
Первым процессором с нестандартным исполнением был IBM POWER 1, который стал основой для одноименных RISC-процессоров и PowerPC. Intel приняла эту технологию для x86 в своем Pentium Pro. С тех пор все процессоры ПК используют неисправную технологию как одну из основных для достижения максимально возможной производительности.
Основная задача при проектировании процессоров часто заключается не в максимальной мощности, а в максимальной производительности при выполнении инструкций. Под производительностью мы понимаем факт приближения к теоретическому идеалу работы процессора. Бесполезно иметь самый мощный ЦП если из-за ограничений единственное, что у него есть, - это потенциал быть, а не быть.
Два способа борьбы с параллелизмом
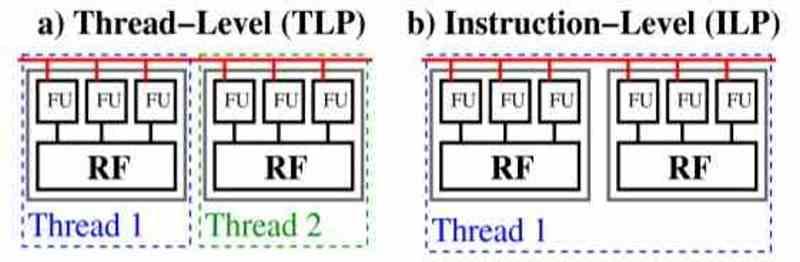
Существует два способа обработки параллелизма в коде программы: параллелизм на уровне потоков или ILP и параллелизм инструкций или TLP.
В TLP код разделен на несколько подпрограмм, которые независимы от других и работают асинхронно, то есть каждая из них не зависит от кода остальных. Когда мы находимся в процессоре TLP, ключевым моментом является то, что если по какой-либо причине происходит остановка выполнения, то процессор TLP берет другой из потоков выполнения и помещает неактивный поток в режим ожидания.
Процессоры ILP разные, их параллелизм - это уровень инструкций и, следовательно, в одном потоке выполнения, поэтому они не могут обмануть, удерживая основной поток. В настоящее время процессоры сочетают в себе два типа выполнения, но ILP по-прежнему является эксклюзивным для процессоров, и именно здесь они получают большое преимущество с точки зрения последовательного кода над полностью распараллеливаемым кодом.
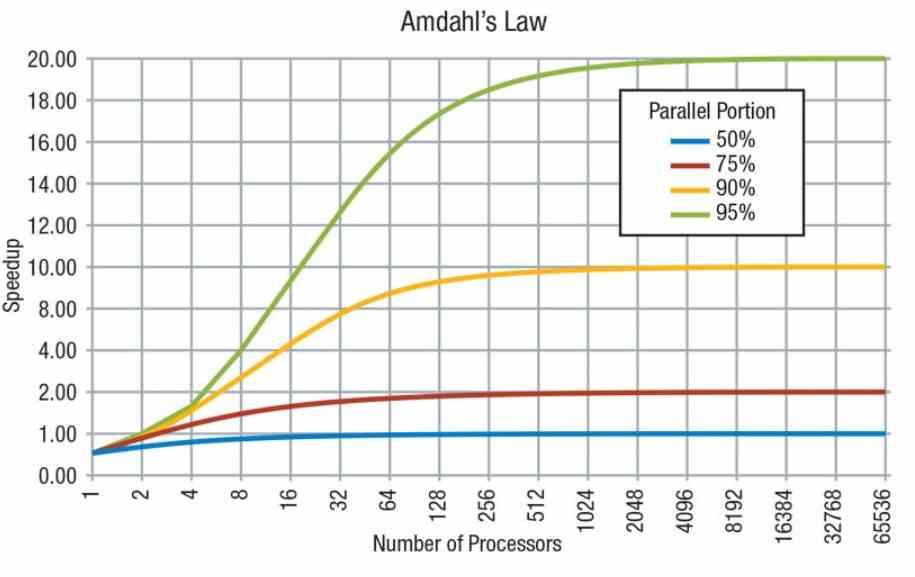
Мы не можем забыть, что согласно закону Амдала, код состоит из последовательно соединенных частей, которые могут выполняться только одним процессором, и параллельных частей, которые могут выполняться несколькими процессорами. Однако не все можно распараллелить, и есть последовательные части кода, которые требуют последовательной работы.
За последние 15 лет была разработана концепция, согласно которой параллельные алгоритмы выполняются на графических процессорах, ядра которых относятся к типу TLP, а последовательный код выполняется на процессорах типа ILP.
Выполнение инструкций по порядку
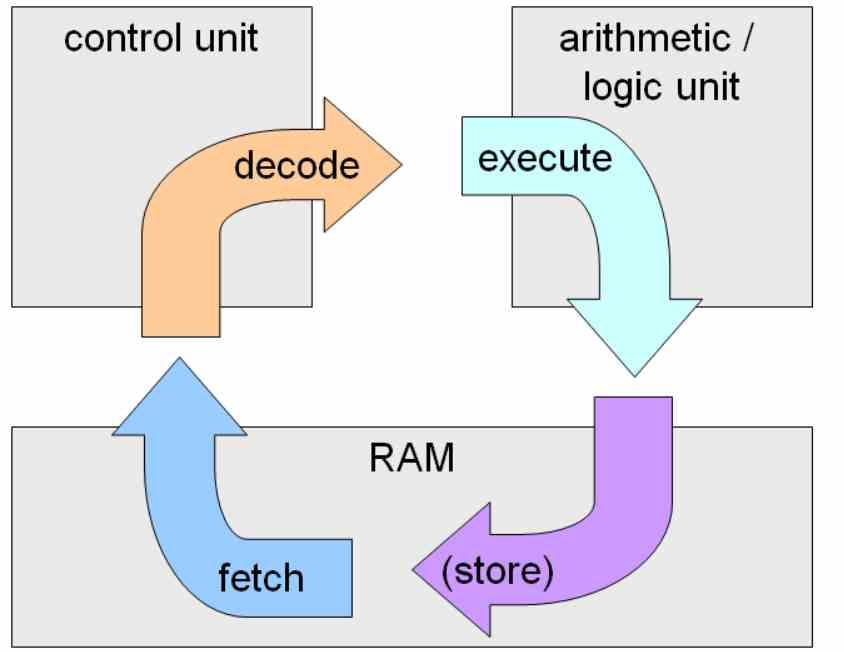
Выполнение по порядку - это классическое выполнение инструкций, его название связано с тем, что инструкции выполняются в том порядке, в котором они появляются в коде, и следующая инструкция не может продолжаться до тех пор, пока не будет разрешена предыдущая.
