPU-kärnor i olika enheter som inte kräver mycket interkommunikation mellan dem.
Omnämnandet av processorer är tydligt att det hänvisar till AMD Ryzen och är att en stor del av designteamet för Zen-arkitekturer förflyttades till Radeon Technology Group för att arbeta med att förbättra RDNA-arkitekturen. Begreppet chiplets är inte det första som ärvs från Zen, det andra är det Infinity cache, som ärver begreppet ”Victim Cache” från Zen.
För det andra hänvisar intercomproblemet du hänvisar till till den enorma bandbredd som GPU: er behöver för att kommunicera sina element med varandra. Vilket är hindret inför konstruktionen av dessa i chiplets, på grund av den energi som förbrukas vid överföringen av data.
Arbetet med en GPU är parallellt till sin natur. Emellertid innehåller geometrin som bearbetas av en GPU inte bara sektioner av arbete parallellt utan också arbeten som behöver synkroniseras i en specifik ordning mellan de olika sektionerna.
Konsekvensen av det? En programmeringsmodell för en GPU som distribuerar arbete över olika trådar är ofta ineffektiv, eftersom parallellitet är svår att distribuera över flera olika arbetsgrupper och chiplets, eftersom det är är svårt och dyrt att synkronisera minnesinnehållet från resurser som delas över systemet.

Den del som vi har lagt i fetstil är förklaringen ur perspektivet för mjukvaruutveckling för vilken vi inte har sett GPU: er baserade på chiplets. Det är inte bara ett hårdvaruproblem utan ett programvaruproblem, så det är nödvändigt att förenkla.
Från en logisk synvinkel skrivs också applikationer med sikte på att systemet bara har en GPU. Det vill säga, även om en konventionell GPU innehåller många GPU-kärnor, är applikationer programmerade för att rikta in sig på en enda enhet. Därför har det historiskt varit en utmaning att få chipletdesignmetoden till GPU-arkitekturer.
Denna del är nyckeln till att förstå patentet, AMD pratar inte om att dela upp en enda GPU i chiplets vilket är vad den gör i sina processorer, utan snarare om att använda flera GPU: er där var och en är en chiplet, det är viktigt att hålla i tänk på denna skillnad, eftersom AMDs lösning verkar mer fokuserad på att skapa en Crossfire där det inte är nödvändigt för programmerare att anpassa sina program för olika GPU: er.
När problemet väl är definierat är nästa punkt att prata om lösningen som erbjuds av patentet.
Utforska AMD Chiplet Patent: The Solution
Lösningen på det exponerade problemet som AMD föreslår är följande:
För att förbättra systemets prestanda med GPU-chiplets samtidigt som den nuvarande programmeringsmodellen bibehålls illustrerar patentet system och metoder som använder passiva tvärlänkar med hög bandbredd för att ansluta GPU-chiplets till varandra.
Den viktiga delen av patentet är de tvärbindningar, som vi kommer att prata om senare i den här artikeln, det här är kommunikationsgränssnittet mellan de olika chipletterna, det vill säga hur information överförs mellan dem.
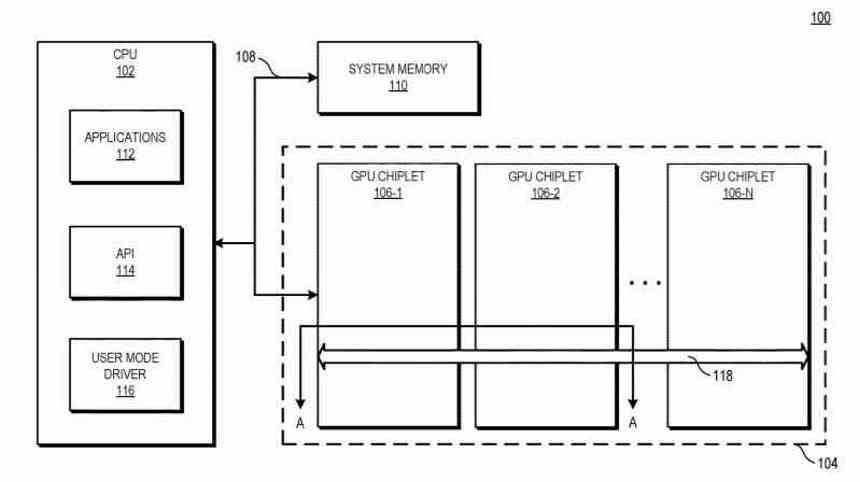
I olika implementeringar inkluderar ett system den centrala processorenheten (CPU) som är ansluten till den första GPU-chiplet i kedjan, som är ansluten till en andra chiplet genom den passiva tvärbindningen. I vissa implementeringar är den passiva tvärbindningen en passiv interposerare som hanterar kommunikation mellan chipletter .
