
One of the claims of NVIDIA regarding their RTX 3000 is that they have doubled the floating point power of their GPUs, which does not mean that the power and therefore the performance of the entire GPU has increased compared to the RTX 2000 all things being equal but only a part of the GPU, but it is best to give you an explanation of why without going into overly technical details and in such a way that even the most novice user can understand it.
According to NVIDIA, its new RTX 3000 Series are twice as powerful (in terms of floating point performance) compared to the RTX 3000, but the reality is that in games this does not mean that the performance has been doubled, and for To understand the reason why this happens we have to understand a series of premises to reach the conclusion that explains the reason for it.
What does NVIDIA mean by floating point performance? It is a type of numerical data, whose calculation speed is measured by a quantity called FLOPS, floating point operations per second, but which is at least misleading when comparing devices for the following reasons:
- Not all instructions resolve in the same number of clock cycles.
- Every processor, regardless of its nature, performs one or more operations in all cycles.
- Every instruction, equivalent, or equivalents are not resolved in all architectures in the same number of cycles.
That is, we can have two systems with 10 TFLOPS of power and one of them be faster than the other, since in the one that is more powerful, changes have been incorporated in the architecture that make that model perform much better than the other, even if they have the same floating point rate and even lower.
The RTX 3000 as an evolution of the RTX 2000