Наибольшая трудность выполнения по порядку связана с условными инструкциями и инструкциями перехода, поскольку они будут выполняться при возникновении условия, что значительно замедлит скорость выполнения кода. Это огромная проблема, когда количество этапов в процессоре чрезвычайно велико, что происходит, когда процессор работает на высоких тактовых частотах.
Ловушка для достижения высоких тактовых частот состоит в том, чтобы максимально сегментировать разрешение команд с большим количеством подэтапов цикла команд. Когда происходит скачок или ошибочное состояние, теряется значительное количество командных циклов.
Не в порядке, ускорение ILP

Нарушение порядка или неправильное выполнение - это способ, которым наиболее продвинутые процессоры выполняют код, и считается, что он позволяет избежать остановок выполнения. Как видно из названия, он состоит из выполнения инструкций процессора в порядке, отличном от указанного в коде.
Причина, по которой это делается, заключается в том, что каждому типу инструкции назначен тип исполнительной единицы. В зависимости от типа инструкции ЦП использует тот или иной тип исполнительного блока, но их количество ограничено. Это может вызвать остановку выполнения, поэтому все, что делается, - это продвижение следующей инструкции в ее выполнении, указывая на память или внутренний регистр, который является реальным порядком инструкций, после того, как они были выполнены, они отправляются обратно в исходный порядок, в котором они были в коде.
Использование вне очереди позволяет увеличить среднее количество инструкций, выполняемых за цикл, и приблизить его к идеальной производительности. Например, первый Intel Pentium имел упорядоченное выполнение и был ЦП, способным работать с двумя инструкциями, против 486, который мог работать только с одной, но, несмотря на это, его производительность из-за остановок была только на 40% больше.
Дополнительные этапы при выходе из строя
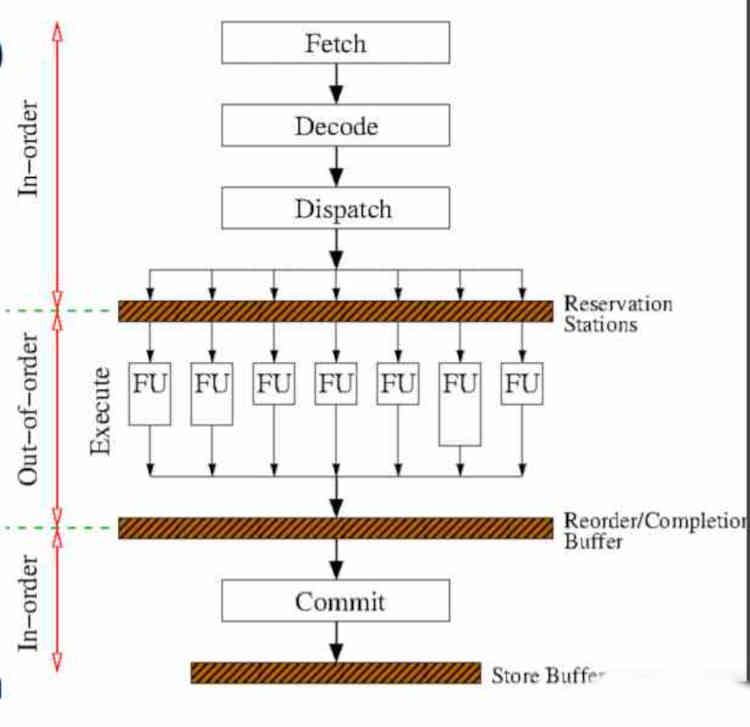
Реализация внеочередного исполнения добавляет дополнительные этапы в цикл инструкций, о которых мы уже говорили в статье под названием Вот как ваш процессор выполняет инструкции, данные программным обеспечением, который вы можете найти в HardZone.
Фактически, только центральная часть выполнения инструкции изменяется в отношении выполнения по порядку, эти изменения происходят до этапа выполнения, поэтому первые два, которые выполняются выборкой и декодированием, не затрагиваются, но два новых этапа являются добавлены, которые происходят до и после выполнения инструкций.
Первый этап - это резервные станции, на нем оборудование ожидает освобождения исполнительных модулей. Его реализация сложна, так как он основан на механизме, который не только наблюдает, когда исполнительный блок свободен, но также подсчитывает среднюю продолжительность в тактовых циклах каждой выполняемой инструкции, чтобы знать, как он должен переупорядочить инструкции.
Второй этап - это буфер переупорядочения, который отвечает за сортировку инструкций в порядке вывода. Имейте в виду, что для ускорения вывода инструкций при внеочередном исполнении выполняются все спекулятивные ветви инструкций в коде. Спекулятивная инструкция - это инструкция, которая выдается при условном переходе независимо от того, выполняется условие или нет. Таким образом, именно на этом этапе неподтвержденные ветви исполнения отбрасываются.