Инструкции AVX-512 - один из уникальных элементов Intelx86 ЦП архитектуры. Но что это за инструкции, связанные с их реализацией на процессорах Intel? Продолжайте читать, чтобы понять причину существования этих инструкций, какие у них есть варианты и почему они не используются AMD в своих процессорах.
Инструкции AVX были впервые реализованы в процессорах Intel, заменив старые инструкции SSE. С тех пор они стали стандартными инструкциями SIMD для процессоров x86 в двух вариантах, 128-битном и 256-битном, которые также были приняты AMD. С другой стороны, если говорить об инструкциях AVX-512, ситуация иная, и они используются только в процессорах Intel.

Что такое SIMD-модуль?
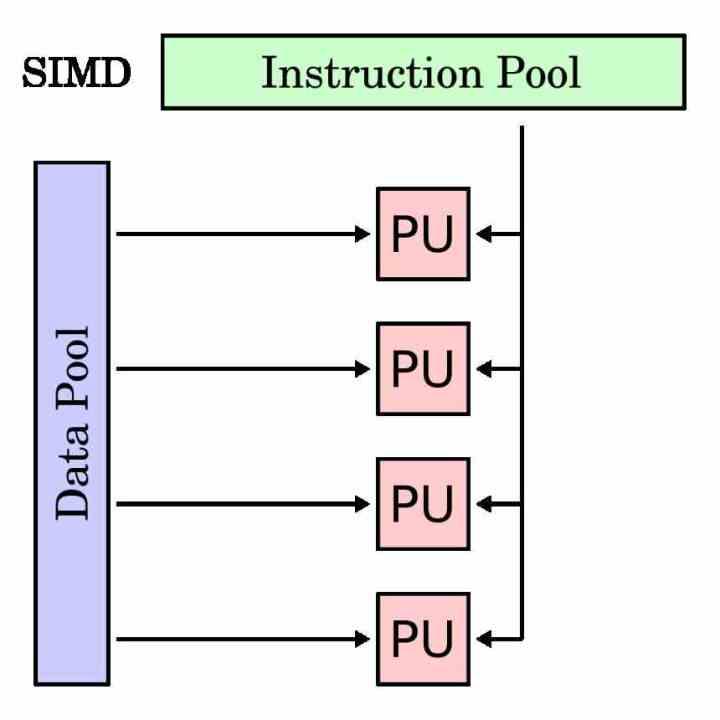
Модуль SIMD - это тип исполнительного модуля, который предназначен для одновременного выполнения одной и той же инструкции для нескольких данных. Следовательно, его регистр накопителя длиннее, чем у традиционной инструкции, поскольку он должен группировать различные данные, с которыми он должен работать с той же самой инструкцией.
Блоки SIMD традиционно использовались для ускорения так называемых мультимедийных процессов, в которых необходимо манипулировать различными данными в соответствии с одними и теми же инструкциями. Блоки SIMD позволяют распараллеливать выполнение программы в этих частях и ускорить время выполнения.
В каждом процессоре, чтобы отделить исполнительные блоки SIMD от традиционных, они имеют собственное подмножество инструкций, которое обычно является зеркалом скалярных инструкций или с одним операндом. Хотя есть случаи, которые невозможно сделать со скалярным модулем и они относятся исключительно к модулям SIMD.
История AVX-512