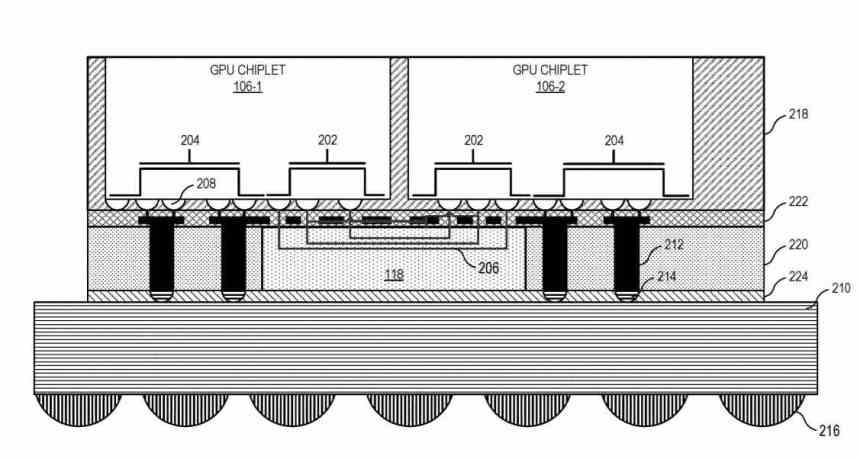
I grund och botten går det ner på det faktum att vi nu har en dubbel GPU som fungerar som en, som består av två sammankopplade marker genom en mellanläggare som ligger nedanför.
Passiva tvärbindningar med hög bandbredd
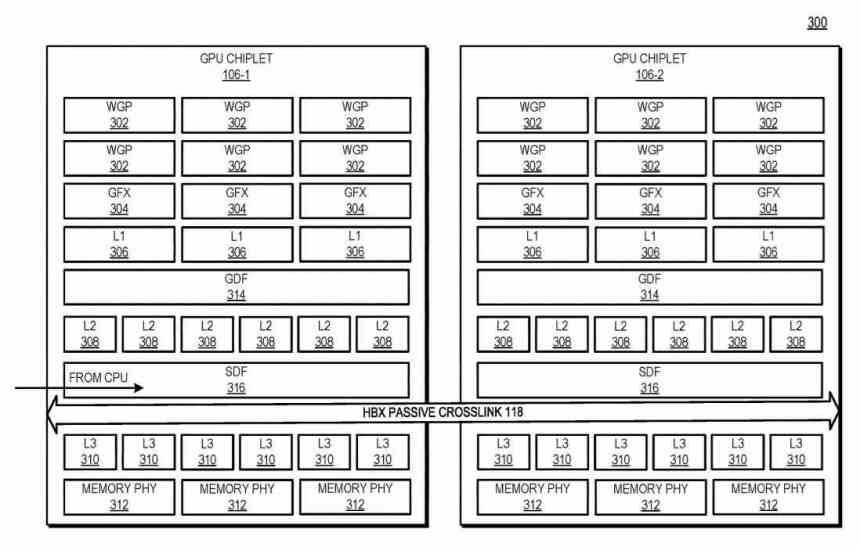
Hur kommunicerar chiplets med interposern? Med hjälp av en typ av gränssnitt som kommunicerar Scalable Data Fabric (SDF) för var och en av chipletterna med varandra är SDF i AMD GPU: er den del som normalt sitter mellan GPU: s toppnivåcache och gränssnittet. minne, men i det här fallet finns det en L3-cache mellan SDF för varje GPU-chiplet och SDF och innan det ett gränssnitt som interkommunikerar de två chipletterna med varandra.
