
Графические процессоры, такие как процессоры, являются разновидностью процессоров, но они оптимизированы для параллельных вычислений и создания графики в реальном времени. Однако, несмотря на то, что у нас есть разные типы архитектур, каждый из графических процессоров имеет свою организацию и, следовательно, разделяет их. Что мы собираемся объяснить в этой статье подробно и подробно.
В этой статье мы не будем рассматривать конкретный GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР архитектура, но и их всех в целом, и поэтому, когда вы видите диаграмму, которую производители обычно запускают об организации своего следующего GPU, вы можете понять ее без проблем. Независимо от того, интегрированный это или выделенный графический процессор, и от степени мощности, которую они имеют.
Организация современный GPU

Чтобы понять, как устроен графический процессор, мы должны представить себе матрешку или матрешку, которая состоит из нескольких кукол внутри. Мы также могли бы говорить о наборе, сохраняющем серию подмножеств постепенно. Другими словами, графические процессоры организованы таким образом, что различные наборы, из которых они состоят, во многих случаях находятся друг в друге.
Благодаря этому разделению мы намного лучше поймем такую сложную вещь, как графический процессор, поскольку из простого мы можем построить сложное. С учетом сказанного, давайте начнем с первого компонента.
Набор A в организации графического процессора: шейдерные блоки
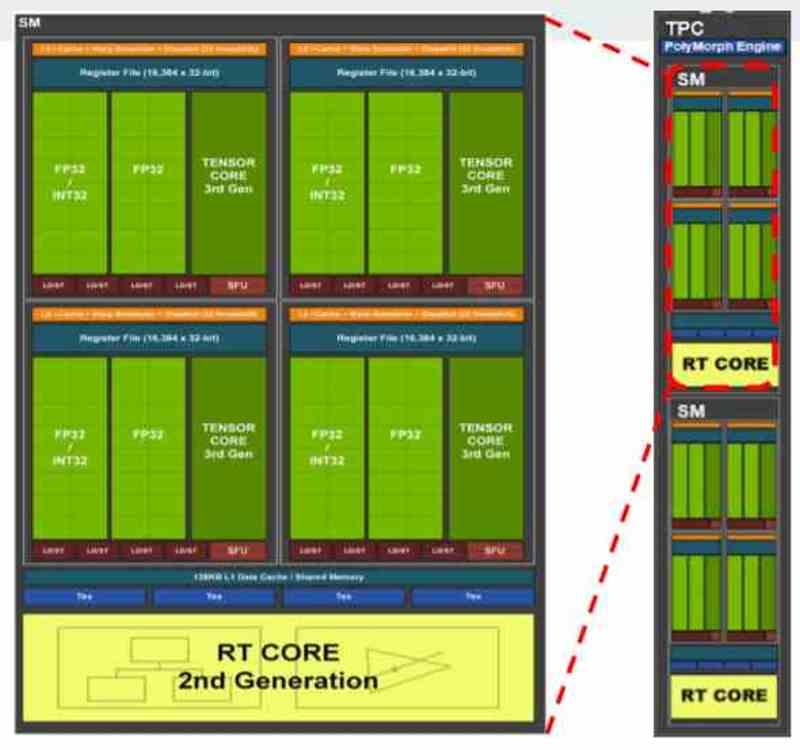
Первый из наборов - это шейдерные блоки. Сами по себе они являются процессорами, но, в отличие от процессоров, они предназначены не для параллелизма инструкций, ILP, а для потоков выполнения, TLP. Независимо от того, говорим ли мы о графических процессорах от AMD, NVIDIA, Intel или любой другой марки, все современные графические процессоры состоят из:
- SIMD-блоки и их записи
- Скалярные единицы и их регистры.
- Планировщик
- Общая локальная память
- Блок фильтрации текстур
- Первоклассный кеш данных и / или текстур
- Загрузка / хранение дисков для перемещения данных в кэш и общую память и из них.
- Блок пересечения молний.
- Систолические массивы или тензорные единицы
- Экспортная шина, которая экспортирует данные из набора A в различные компоненты набора B.
Набор B в организации ГПУ : Массив шейдеров / Механизм шейдеров / GPC
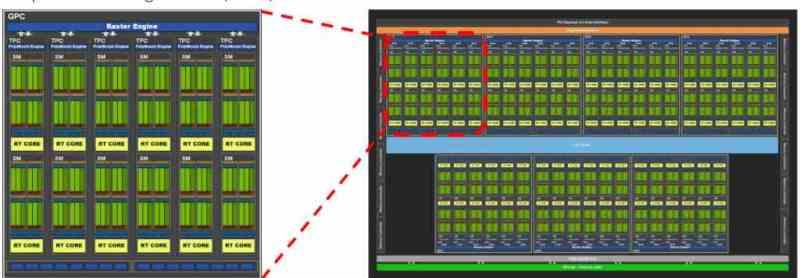
Набор B включает набор A внутри, но изначально добавляет кеши инструкций и констант. В графических процессорах, а также в процессорах, кэш первого уровня разделен на две части: одну для данных, а другую - для инструкций. Разница в том, что в случае графических процессоров кэш инструкций находится за пределами шейдерных блоков, и поэтому они находятся в наборе B.