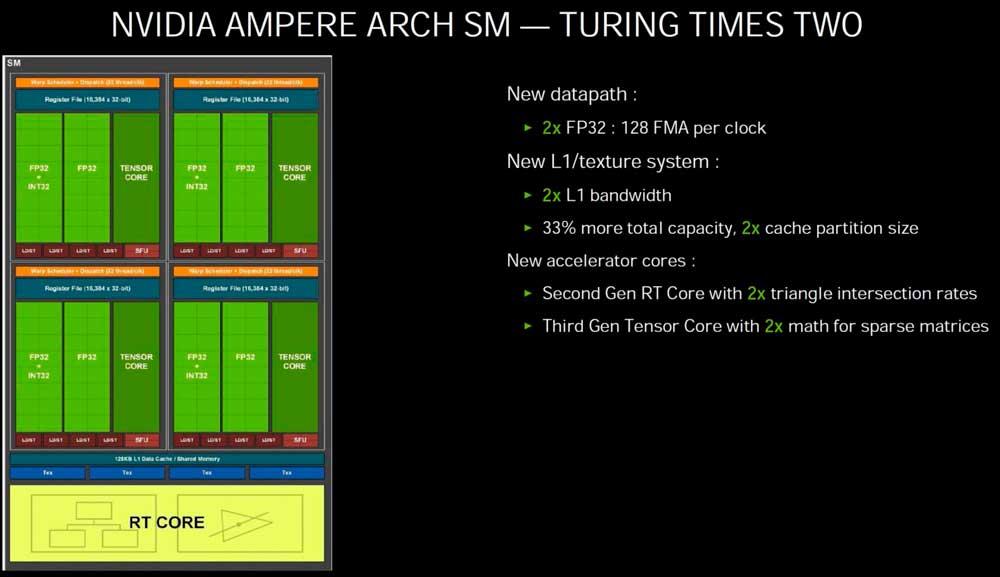
To get to the point we are interested in, we have to do a double zoom on the architecture, starting with the SM units of each of both architectures:
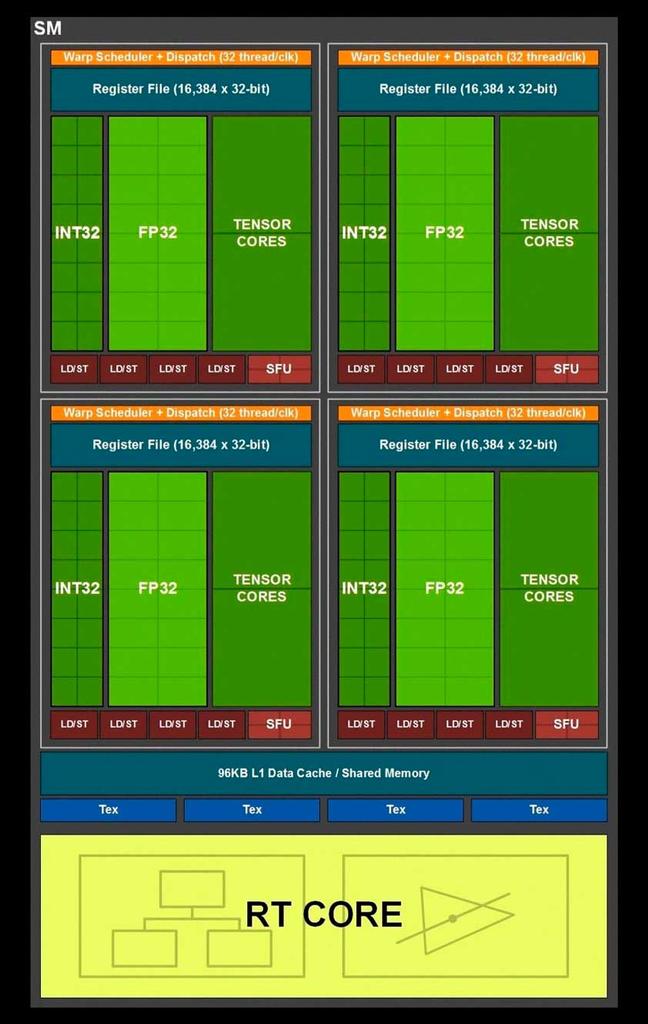
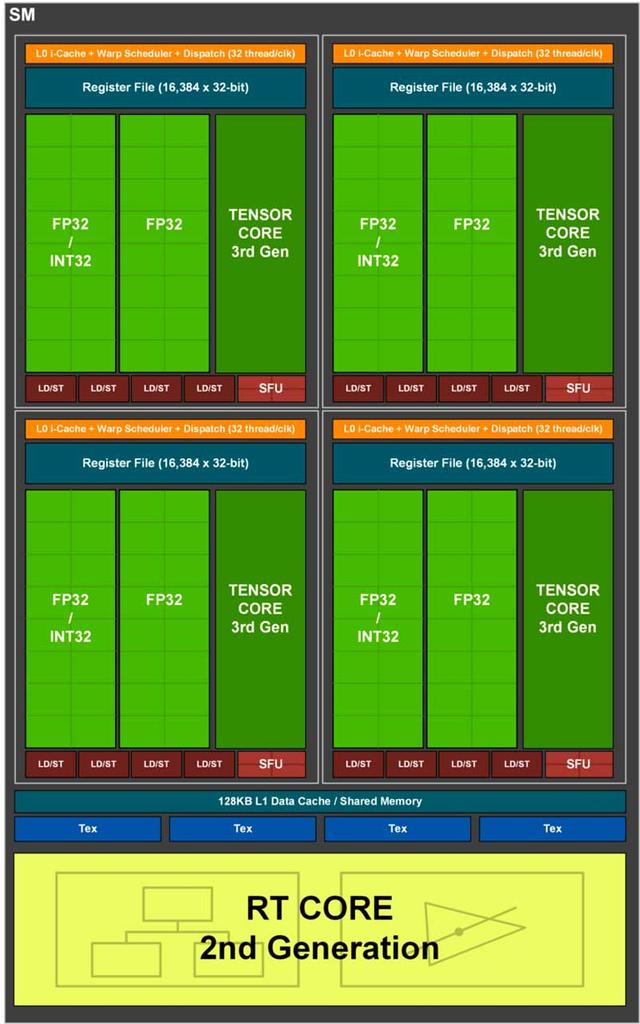
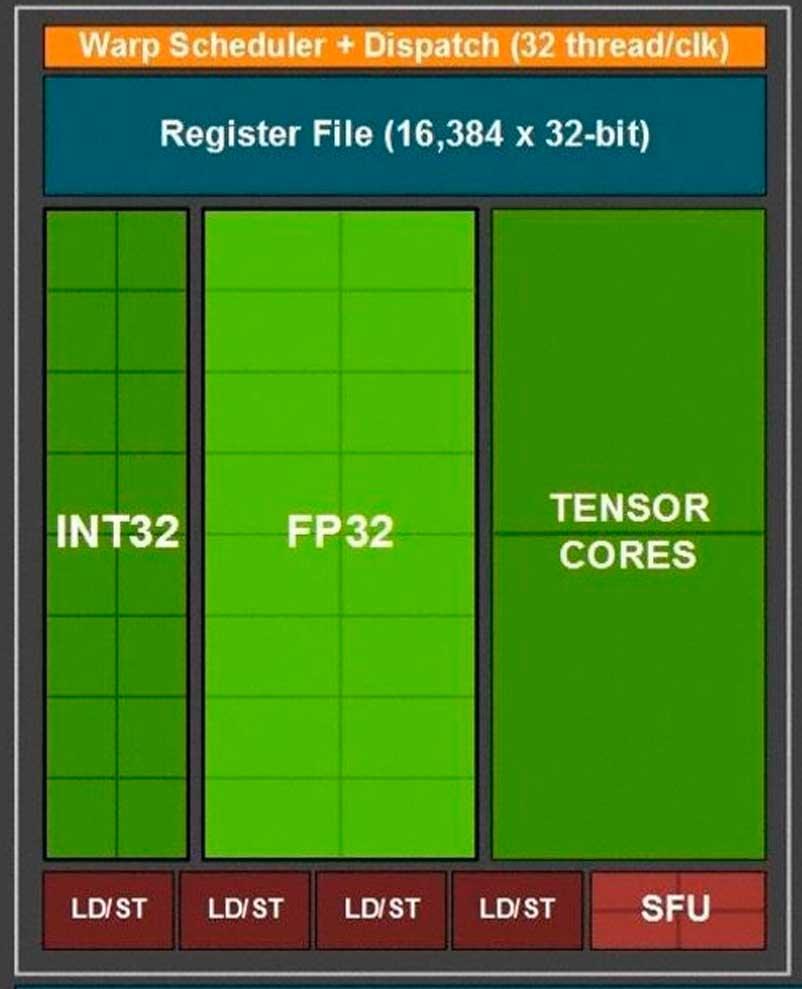
The part that interests us within the SM is the “subcore” of each architecture, since it will allow us to understand much better the changes in terms of performance in floating point that have occurred in the RTX 2000 with respect to the RTX 3000.
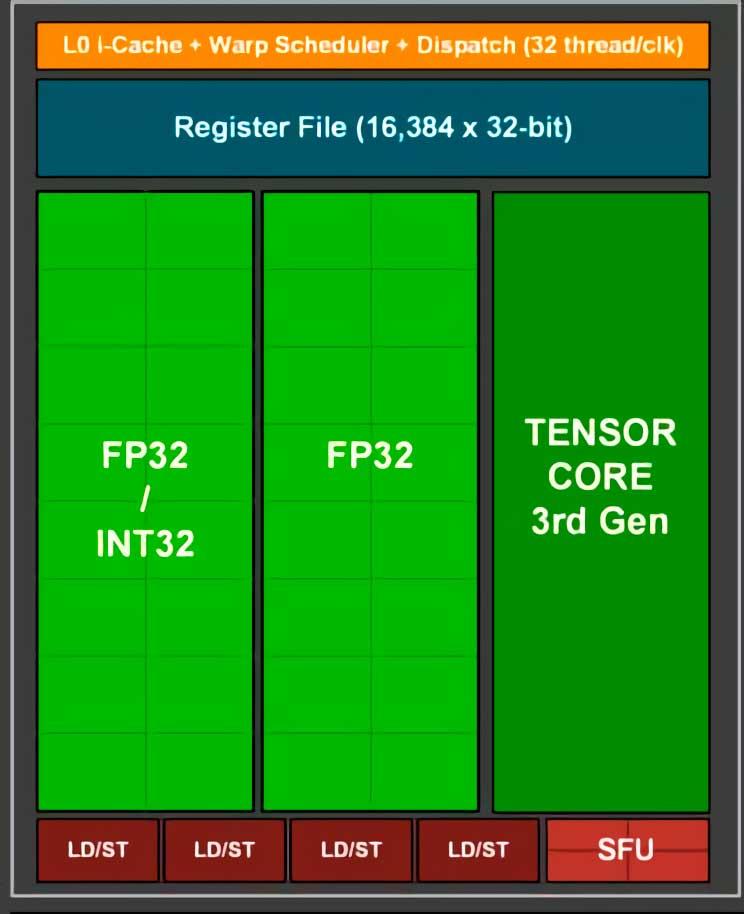
NVIDIA engineers, when designing the Ampere architecture of the RTX 3000, the light bulb was turned on and they decided to make a less interesting change in the “subcores” to increase the performance in floating point compared to its predecessor by modifying the fewer items possible.