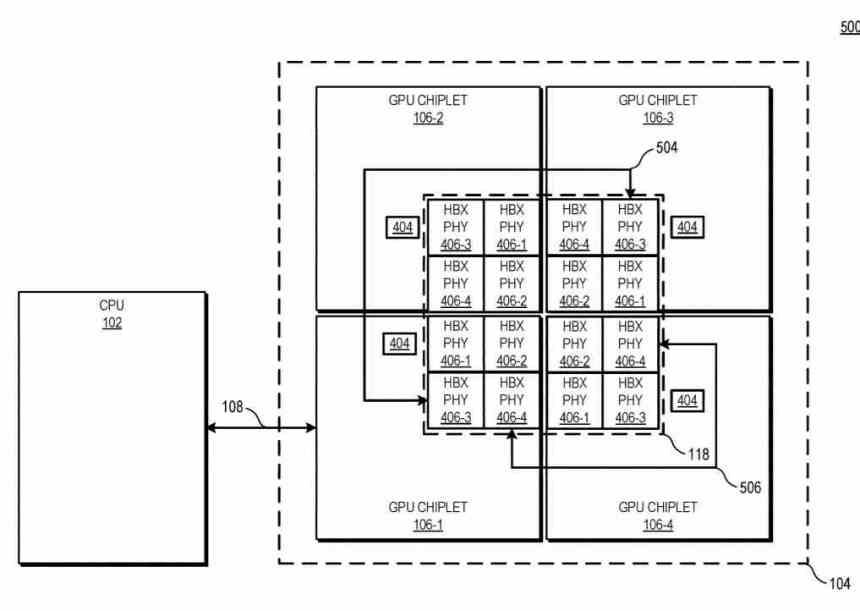
I det här diagrammet kan du se exemplet med 4 GPU-chiplets, antalet HBX-gränssnitt är alltid 2 2 där n är antalet chipletter i mellanlägget. Om man tittar på nivån för cachehierarkin är L0 (beskrivs inte i patentet) lokalt för varje beräkningsenhet, L1 för varje Shader Array, L2 för varje GPU-chipett, medan L3-cache skulle vara en nyhet, detta Det beskrivs som sista nivå cache eller LCC för hela GPU-uppsättningen.
För närvarande har olika arkitekturer minst en nivå av cache som är konsekvent över hela GPU. Här, i en chiplet-baserad GPU-arkitektur, placerar den de fysiska resurserna på separata marker och kommunicerar dem på ett sådant sätt att nämnda toppnivåcache förblir konsekvent över alla GPU-chiplets. Trots att det fungerar i en massivt parallelliserad miljö måste L3-cachen vara konsekvent.
Under en operation överförs begäran till en minnesadress från CPU till GPU till en enda GPU-chiplet, som kommunicerar med den passiva tvärlänken med hög bredd för att lokalisera data. Ur CPU-synvinkel ser det ut som om du är på väg mot en monolitisk GPU med en chip. Detta möjliggör användning av en GPU med hög kapacitet, som består av flera chiplets som om det vore en enda GPU för applikationen.
Detta är anledningen till att AMDs lösning inte är uppdelningen av en GPU i flera olika chiplets, utan användningen av flera GPU: er som om det vore en, vilket löser ett av de problem som AMD Crossfire tog med sig och tillåter vilken programvara du kan använda flera GPU: er samtidigt som om de vore en och utan att behöva anpassa koden.
Den andra nyckeln till passiva tvärbindningar är det faktum att i motsats till vad många av oss spekulerade i, kommunicerar de inte med GPU med kanaler genom kisel eller TSV, utan att AMD har skapat en egen interkommunikation för konstruktion av SoC. , CPU: er och GPU: er, både i 2.5DIC och 3DIC, vilket får oss att undra om X3D-gränssnittet som måste ersätta sin Infinity Fabric.
AMD-chiplets är för RDNA 3 och framåt

Det faktum att problemet vid användning av flera GPU: er inte är ett problem med applikationer som är utformade för datorer via GPU: er gör det mycket tydligt att den lösning som AMD föreslår i sitt patent riktar sig till den inhemska marknaden, särskilt GPU: er med RDNA-arkitekturer, det finns flera ledtrådar om det:
- I diagrammen över patentets chipletter visas termen WGP, vilket är typiskt för RDNA-arkitekturen och inte för CDNA och / eller GCN.
- I en del av patentet nämns användningen av GDDR-minne, vilket är typiskt för inhemska grafikprocessorer.
Patenten beskriver inte en specifik GPU för oss, men vi kan anta att AMD kommer att släppa den första chipletbaserade dubbla GPU när RDNA 3 startar. Detta gör det möjligt för AMD att skapa en enda GPU istället för olika variationer av en arkitektur i form av olika marker som har varit fallet idag.

AMDs lösning står också i kontrast till det som ryktas av NVIDIA och Intel. Från det första vet vi att Hopper kommer att vara den första arkitekturen baserad på chiplets, men vi känner inte till dess målmarknad, så det kan mycket väl riktas mot den högpresterande datormarknaden som spel.
När det gäller Intel vet vi att Intel Xe-HP är en GPU som också består av chiplets, men utan behov av en lösning som AMD, eftersom Intels mål för nämnda GPU inte är den inhemska marknaden.