Мульти-графические процессоры по чиплетам уже не за горами, и хотя мы сначала увидим их в виде карт HPC и, следовательно, за пределами игрового рынка, мы давно знаем, что эволюция идет в сторону создания графических карт на основе мульти-графических процессоров. за чиплеты. Но что они приносят по сравнению с обычным монолитным GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР? Читай дальше что бы узнать.

Архитектура, которую мы обсуждаем в этой статье, еще не доступна на рынке, она даже не была представлена, но это результат анализа достижений, достигнутых в последние годы, а также различных патентов на Multi-GPU. чиплеты, которые оба AMD, NVIDIA и Intel издаются последние два года. Вот почему мы решили взять эту информацию и синтезировать, чтобы вы имели представление о том, как работают эти типы графических процессоров и какие графические проблемы они решают.
Традиционный 3D-рендеринг с использованием нескольких графических процессоров

Использование нескольких видеокарт для объединения их мощности для рендеринга каждого кадра в трехмерных видеоиграх не новость, поскольку с Voodoo 3 от 2dfx можно полностью или частично разделить работу по рендерингу между несколькими видеокартами. Наиболее распространенный способ сделать это - рендеринг альтернативного кадра, где ЦП поочередно отправляет список экранов каждого кадра каждому графическому процессору. Например, GPU 1 обрабатывает кадры 1, 3, 5, 7, а GPU 2 обрабатывает кадры 2, 4, 6, 8 и т. Д.
Существует еще один способ рендеринга сцены в 3D, это рендеринг с разделением кадров, который состоит из нескольких графических процессоров, рендеринг одной сцены и разделяющих работу, но со следующими нюансами: графический процессор является основным графическим процессором, который считывает список экрана и позаботится обо всем остальном. Первые этапы конвейера до растеризации выполняются исключительно на первом графическом процессоре, так как растеризация и последующие этапы выполняются одинаково на каждом графическом процессоре.
Рендеринг с разделением кадров кажется справедливым способом распределения работы, однако теперь мы увидим, какие проблемы влечет за собой этот метод и с какими ограничениями он имеет.
Ограничения рендеринга с разделением кадров и возможное решение

Каждый графический процессор содержит 2 коллекции дисков DMA, первая пара может одновременно читать или записывать данные в системе. Оперативная память через порт PCI Express, но во многих видеокартах с поддержкой Crossfire или SLI есть другой набор дисков DMA, которые позволяют получить доступ к VRAM другого графа. Конечно, на скорости порта PCI Express, что является настоящим узким местом.