Given that both Turing and Ampere subcores use the same warp scheduler and have the same number of registers, what they have done has been to take advantage of a small trap to be able to double the floating point power of each of the “subcores”. What is that trap? Well, what NVIDIA has done is add another 16 ALUs in 32-bit floating point.
In both Turing and Ampere we can have 16 Int32 ALUs and 16 FP32 ALUs active since the scheduler sends 32 threads to the registers that the corresponding ALUs will subsequently execute.
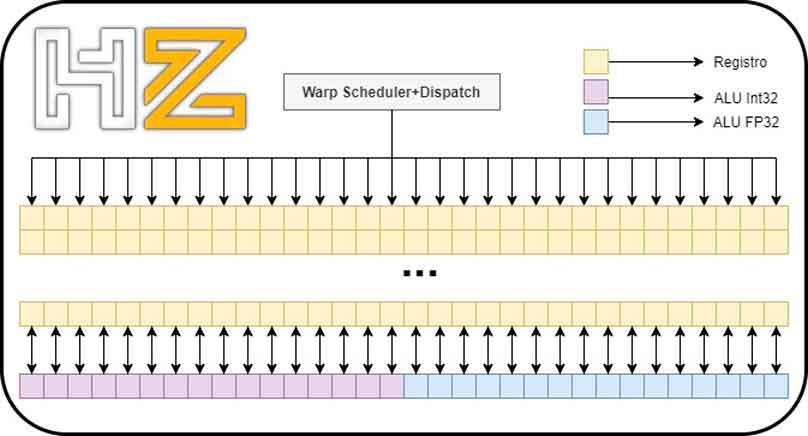
NVIDIA calls this concurrent execution, and it relies on making the integer and floating-point ALUs work together.
The problem in the RTX 2000 comes when we have a wave of 32 threads in floating point: the integer ALUs cannot execute that code so if we have a wave of that type it will need to be solved in two steps instead of one alone.
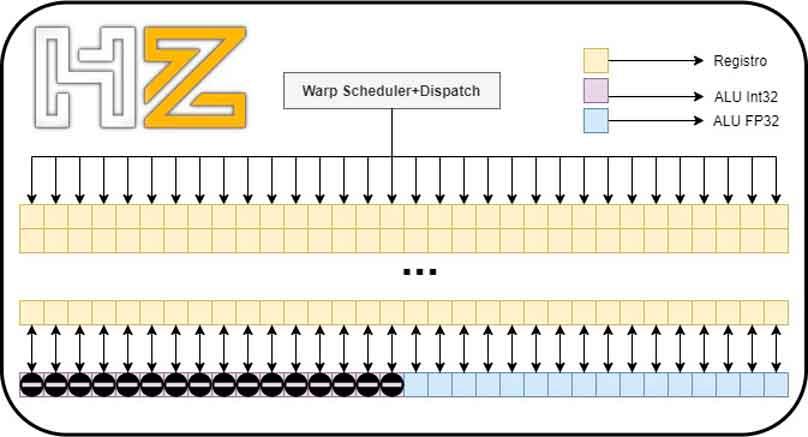
What NVIDIA has done in the Ampere architecture by doubling the ALUs in FP32 is that a wave of 32 floating-point threads can be resolved in half the time of Turing, thereby doubling the speed (in the sense that it takes only one cycle to solve it instead of two).