Инструкции AVX, Advanced Vector eXtensions, находятся внутри процессоров Intel в течение многих лет, но происхождение инструкций AVX-512 отличается от остальных. Причина? Его источником является проект Intel Larrabee, попытка Intel в конце 2000-х годов создать GPU : которые в конечном итоге стали ускорителями Xeon Phi. Серия процессоров, предназначенных для высокопроизводительных вычислений, выпущенная Intel несколько лет назад.
Архитектура Xeon Phi / Larrabee включает специальную версию инструкций AVX с размером регистра накопителя 512 бит, что означает, что они могут работать с 16 32-битными данными. Причина такой суммы связана с тем фактом, что типичное соотношение операций на тексель для графического процессора обычно составляет 16: 1. Не будем забывать, что инструкции AVX-512 взяты из неудачного проекта Larrabee и были перенесены оттуда в Xeon Phi.
По сей день Xeon Phi больше не существует, причина в том, что то же самое можно сделать с помощью традиционного графического процессора для вычислений. Это заставило Intel передать эти инструкции своей основной линейке процессоров.
Тарабарщина в виде инструкций AVX-512
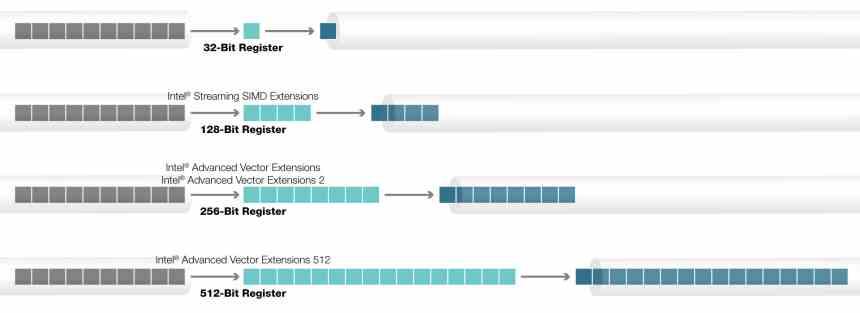
Инструкции AVX-512 не являются однородным блоком, который реализован на 100%, а скорее имеют различные расширения, которые, в зависимости от типа процессора, были добавлены или нет. Все процессоры называются AVX512F, но есть дополнительные инструкции, которые не являются частью исходного набора команд и которые Intel со временем добавила.
Расширения AVX512 следующие:
- AVX-512-CD: Обнаружение конфликтов, позволяет векторизовать циклы и, следовательно, векторизовать их. Впервые они были добавлены в Skylake-X или Skylake-SP.
- AVX-512-ER: Взаимные и экспоненциальные инструкции, которые предназначены для выполнения трансцендентных операций. Они были добавлены в серию Xeon Phi под названием Knights Landing.
- АВХ-512-ПФ: Еще одно включение в Knights Landing, на этот раз для повышения предупредительных или предпочтительных возможностей инструкций.
- AVX-512-BW: Инструкции байтового (8-битного) и уровня слов (16-битного) уровней. Это расширение позволяет работать с 8-битными и 16-битными данными.
- AVX-512-DQ: Добавьте новые инструкции с 32-битными и 64-битными данными.
- АВХ-512-ВЛ : Позволяет инструкциям AVX работать с регистрами накопителя XMM (128-бит) и YMM (256-бит)
- АВХ-512-ИФМА: Fused Multiply Add, которая в просторечии является инструкцией A * (B + C) с 52-битной целочисленной точностью.
- АВХ-512-ВБМИ: Инструкции по манипулированию вектором байтового уровня являются расширением AVX-512-BW.
- АВХ-512-ВННИ: Инструкции векторной нейронной сети - это серия инструкций, добавленных для ускорения алгоритмов глубокого обучения, используемых в приложениях, связанных с искусственным интеллектом.
Почему AMD еще не реализовала это на своих процессорах?

Причина этого очень проста: AMD стремится к комбинированному использованию своих ЦП и ГП при ускорении определенных типов приложений. Давайте не будем забывать происхождение AVX-512 в вышедшем из строя графическом процессоре от Intel и AMD. Благодаря своим графическим процессорам Radeon им не нужны инструкции AVX-512.
Вот почему инструкции AVX-512 являются эксклюзивными для процессоров Intel, не для полной исключительности, а потому, что AMD не заинтересована в использовании этого типа инструкций в своих ЦП, поскольку она намерена продавать свои графические процессоры, особенно недавно выпущенный AMD Instinct. высокопроизводительные вычисления с архитектурой CDNA.
Есть ли будущее у инструкций AVX-512?

Что ж, мы не знаем, это зависит от успеха Intel Xe, особенно Xe-HPC, который даст Intel архитектуру GPU на уровне AMD и NVIDIA. Это означает конфликт между инструкциями Intel Xe и AVX-512 для решения тех же проблем.
Проблема с AVX-512 заключается в том, что активация части процессора, которая его использует, в конечном итоге влияет на тактовую частоту процессора, снижая ее примерно на 25% в программе, которая использует эти инструкции в определенные моменты. Кроме того, его инструкции предназначены для высокопроизводительных вычислений и приложений искусственного интеллекта, которые не важны в том, что является домашним процессором, а появление специализированных блоков делает его пустой тратой транзисторов и пространства.
На самом деле ускорители или процессоры для конкретной области медленно заменяют блоки SIMD в ЦП, поскольку они могут делать то же самое, занимая меньше места и с незначительным энергопотреблением по сравнению.