В идеале все графические процессоры, работающие вместе, должны иметь одинаковую общую память VRAM, но это не так. Таким образом, данные дублируются столько раз, сколько видеокарт задействовано в рендеринге, что крайне неэффективно. К этому мы должны добавить способ, которым графические карты работают при рендеринге 3D-графики в реальном времени, что привело к тому, что конфигурация с несколькими видеокартами больше не использовалась.
Тайловое кэширование на мульти-GPU с помощью чиплетов
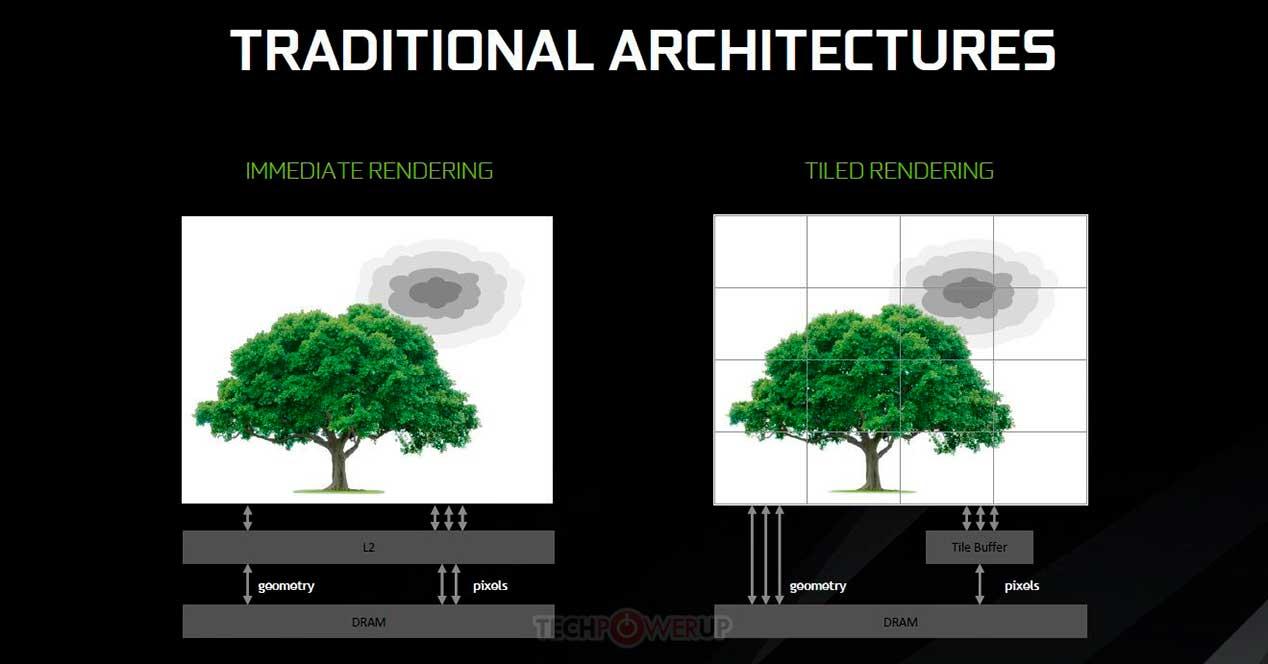
Концепция тайлового кэширования начала использоваться из архитектуры NVIDIA Maxwell и архитектуры AMD Vega, она заключается в использовании некоторых концепций от рендеринга по тайлам, но с той разницей, что вместо рендеринга каждого тайла в отдельной памяти и записи его во VRAM только тогда, когда готово сделано на кэше второго уровня. Преимущество этого заключается в том, что это экономит затраты энергии на некоторые графические операции, но недостатком является то, что это зависит от объема кэша верхнего уровня, который находится на графическом процессоре.
Проблема в том, что кэш не работает как обычная память, и в любой момент и без программного управления строка кеша может быть отправлена на следующий уровень иерархии памяти. Что, если мы решим применить те же функции к графическому процессору на основе чиплетов? Что ж, здесь появляется дополнительный уровень кэша. Согласно новой парадигме, кеш последнего уровня каждого графического процессора игнорируется как память для тайлового кэширования, и теперь используется кеш последнего уровня мульти-графического процессора, который можно найти на отдельная фишка.
LCC на мульти-GPU по чиплетам
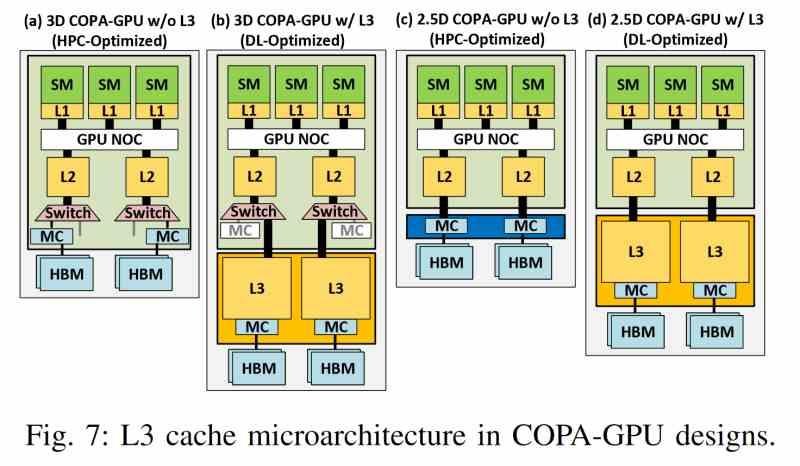
Кэш последнего уровня для мульти-графических процессоров на основе чиплетов объединяет ряд общих характеристик, которые не зависят от производителя, поэтому следующий список характеристик применим к любому графическому процессору этого типа, независимо от производителя.
- Его нет ни в одном из графических процессоров, но он является внешним по отношению к ним и, следовательно, находится на отдельном чипе.
- Он использует промежуточное устройство с очень высокоскоростным интерфейсом, такое как кремниевый мост или межкомпонентные соединения TSV, для связи с кешем второго уровня каждого графического процессора.
- Требуемая широкая полоса пропускания не позволяет использовать обычные межсоединения и, следовательно, возможна только в конфигурации 2.5DIC.