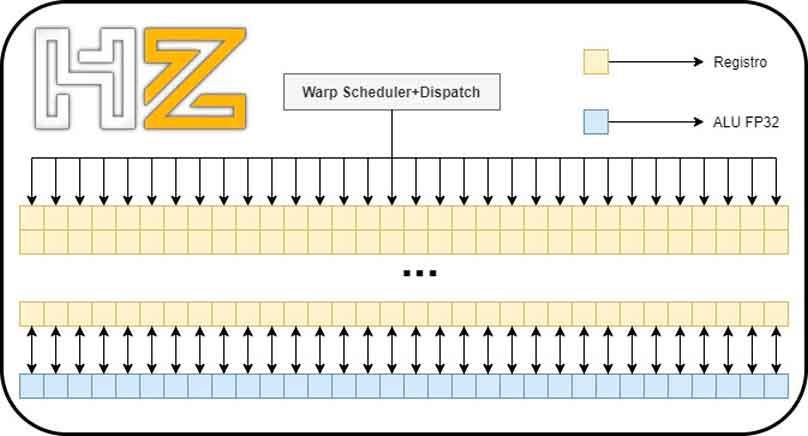
Thus, between integer and floating point concurrent mode there is no difference between the RTX 3000 and RTX 2000, and the floating point advantage on Ampere architecture graphics cards will only occur when they are running a wave of up to 32 floating point threads.
The technical specifications come from a context that does not match reality

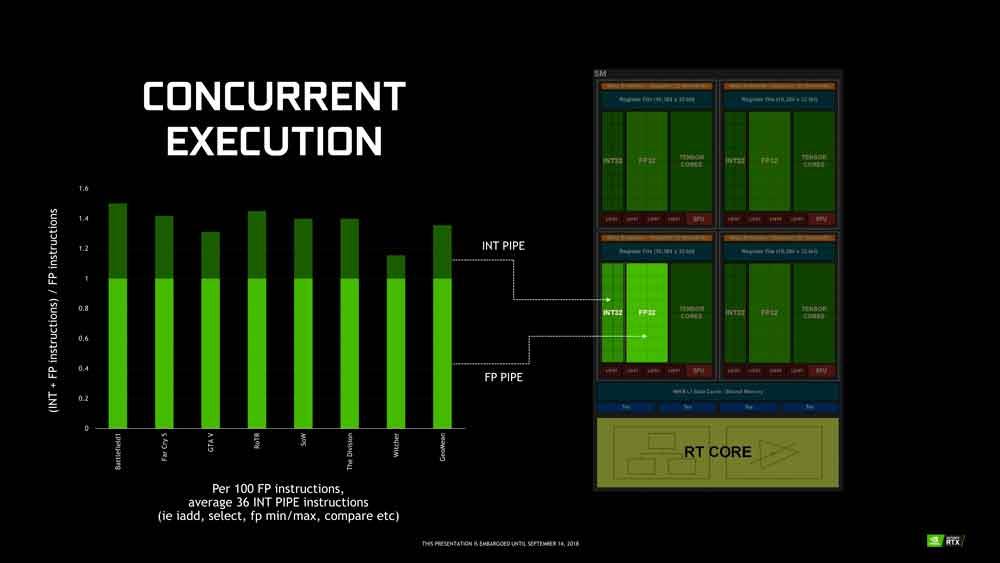
Once we have seen in which situations the RTX 3000 are twice as fast as the RTX 2000 we have to add another element to the equation and that is that when we talk about the FLOPS rate we are talking about a theoretical rate that does not occur in the real scenarios, and the problem with TFLOPS in GPUs is that the numbers that the manufacturers give are rates based on:
- The GPU executing the fastest type of instruction, that is, the one that takes the fewest cycles. The usual is to use the FMADD / FMA because it is an arithmetic instruction composed of an addition and a multiplication that is solved in the same cycle.