Таким образом, набор B в организации графического процессора включает ряд шейдерных блоков, которые взаимодействуют друг с другом через общий интерфейс связи между ними, что позволяет им взаимодействовать друг с другом. С другой стороны, разные шейдерные блоки не единственные в Наборе B, поскольку именно здесь есть несколько фиксированных функциональных блоков для рендеринга графики, как сейчас.
- Примитивный блок: Он вызывается во время World Space Pipeline или Geometric Pipeline, он отвечает за тесселяцию геометрии сцены.
- Блок растеризации: It выполняет растеризацию примитивов, преобразуя треугольники в пиксельные фрагменты, и на его этапе начинается так называемый конвейер пространства экрана или этап растеризации.
- РОПС: Блоки, записывающие буферы изображений, действуют в два этапа. В фазе растра до фазы текстурирования они генерируют буфер глубины (Z-буфер), в то время как в фазе после фазы текстурирования они получают результат этого этапа для создания цветового буфера или различных целей рендеринга (отложенный рендеринг) .
Установить C в архитектуре GPU :
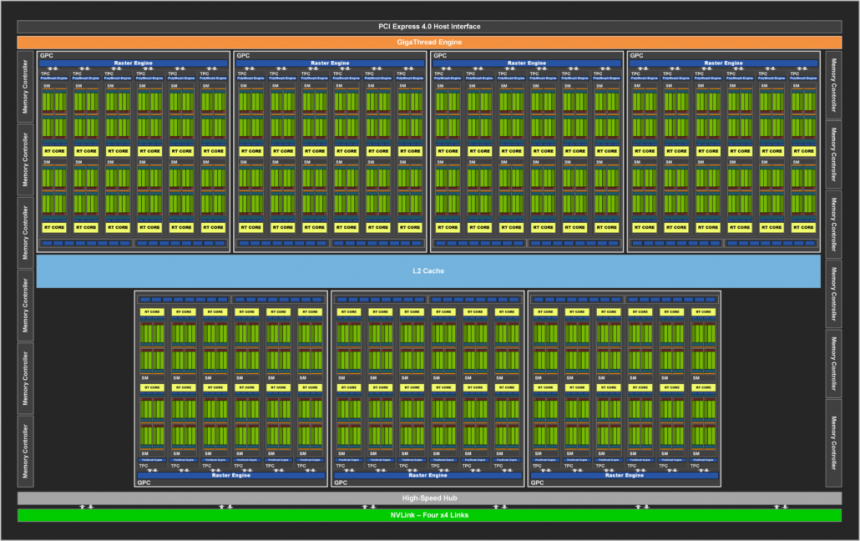
У нас уже есть почти полный GPU или GPU без ускорителей, он состоит из следующих компонентов:
- Несколько B-сетов внутри.
- Общая глобальная память : Электронный блокнот и, следовательно, вне иерархии кеша для обмена B-наборами друг с другом.
- Геометрическая единица: Он имеет возможность считывать указатели в ОЗУ, которые указывают на геометрию сцены, с помощью этого можно удалить невидимую или лишнюю геометрию, чтобы она не отображалась в кадре бесполезно.
- Командные процессоры (графика и вычисления)
- Кэш последнего уровня: Все элементы графического процессора являются клиентами этого кеша, поэтому у него должно быть огромное коммуникационное кольцо, все компоненты набора B имеют прямой контакт с кешем L2, а также все компоненты самого набора C.
Кэш последнего уровня (LLC) важен, поскольку это кеш, который дает нам согласованность между всеми элементами набора C друг с другом, включая, очевидно, наборы B. Более того, это позволяет не перегружать контроллер внешней памяти, поскольку при этом именно LLC вместе с блоком (ами) MMU графического процессора отвечают за захват инструкций и данных из Оперативная память. Кэш последнего уровня можно рассматривать как своего рода логистический склад, на котором все элементы набора C отправляют и / или получают свои посылки, а их логистика контролируется MMU, который отвечает за это.
Финальный набор, полный GPU

При всем этом у нас уже есть полный графический процессор, набор D включает основной блок, который является графическим процессором, отвечающим за рендеринг графики наших любимых игр, но это не самый высокий уровень графического процессора, поскольку нам не хватает серии сопроцессоров. служба поддержки. Они не работают для непосредственного рендеринга графики, но без них графический процессор не смог бы работать. Эти элементы обычно:
- Модуль GFX, включая его кэш верхнего уровня
- Северный мост или северный мост графического процессора, если это в гетерогенной SoC (с процессором), но с хорошо разделяемой памятью, тогда они будут использовать общий северный мост. Все элементы Set D подключены к северному мосту.
- Ускорители: Видеокодеры и адаптеры дисплея подключаются к северному мосту. В случае адаптера дисплея это тот, который отправляет видеосигнал на порт DisplayPort или HDMI.
- Диски DMA: Если имеется два адресных пространства ОЗУ (даже с одним и тем же физическим отсеком), диск DMA позволяет передавать данные из одного пространства ОЗУ в другое. В случае отдельного графического процессора блоки DMA служат для связи с центральным процессором или другими графическими процессорами.
- Контроллер и интерфейс памяти: It позволяет сообщать элементы Set D с внешней RAM. Они подключены к северному мосту, и это единственный путь к внешней оперативной памяти.
При всем этом у вас уже есть полная организация графического процессора, с которой вы можете гораздо лучше прочитать схему графического процессора и понять, как он организован внутри.