- Чиплет, в котором расположен кэш последнего уровня, не только хранит указанную память, но также является местом, где расположен весь механизм доступа к VRAM, который, таким образом, отделен от механизма рендеринга.
- Его пропускная способность намного выше, чем у памяти HBM, поэтому в нем используются более продвинутые технологии трехмерного соединения, которые обеспечивают гораздо более высокую пропускную способность.
- Кроме того, как и любой кеш последнего уровня, он может обеспечивать согласованность всех элементов, являющихся его клиентами.
Благодаря этому кешу каждый графический процессор не может иметь свою собственную VRAM, чтобы иметь общую, что значительно снижает множественность данных и устраняет узкие места, которые являются продуктом связи в обычном многопроцессорном процессоре.
Главный и подчиненный GPU
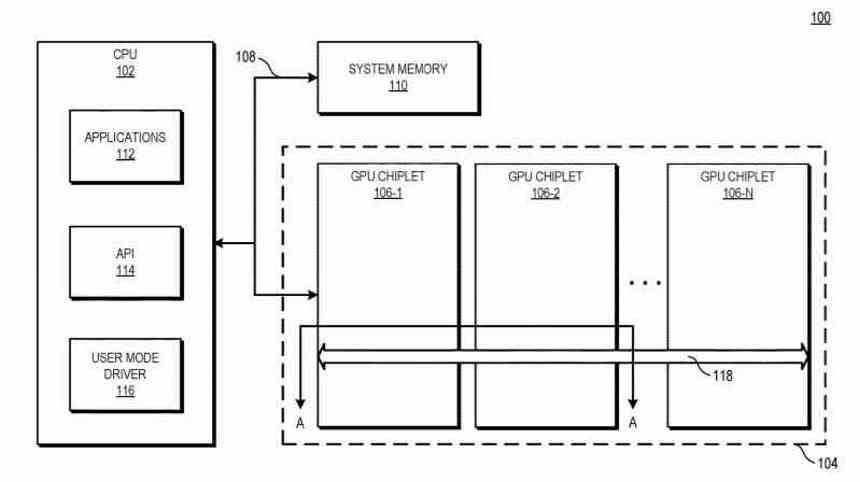
В графической карте, основанной на нескольких графических процессорах с помощью чиплетов, при создании списка отображения все еще существует та же конфигурация, что и в обычном многопроцессорном процессоре. Если создается единый список, который получает первый графический процессор, который отвечает за управление остальными графическими процессорами, но большая разница в том, что чиплет LLC, который мы обсуждали в предыдущем разделе, позволяет первому графическому процессору координировать и отправлять задачи в Остальные процессоры с несколькими графическими процессорами на чиплеты.
Альтернативное решение состоит в том, что все чиплеты Multi-GPU будут полностью лишены командного процессора, и это будет в той же схеме, что и чиплет LCC, расположенный в качестве проводника оркестра и использующий всю существующую инфраструктуру связи для отправки различных инструкций. потоки к разным частям графического процессора.
Во втором случае у нас не было бы главного графического процессора и остальных в качестве подчиненных, но вся 2.5D интегральная схема была бы одним графическим процессором, но вместо того, чтобы быть монолитной, она была бы составлена из нескольких чиплетов.
Его важность для трассировки лучей

Одним из наиболее важных моментов на будущее является трассировка лучей, которая для работы требует, чтобы система создала пространственную структуру данных на основе информации об объектах, чтобы представить перенос света. Было показано, что если указанная структура находится близко к процессору, ускорение, которое испытывает трассировка лучей, имеет важное значение.
Конечно, эта структура сложна и требует много памяти. Вот почему наличие большого кэша LLC будет чрезвычайно важно в будущем. И это причина, по которой кеш LLC будет находиться в отдельном чиплете. Чтобы иметь максимально возможную емкость и сделать эту структуру данных как можно ближе к графическому процессору.
Сегодня большая часть медлительности в трассировке лучей связана с тем, что большая часть данных находится во VRAM и существует огромная задержка при их доступе. Имейте в виду, что кэш LLC в мульти-графическом процессоре будет иметь преимущества не только с точки зрения пропускной способности, но и с точки зрения задержки кеша. Кроме того, его большой размер и методы сжатия данных, разрабатываемые в лабораториях Intel, AMD и NVIDIA, позволят сохранить структуры BVH, используемые для ускорения, во «внутренней» памяти графического процессора.