- The same instruction is always executed repetitively, there are no line breaks in the code or any other type of instruction.
- The data is in the registers, there is no data lookup in caches or VRAM memory, so this instruction is executed with the lowest possible latency.
It is as if we bought a sports car for its performance on a straight where it could accelerate unhindered to the limit. The reality is that the roads are much more complex than simple straight lines and the same happens with the graphic code of the games; This means that these impressive rates that all manufacturers give are never given and do not correlate with real scenarios.
So the NVIDIA RTX 3000 isn’t twice as powerful as the RTX 2000?

No, they are not and it is something that at this point in the article should have been clear to you. We have to understand that real-time 3D graphics follow a pipeline divided into several stages, in a good part of them the RTX 3000 will not be faster than an equivalent RTX 2000, but in others where the floating point power is important it will be when Ampere charts will take the lead and speed up execution in that part of the graph pipeline, although the performance increase will never be double.
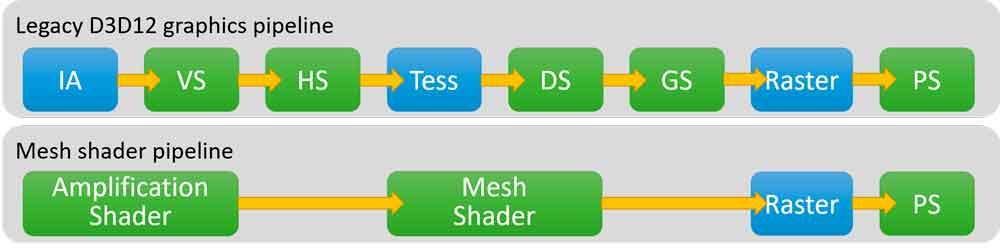
The pipeline is divided into parts that are executed by the SMs (Compute Units in AMD‘s jargon), the shader stages and are in green in the diagram, while the parts in blue are fixed function. These are executed by wired and unscheduled units and in this case there have been no improvements from the RTX 2000 to the RTX 3000 (except on the RT Core, but it is not part of the rasterization pipeline).
To better understand the situation, it is best to use a simile: imagine that we have two different cars, car A and car B that can go straight ahead at the same speed, but car B has the peculiarity of cornering twice as much faster than car A. Suppose we have tested them on a circuit divided into 7 segments: 4 straights and 3 corners.
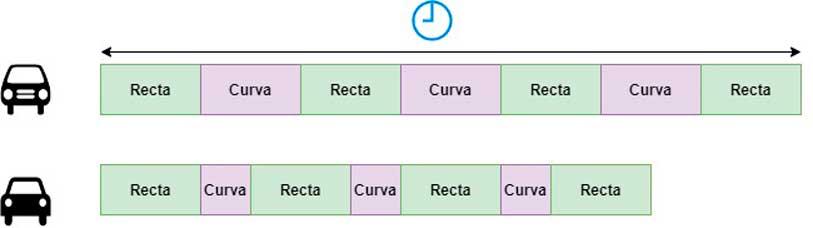
As you can see, car B will take less time to cover each lap of the circuit than its rival, and without being twice as fast it does take a considerable advantage by being faster in the corner. The same happens between the RTX 3000 and the RTX 2000, their performance will not always double, but it will be doubled in specific situations.
Where do the RTX 3000 have advantages over the RTX 2000?

Especially in everything that does not depend on fixed function units, such as the computational pipeline used today in post-processing effects and in the Ray Tracing stage of hybrid rendering. This is the reason why in applications like Quake 2 RTX the performance of the RTX 3000 is double that of the RTX 2000, due to the fact that it is a game that greatly exploits the execution in floating point and does not use the units of function at all. fixed rasterization.
With all this you can understand the reasons why the RTX 3000 despite doubling the FLOPS does not double the performance compared to its predecessor.